
Autor: fitchguo, ingeniero de desarrollo de fondo de Tencent IEG
La programación concurrente siempre ha sido uno de los temas a los que más atención prestan los desarrolladores. Como un lenguaje de programación con su propio halo de "alta concurrencia" desde su debut, el principio de implementación de programación concurrente de Golang es definitivamente digno de nuestra exploración en profundidad.
El modelo de programación concurrente de Go es compatible en la parte inferior con la biblioteca de subprocesos proporcionada por el sistema operativo. Aquí presentamos brevemente los conceptos relacionados con el modelo de implementación de subprocesos.
Modelo de implementación de subprocesos
Hay tres modelos principales de implementación de subprocesos: modelo de subprocesos a nivel de usuario, modelo de subprocesos a nivel de kernel y modelo de subprocesos de dos niveles. La mayor diferencia entre ellos radica en la correspondencia entre los subprocesos de usuario y las entidades de programación del kernel (KSE). Una entidad de programación del kernel es un objeto que puede programar el programador del kernel del sistema operativo, también conocido como subproceso a nivel del kernel, y es la unidad de programación más pequeña del kernel del sistema operativo.
Modelo de subprocesamiento a nivel de usuario
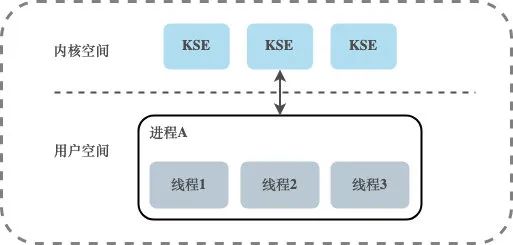
Existe una relación de mapeo de muchos a uno (N:1) entre los subprocesos de usuario y KSE. Los subprocesos bajo este modelo están completamente administrados por la biblioteca de subprocesos a nivel de usuario, que se almacena en el espacio de usuario del proceso. La existencia de estos subprocesos no es consciente del kernel, por lo que estos subprocesos no son los objetos programados por el programador del kernel. . Todos los subprocesos creados en un proceso solo se vinculan dinámicamente al mismo KSE en tiempo de ejecución, y toda la programación del kernel se basa en los procesos del usuario.
La programación de subprocesos se realiza a nivel de usuario. En comparación con la programación del kernel, no requiere que la CPU cambie entre el modo de usuario y el modo kernel. En comparación con el modelo de subprocesos a nivel del kernel, este método de implementación puede ser muy ligero. El consumo de los recursos del sistema será mucho menor, y el costo del cambio de contexto será mucho menor. Las bibliotecas de Coroutine implementadas en muchos idiomas básicamente entran en esta categoría. Sin embargo, los subprocesos múltiples bajo este modelo no pueden ejecutarse simultáneamente. Por ejemplo, si un subproceso se bloquea durante una operación de E/S, todos los subprocesos dentro de su propio proceso se bloquean y todo el proceso se suspende.
Modelo de subprocesamiento a nivel de kernel
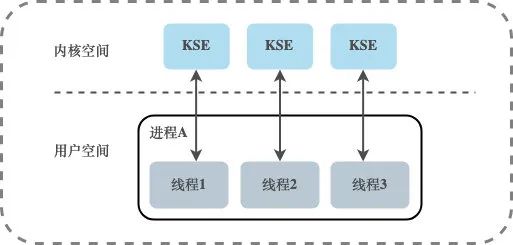
Existe una relación de mapeo uno a uno (1:1) entre los subprocesos de usuario y KSE. Los subprocesos bajo este modelo son administrados por el kernel, y la creación, finalización y sincronización de subprocesos de la aplicación deben completarse a través de llamadas al sistema proporcionadas por el kernel, y el kernel puede programar cada subproceso por separado. Por lo tanto, el modelo de subprocesos uno a uno realmente puede realizar la ejecución simultánea de subprocesos, y la mayoría de las bibliotecas de subprocesos implementadas por idiomas pertenecen básicamente a este método. Sin embargo, la creación, el cambio y la sincronización de subprocesos en este modelo requieren más recursos y tiempo del kernel.Si un proceso contiene una gran cantidad de subprocesos, causará una gran carga para el planificador del kernel e incluso afectará el rendimiento general del sistema operativo.
Modelo de roscado de dos niveles
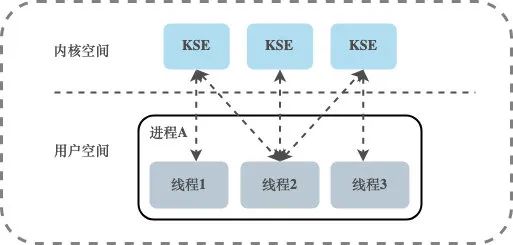
Existe una relación de mapeo de muchos a muchos (N:M) entre los subprocesos de usuario y KSE. El modelo de subprocesos de dos niveles absorbe las ventajas de los dos primeros modelos de subprocesos y evita sus desventajas tanto como sea posible.A diferencia del modelo de subprocesos a nivel de usuario, un proceso en el modelo de subprocesos de dos niveles se puede asociar con múltiples subprocesos del kernel KSE , es decir, un proceso dentro de un proceso. Múltiples subprocesos se pueden vincular a su propio KSE, que es similar al modelo de subprocesos a nivel de kernel; en segundo lugar, es diferente del modelo de subprocesos a nivel de kernel. Los subprocesos en su proceso son no está vinculado únicamente a KSE, pero puede haber varios subprocesos de usuario asignados al mismo KSE. Cuando el kernel programa un KSE fuera de la CPU debido a la operación de bloqueo de su subproceso vinculado, los subprocesos de usuario restantes en el proceso asociado pueden Vuelva a vincularse con otros KSE para ejecutarse. Por lo tanto, el modelo de subprocesos de dos niveles no es un modelo de subprocesos a nivel de usuario que está completamente programado por sí mismo ni un modelo de subprocesos a nivel de kernel que está completamente programado por el sistema operativo, sino un estado intermedio en el que su propia programación y la programación del sistema trabajar juntos, es decir, la programación del usuario El programador del núcleo implementa la programación desde el KSE a la CPU.
