
Enlace original: http://33h.co/kyq4z
Parte 1 Optimización del rendimiento de Linux
1optimización del rendimiento
Actuación
La alta concurrencia y la respuesta rápida corresponden a los dos indicadores principales de la optimización del rendimiento: rendimiento y latencia

-
Perspectiva de carga de la aplicación : afecta directamente la experiencia del usuario del terminal del producto -
Perspectiva de recursos del sistema : uso de recursos, saturación, etc.
La esencia del problema de rendimiento es que los recursos del sistema han llegado al cuello de botella, pero el procesamiento de solicitudes no es lo suficientemente rápido para admitir más solicitudes. El análisis de rendimiento consiste en realidad en descubrir los cuellos de botella de la aplicación o sistema y tratar de evitarlos o aliviarlos.
-