Concurrencia en Go
En el modelo de programación concurrente de Go, los flujos de control independientes que no son administrados por el kernel del sistema operativo no se denominan subprocesos de usuario o subprocesos, sino goroutines. Goroutine generalmente se considera como la implementación Go de coroutine. De hecho, Goroutine no es una corrutina en el sentido tradicional. La biblioteca de coroutine tradicional pertenece al modelo de subprocesos a nivel de usuario, mientras que la implementación subyacente de Goroutine combinada con el programador Go pertenece a el modelo de hilo de dos niveles.
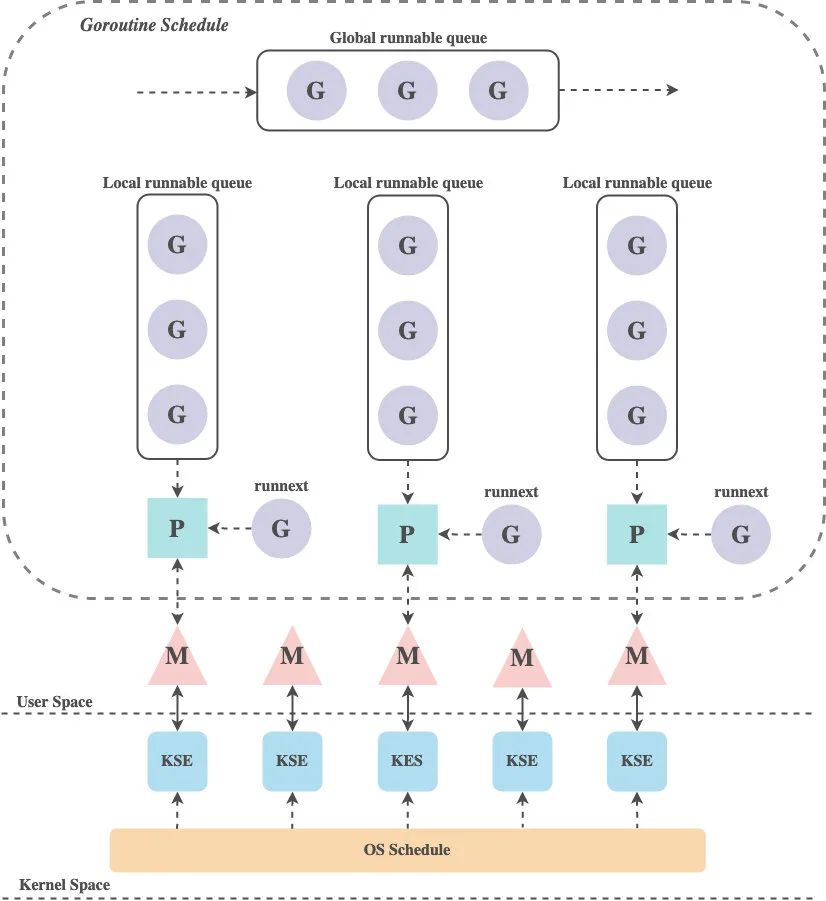
Go crea un modelo único de subprocesamiento de dos niveles. El programador Go implementa la programación de Goroutine a KSE, y el programador del kernel implementa la programación de KSE a la CPU. El programador de Go utiliza tres estructuras G, M y P para implementar la programación de Goroutine, también conocida como modelo GMP .
modelo GMP
G : Indica Gorutina. Cada Goroutine corresponde a una estructura G, y G almacena las funciones de tarea, estado y pila en ejecución de Goroutine, que se pueden reutilizar. Cuando la gorutina se transfiere desde la CPU, el código del planificador es responsable de guardar el valor del registro de la CPU en la variable miembro del objeto G, y cuando la gorutina está programada para ejecutarse, el código del planificador es responsable de guardar el registro almacenado. en la variable miembro del objeto G restaurar el valor al registro de la CPU
M : la abstracción del subproceso subyacente del sistema operativo, que a su vez está vinculado a un subproceso del kernel, y cada subproceso de trabajo tiene un objeto de instancia único de la estructura M correspondiente, que representa los recursos informáticos reales y está controlado por el sistema operativo Scheduler para programación y gestión. Además de registrar la información de estado del subproceso de trabajo, como la posición inicial y final de la pila, el Goroutine que se está ejecutando actualmente y si está inactivo, el objeto de estructura M también mantiene la relación vinculante con el objeto de instancia de la estructura P a través del puntero
P : Indica un procesador lógico. Para G, P es equivalente a un núcleo de CPU, y G solo se puede programar si está vinculado a P (en el runq local de P). Para M, P proporciona el entorno de ejecución relevante (Contexto), como el estado de asignación de memoria (mcache), la cola de tareas (G), etc. Mantiene una cola ejecutable local de Goroutine G. Los subprocesos de trabajo utilizan preferentemente sus propias colas de ejecución locales y acceden a la cola de ejecución global solo cuando es necesario. Esto puede reducir en gran medida los conflictos de bloqueo, mejorar la concurrencia de los subprocesos de trabajo y se puede utilizar bien. localidad de los programas
La ejecución de una G requiere el apoyo de P y M. Después de asociar una M con una P, se forma un entorno de ejecución de G eficaz (subproceso del núcleo + contexto). Cada P contiene una cola (runq) de G ejecutables. La G en la cola se pasará a la M asociada con la P local a su vez y obtendrá el tiempo de ejecución.
Siempre hay una correspondencia uno a uno entre M y KSE, y una M solo puede representar un subproceso del kernel. La asociación entre M y KSE es muy estable, durante su ciclo de vida, una M estará asociada con un solo KSE, y la asociación entre M y P, P y G es variable, y M y P también son uno a uno. relación, P y G son una relación de uno a muchos.
GRAMO
En tiempo de ejecución, G tiene el mismo estado en el planificador que los subprocesos en el sistema operativo, pero ocupa menos espacio en la memoria y reduce la sobrecarga del cambio de contexto. Es un subproceso proporcionado por el lenguaje Go en modo de usuario. Como una unidad de programación de recursos de grano más fino, si se usa correctamente, puede utilizar la CPU de la máquina de manera más eficiente en escenarios de alta concurrencia.
El código fuente de la parte de la estructura g (src/runtime/runtime2.go):
type g struct {
stack stack // Goroutine的栈内存范围[stack.lo, stack.hi)
stackguard0 uintptr // 用于调度器抢占式调度
m *m // Goroutine占用的线程
sched gobuf // Goroutine的调度相关数据
atomicstatus uint32 // Goroutine的状态
...
}
type gobuf struct {
sp uintptr // 栈指针
pc uintptr // 程序计数器
g guintptr // gobuf对应的Goroutine
ret sys.Uintewg // 系统调用的返回值
...
}
El contenido guardado en el gobuf se usa cuando el planificador guarda o restaura el contexto, donde el puntero de pila y el contador del programa se usan para almacenar o restaurar el valor en el registro, cambiando el código que el programa está a punto de ejecutar.
El campo atomicstatus almacena el estado de la gorutina actual. La gorutina puede estar en los siguientes estados:
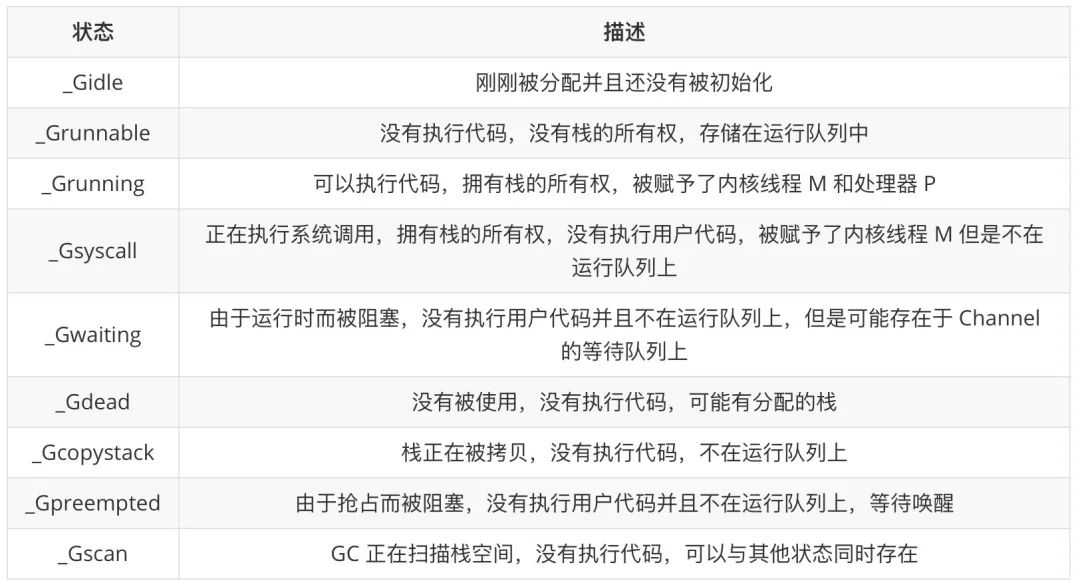
La transición de estado de rutina es un proceso muy complejo y hay muchas formas de desencadenar la transición de estado. Aquí presentamos principalmente cinco estados comunes _Grunnable, _Grunning, _Gsyscall, _Gwaiting y _Gpreempted.
Estos diferentes estados se pueden agregar en tres estados: esperando, ejecutable y en ejecución, alternando entre estos tres estados durante la operación:
-
En espera: Goroutine está esperando que se cumplan ciertas condiciones, como el final de las llamadas al sistema, etc., incluidos varios estados de _Gwaiting, _Gsyscall y _Gpreempted -
Runnable: las Goroutines están listas para ejecutarse en subprocesos. Si hay muchas Goroutines en el programa actual, cada Goroutine puede esperar más tiempo, es decir, _Grunnable -
En ejecución: Goroutine se ejecuta en un subproceso, es decir, _Grunning
G Diagrama de transición de estado común:
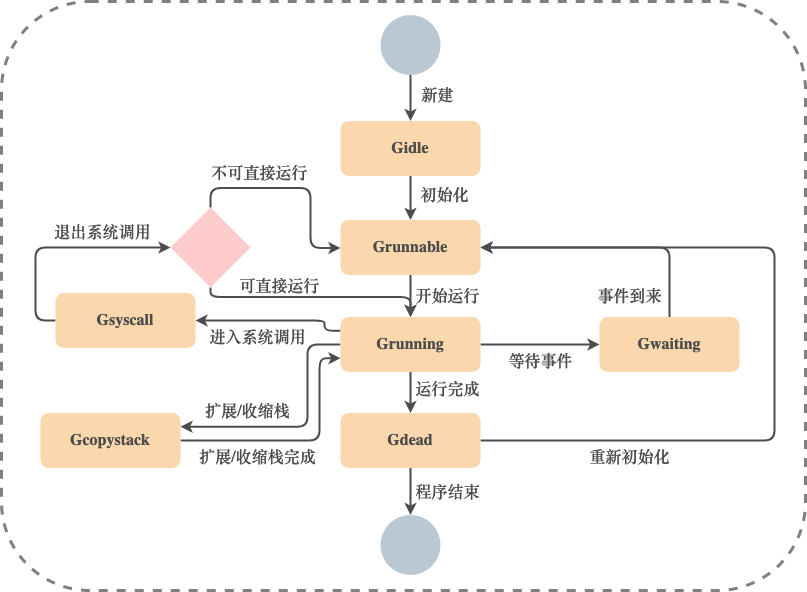
Una G que entra en un estado muerto se puede reinicializar y utilizar.
METRO
El modelo de concurrencia de M in Go es un subproceso del sistema operativo. El programador puede crear hasta 10 000 subprocesos, pero solo un máximo de GOMAXPROCS (el número de P) subprocesos activos puede ejecutarse normalmente. De manera predeterminada, el tiempo de ejecución establecerá GOMAXPROCS en la cantidad de núcleos en la máquina actual. También podemos usar runtime.GOMAXPROCS en el programa para cambiar la cantidad máxima de subprocesos activos.
Por ejemplo, para una máquina de cuatro núcleos, el tiempo de ejecución creará cuatro subprocesos activos del sistema operativo, cada uno de los cuales corresponde a una estructura runtime.m en el tiempo de ejecución. En la mayoría de los casos, usaremos la configuración predeterminada de Go, es decir, la cantidad de subprocesos es igual a la cantidad de CPU. La configuración predeterminada no activará con frecuencia la programación de subprocesos y el cambio de contexto del sistema operativo, y toda la programación ocurrirá. en modo de usuario El planificador se activa, lo que puede reducir una gran cantidad de gastos generales adicionales.
código fuente de la estructura m (parte):
type m struct {
g0 *g // 一个特殊的goroutine,执行一些运行时任务
gsignal *g // 处理signal的G
curg *g // 当前M正在运行的G的指针
p puintptr // 正在与当前M关联的P
nextp puintptr // 与当前M潜在关联的P
oldp puintptr // 执行系统调用之前使用线程的P
spinning bool // 当前M是否正在寻找可运行的G
lockedg *g // 与当前M锁定的G
}
g0 representa una Goroutine especial, creada por el sistema de tiempo de ejecución Go al inicio, y participa profundamente en el proceso de programación del tiempo de ejecución, incluida la creación de Goroutine, la asignación de gran cantidad de memoria y la ejecución de la función CGO. curg es la rutina de usuario que se ejecuta en el subproceso actual.
PAGS
El procesador P en el programador es la capa intermedia entre los hilos y las rutinas. Puede proporcionar el contexto requerido por el hilo y también es responsable de programar la cola de espera en el hilo. A través de la programación del procesador P, cada hilo del kernel puede ejecutar múltiples Goroutine, puede renunciar a los recursos informáticos a tiempo cuando Goroutine realiza algunas operaciones de E/S y mejorar la utilización de subprocesos.
El número de P es igual a GOMAXPROCS, y establecer el valor de GOMAXPROCS solo puede limitar el número máximo de P, y no hay restricción en el número de M y G. Cuando la G que se ejecuta en M ingresa a la llamada del sistema y hace que M se bloquee, el sistema de tiempo de ejecución separará la M de la P asociada con ella. En este momento, si todavía hay colas G sin ejecutar en la cola G ejecutable de la P, luego, el sistema encontrará una M inactiva en tiempo de ejecución, o creará una nueva M asociada con la P para satisfacer las necesidades de funcionamiento de estas G. Por lo tanto, el número de M suele ser mayor que el de P.
código fuente de la estructura p (parte):
type p struct {
// p 的状态
status uint32
// 对应关联的 M
m muintptr
// 可运行的Goroutine队列,可无锁访问
runqhead uint32
runqtail uint32
runq [256]guintptr
// 缓存可立即执行的G
runnext guintptr
// 可用的G列表,G状态等于Gdead
gFree struct {
gList
n int32
}
...
}
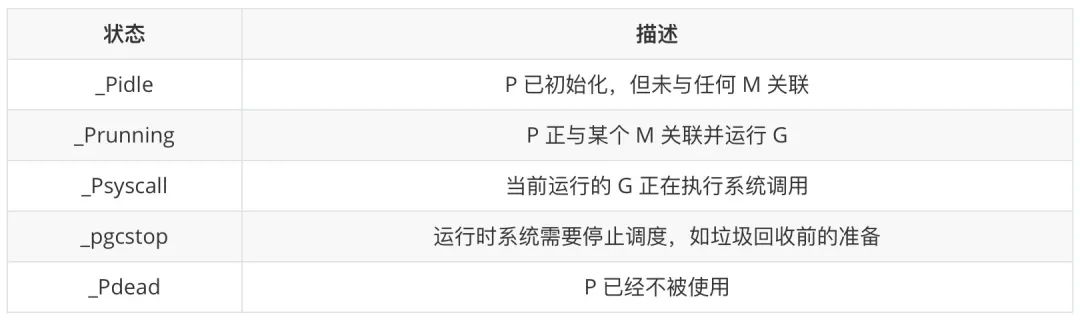
Los estados en los que P puede estar son los siguientes:
programador
Algunas de las tareas de programación en el modelo de subprocesos de dos niveles son realizadas por programas fuera del sistema operativo. En el lenguaje Go, el programador es responsable de esta parte de la programación de tareas. Los objetos principales de la programación son instancias de G, M y P. Cada M (es decir, cada subproceso del kernel) realizará algunas tareas de programación durante el proceso en ejecución, y juntos implementarán la función de programación del programador Go.
g0 y m0
Cada M en el sistema de tiempo de ejecución tendrá una G especial, comúnmente conocida como g0 de M. El g0 de M no lo genera indirectamente el código del programa Go, sino que el sistema de tiempo de ejecución de Go lo crea y lo asigna a M cuando se inicializa. El g0 de M generalmente se usa para realizar tareas como la programación, la recolección de elementos no utilizados y la administración de pilas. M también tendrá una G dedicada al procesamiento de señales, llamada gsignal.
A excepción de g0 y gsignal, otros G ejecutados por M pueden considerarse como G de nivel de usuario, denominados usuario G para abreviar, y g0 y gsignal pueden denominarse sistema G. El sistema de tiempo de ejecución de Go cambia para que cada M pueda ejecutar alternativamente al usuario G y su g0. Es por eso que "cada M ejecuta el programador" antes.
Además de que cada M tiene su propio g0, también hay un runtime.g0. runtime.g0 se utiliza para ejecutar el programa de arranque. Se ejecuta en el primer subproceso del kernel propiedad del programa Go. Este subproceso también se denomina runtime.m0. El g0 de runtime.m0 es runtime.g0.
Contenedor para elementos centrales
Los tres elementos centrales en el modelo de implementación de subprocesos de Go: G, M y P se han discutido anteriormente. Echemos un vistazo a los contenedores que contienen instancias de estos elementos:
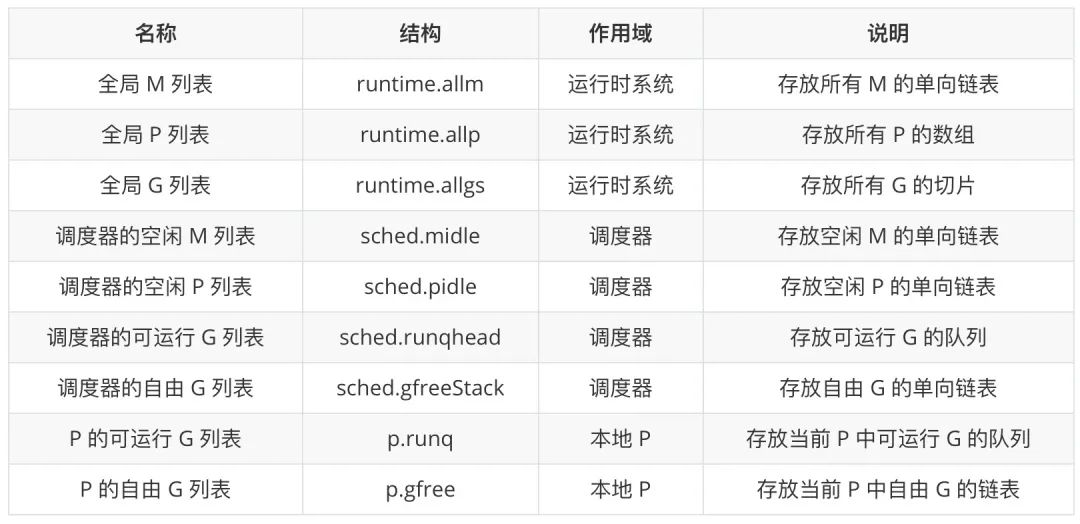
Especial atención merecen los cuatro contenedores relacionados con G. Cualquier G existirá en la lista global de G, y los cuatro contenedores restantes solo almacenarán G en el ámbito actual y con un estado determinado. Los G en las dos listas de G ejecutables tienen casi las mismas oportunidades para ejecutarse, excepto que la programación en diferentes momentos colocará a G en diferentes lugares. del p local Además, las dos colas G ejecutables también se transferirán G. Por ejemplo, cuando la cola G ejecutable del P local está llena, la mitad de las G se transferirán a la cola G ejecutable del planificador.
La lista M libre y la lista P libre del planificador se utilizan para almacenar instancias de elementos no utilizados temporalmente. Cuando el sistema de tiempo de ejecución lo necesita, obtiene una instancia del elemento correspondiente y lo vuelve a habilitar.
bucle de programación
Llame a runtime.schedule para ingresar al ciclo de programación:
func schedule() {
_g_ := getg()
top:
var gp *g
var inheritTime bool
if gp == nil {
// 为了公平,每调用schedule函数61次就要从全局可运行G队列中获取
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
// 从P本地获取G任务
if gp == nil {
gp, inheritTime = runqget(_g_.m.p.ptr())
}
// 运行到这里表示从本地运行队列和全局运行队列都没有找到需要运行的G
if gp == nil {
// 阻塞地查找可用G
gp, inheritTime = findrunnable()
}
// 执行G任务函数
execute(gp, inheritTime)
}
La función runtime.schedule busca gorutinas para ejecutar desde los siguientes lugares:
-
Para garantizar la equidad, cuando hay Goroutines para ejecutar en la cola de ejecución global, schedtick garantiza que existe una cierta probabilidad de que se busque el Goroutine correspondiente en la cola de ejecución global. -
Encuentre la gorutina que se ejecutará desde la cola de ejecución local al procesador -
Si los dos primeros métodos no encuentran G, utilizará la función findrunnable para "robar" algunos G de otros P para ejecutarlo. Si no puede "robar", bloqueará la búsqueda hasta que haya un G ejecutable.
Luego, el Goroutine adquirido es ejecutado por runtime.execute:
func execute(gp *g, inheritTime bool) {
_g_ := getg()
// 将G绑定到当前M上
_g_.m.curg = gp
gp.m = _g_.m
// 将g正式切换为_Grunning状态
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
// 抢占信号
gp.preempt = false
gp.stackguard0 = gp.stack.lo + _StackGuard
if !inheritTime {
// 调度器调度次数增加1
_g_.m.p.ptr().schedtick++
}
...
// gogo完成从g0到gp的切换
gogo(&gp.sched)
}
Al ejecutar ejecutar, G se cambiará al estado _Grunning, y M y G se vincularán, y finalmente se llamará a runtime.gogo para programar Goroutine en el subproceso actual. runtime.gogo tomará el contador de programa de runtime.goexit y el contador de programa de la función a ejecutar de runtime.gobuf, y hará lo siguiente:
-
El contador de programa de runtime.goexit se coloca en la pila SP -
El contador de programa de la función a ejecutar se coloca en el registro BX
MOVL gobuf_sp(BX), SP // 将runtime.goexit函数的PC恢复到SP中
MOVL gobuf_pc(BX), BX // 获取待执行函数的程序计数器
JMP BX // 开始执行
Cuando la función que se ejecuta en goroutine regrese, el programa saltará a la ubicación de runtime.goexit y finalmente llamará a la función runtime.goexit0 en la pila de g0 del subproceso actual, que convertirá goroutine al estado _Gdead y limpiará suba sus campos, elimine la asociación entre Goroutine y el subproceso y llame a runtime.gfput para volver a agregar G a la lista libre de Goroutine del procesador gFree:
func goexit0(gp *g) {
_g_ := getg()
// 设置当前G状态为_Gdead
casgstatus(gp, _Grunning, _Gdead)
// 清理G
gp.m = nil
...
gp.writebuf = nil
gp.waitreason = 0
gp.param = nil
gp.labels = nil
gp.timer = nil
// 解绑M和G
dropg()
...
// 将G扔进gfree链表中等待复用
gfput(_g_.m.p.ptr(), gp)
// 再次进行调度
schedule()
}
Finalmente, runtime.goexit0 llamará a runtime.schedule nuevamente para desencadenar una nueva ronda de programación de Goroutine. El programador comienza desde runtime.schedule y finalmente regresa a runtime.schedule, que es el bucle de programación del lenguaje Go.
Canal
Un patrón de diseño que se menciona a menudo en Go: no se comunique compartiendo la memoria, pero comparta la memoria mediante la comunicación. Goroutines pasan datos a través de canales.Como la estructura de datos central del lenguaje Go y el método de comunicación entre goroutines, el canal es una estructura importante que respalda el modelo de programación concurrente de alto rendimiento del lenguaje Go.
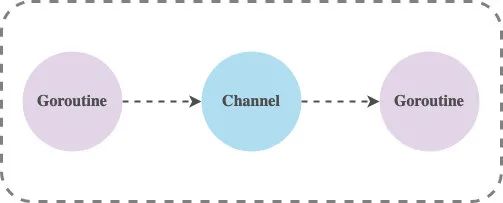
La representación interna del canal en tiempo de ejecución es runtime.hchan, que contiene bloqueos mutex para proteger las variables miembro.Hasta cierto punto, el canal es una cola bloqueada para sincronización y comunicación. código fuente de la estructura hchan:
type hchan struct {
qcount uint // 循环列表元素个数
dataqsiz uint // 循环队列的大小
buf unsafe.Pointer // 循环队列的指针
elemsize uint16 // chan中元素的大小
closed uint32 // 是否已close
elemtype *_type // chan中元素类型
sendx uint // chan的发送操作处理到的位置
recvx uint // chan的接收操作处理到的位置
recvq waitq // 等待接收数据的Goroutine列表
sendq waitq // 等待发送数据的Goroutine列表
lock mutex // 互斥锁
}
type waitq struct { // 双向链表
first *sudog
last *sudog
}
Conectado en waitq hay una lista doblemente enlazada de sudog, que guarda las Goroutines en espera.
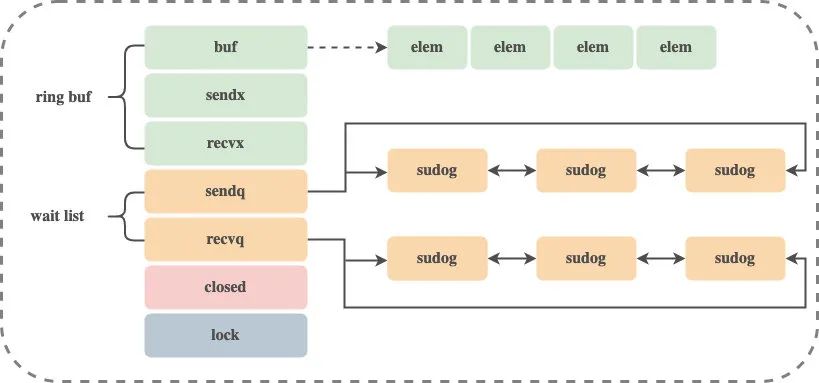
crear chan
Use la palabra clave make para crear una canalización, se llamará a make(chan int, 3) a la función runtime.makechan:
const (
maxAlign = 8
hchanSize = unsafe.Sizeof(hchan{}) + uintptr(-int(unsafe.Sizeof(hchan{}))&(maxAlign-1))
)
func makechan(t *chantype, size int) *hchan {
elem := t.elem
// 计算需要分配的buf空间大小
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
var c *hchan
switch {
case mem == 0:
// chan的大小或者elem的大小为0,不需要创建buf
c = (*hchan)(mallocgc(hchanSize, nil, true))
// Race detector uses this location for synchronization.
c.buf = c.raceaddr()
case elem.ptrdata == 0:
// elem不含指针,分配一块连续的内存给hchan数据结构和buf
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// elem包含指针,单独分配buf
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
// 更新hchan的elemsize、elemtype、dataqsiz字段
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
return c
}
El código anterior inicializa runtime.hchan y el búfer según el tipo de elementos de envío y recepción en el canal y el tamaño del búfer:
-
Si el tamaño requerido del búfer es 0, solo se asignará una sección de memoria para hchan -
Si el tamaño requerido del búfer no es 0 y elem no contiene un puntero, se asignará una parte de memoria contigua para hchan y buf -
Si el tamaño requerido del búfer no es 0 y elem contiene un puntero, la memoria se asigna para hchan y buf por separado.
enviar datos a chan
Para enviar datos a un canal, ch <- llamaré a la función runtime.chansend, que contiene toda la lógica para enviar datos:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
if c == nil {
// 对于非阻塞的发送,直接返回
if !block {
return false
}
// 对于阻塞的通道,将goroutine挂起
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
// 加锁
lock(&c.lock)
// channel已关闭,panic
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
...
}
bloque Indica si la operación de envío actual es una llamada de bloqueo. Si el canal está vacío, para el envío sin bloqueo, devuelva falso directamente, para el envío de bloqueo, suspenda la gorutina y nunca regrese. Bloquee el canal para evitar que múltiples subprocesos modifiquen datos al mismo tiempo. Si el canal está cerrado, se informa un error y el programa se cancela.
El proceso de ejecución de la función runtime.chansend se puede dividir en las siguientes tres partes:
-
Cuando hay receptores en espera, envíe datos directamente al receptor bloqueado a través de runtime.send -
Cuando haya espacio libre en el búfer, escriba los datos enviados en el búfer -
Cuando no existe un búfer o el búfer está lleno, espere a que otras rutinas reciban datos del canal
enviar directamente
Si el canal de destino no está cerrado y la cola recvq ya tiene una Goroutine esperando para leer, entonces runtime.chansend sacará la primera Goroutine en espera de la cola receptora recvq y le enviará datos directamente. Tenga en cuenta que debido a que hay receptores esperando, entonces, si hay un búfer, el búfer debe estar vacío:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
...
// 从recvq中取出一个接收者
if sg := c.recvq.dequeue(); sg != nil {
// 如果接收者存在,直接向该接收者发送数据,绕过buf
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
...
}
Enviar directamente llamará a la función runtime.send:
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
...
if sg.elem != nil {
// 直接把要发送的数据copy到接收者的栈空间
sendDirect(c.elemtype, sg, ep)
sg.elem = nil
}
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
// 设置对应的goroutine为可运行状态
goready(gp, skip+1)
}
El método sendDirect llama a memmove para hacer una copia de memoria de los datos. El método goready marca la gorutina que espera recibir datos como un estado ejecutable (Grunnable) y envía la gorutina al runnext del procesador donde se encuentra el remitente para esperar la ejecución. El procesador despertará inmediatamente al receptor de datos en la próxima programación. . Tenga en cuenta que solo se coloca en runnext y Goroutine no se ejecuta inmediatamente.
enviar al búfer
Si el búfer no está lleno, escriba datos en el búfer:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
...
// 如果缓冲区没有满,直接将要发送的数据复制到缓冲区
if c.qcount < c.dataqsiz {
// 找到buf要填充数据的索引位置
qp := chanbuf(c, c.sendx)
...
// 将数据拷贝到buf中
typedmemmove(c.elemtype, qp, ep)
// 数据索引前移,如果到了末尾,又从0开始
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
// 元素个数加1,释放锁并返回
c.qcount++
unlock(&c.lock)
return true
}
...
}
Encuentre la posición de índice del búfer para llenar con datos, llame al método typedmemmove para copiar los datos en el búfer y luego restablezca el desplazamiento de sendx.
bloqueo de envío
当 channel 没有接收者能够处理数据时,向 channel 发送数据会被下游阻塞,使用 select 关键字可以向 channel 非阻塞地发送消息:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
...
// 缓冲区没有空间了,对于非阻塞调用直接返回
if !block {
unlock(&c.lock)
return false
}
// 创建sudog对象
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep
mysg.waitlink = nil
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.waiting = mysg
gp.param = nil
// 将sudog对象入队
c.sendq.enqueue(mysg)
// 进入等待状态
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceEvGoBlockSend, 2)
...
}
对于非阻塞的调用会直接返回,对于阻塞的调用会创建 sudog 对象并将 sudog 对象加入发送等待队列。调用 gopark 将当前 Goroutine 转入 waiting 状态。调用 gopark 之后,在使用者看来向该 channel 发送数据的代码语句会被阻塞。
发送数据整个流程大致如下:
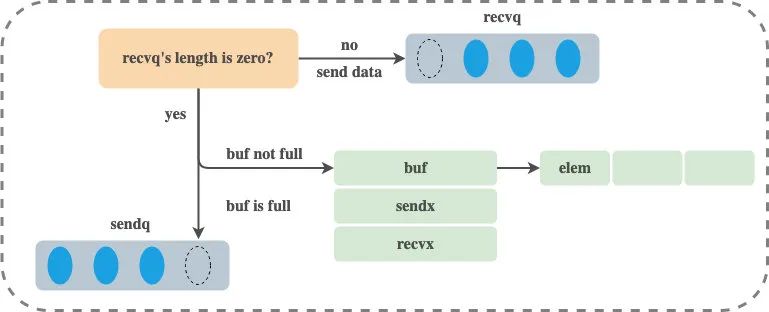
注意,发送数据的过程中包含几个会触发 Goroutine 调度的时机:
-
发送数据时发现从 channel 上存在等待接收数据的 Goroutine,立刻设置处理器的 runnext 属性,但是并不会立刻触发调度 -
发送数据时并没有找到接收方并且缓冲区已经满了,这时会将自己加入 channel 的 sendq 队列并调用 gopark 触发 Goroutine 的调度让出处理器的使用权
从 chan 接收数据
从 channel 获取数据最终调用到 runtime.chanrecv 函数:
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
if c == nil {
// 如果c为空且是非阻塞调用,直接返回
if !block {
return
}
// 阻塞调用直接等待
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
throw("unreachable")
}
···
lock(&c.lock)
// 如果c已经关闭,并且c中没有数据,返回
if c.closed != 0 && c.qcount == 0 {
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
···
}
当从一个空 channel 接收数据时,直接调用 gopark 让出处理器使用权。如果当前 channel 已被关闭且缓冲区中没有数据,直接返回。
runtime.chanrecv 函数的具体执行过程可以分为以下三个部分:
-
当存在等待的发送者时,通过 runtime.recv 从阻塞的发送者或者缓冲区中获取数据 -
当缓冲区存在数据时,从 channel 的缓冲区中接收数据 -
当缓冲区中不存在数据时,等待其他 Goroutine 向 channel 发送数据
直接接收
当 channel 的 sendq 队列中包含处于发送等待状态的 Goroutine 时,调用 runtime.recv 直接从这个发送者那里提取数据。注意,由于有发送者在等待,所以如果有缓冲区,那么缓冲区一定是满的。
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
...
// 从发送者队列获取数据
if sg := c.sendq.dequeue(); sg != nil {
// 发送者队列不为空,直接从发送者那里提取数据
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
...
}
主要看一下 runtime.recv 的实现:
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
// 如果是无缓冲区chan
if c.dataqsiz == 0 {
if ep != nil {
// 直接从发送者拷贝数据
recvDirect(c.elemtype, sg, ep)
}
// 有缓冲区chan
} else {
// 获取buf的存放数据指针
qp := chanbuf(c, c.recvx)
// 直接从缓冲区拷贝数据给接收者
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
// 从发送者拷贝数据到缓冲区
typedmemmove(c.elemtype, qp, sg.elem)
c.recvx++
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
gp := sg.g
gp.param = unsafe.Pointer(sg)
// 设置对应的goroutine为可运行状态
goready(gp, skip+1)
}
该函数会根据缓冲区的大小分别处理不同的情况:
-
如果 channel 不存在缓冲区 -
直接从发送者那里提取数据 -
如果 channel 存在缓冲区 -
将缓冲区中的数据拷贝到接收方的内存地址 -
将发送者数据拷贝到缓冲区,并唤醒发送者
无论发生哪种情况,运行时都会调用 goready 将等待发送数据的 Goroutine 标记成可运行状态(Grunnable)并将当前处理器的 runnext 设置成发送数据的 Goroutine,在调度器下一次调度时将阻塞的发送方唤醒。
从缓冲区接收
如果 channel 缓冲区中有数据且发送者队列中没有等待发送的 Goroutine 时,直接从缓冲区中 recvx 的索引位置取出数据:
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
...
// 如果缓冲区中有数据
if c.qcount > 0 {
qp := chanbuf(c, c.recvx)
// 从缓冲区复制数据到ep
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
// 接收数据的指针前移
c.recvx++
// 环形队列,如果到了末尾,再从0开始
if c.recvx == c.dataqsiz {
c.recvx = 0
}
// 缓冲区中现存数据减一
c.qcount--
unlock(&c.lock)
return true, true
}
...
}
阻塞接收
当 channel 的发送队列中不存在等待的 Goroutine 并且缓冲区中也不存在任何数据时,从管道中接收数据的操作会被阻塞,使用 select 关键字可以非阻塞地接收消息:
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
...
// 非阻塞,直接返回
if !block {
unlock(&c.lock)
return false, false
}
// 创建sudog
gp := getg()
mysg := acquireSudog()
···
gp.waiting = mysg
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.param = nil
// 将sudog添加到等待接收队列中
c.recvq.enqueue(mysg)
// 阻塞Goroutine,等待被唤醒
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanReceive, traceEvGoBlockRecv, 2)
...
}
如果是非阻塞调用,直接返回。阻塞调用会将当前 Goroutine 封装成 sudog,然后将 sudog 添加到等待接收队列中,调用 gopark 让出处理器的使用权并等待调度器的调度。
注意,接收数据的过程中包含几个会触发 Goroutine 调度的时机:
-
当 channel 为空时 -
当 channel 的缓冲区中不存在数据并且 sendq 中也不存在等待的发送者时
关闭 chan
关闭通道会调用到 runtime.closechan 方法:
func closechan(c *hchan) {
// 校验逻辑
...
lock(&c.lock)
// 设置chan已关闭
c.closed = 1
var glist gList
// 获取所有接收者
for {
sg := c.recvq.dequeue()
if sg == nil {
break
}
if sg.elem != nil {
typedmemclr(c.elemtype, sg.elem)
sg.elem = nil
}
gp := sg.g
gp.param = nil
glist.push(gp)
}
// 获取所有发送者
for {
sg := c.sendq.dequeue()
...
}
unlock(&c.lock)
// 唤醒所有glist中的goroutine
for !glist.empty() {
gp := glist.pop()
gp.schedlink = 0
goready(gp, 3)
}
}
将 recvq 和 sendq 两个队列中的 Goroutine 加入到 gList 中,并清除所有 sudog 上未被处理的元素。最后将所有 glist 中的 Goroutine 加入调度队列,等待被唤醒。注意,发送者在被唤醒之后会 panic。
总结一下发送/接收/关闭操作可能引发的结果:
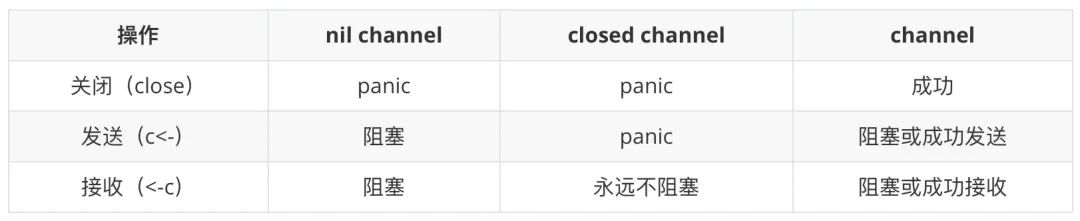
Goroutine 和 channel 的实现共同支撑起了 Go 语言的并发机制。
近期好文:
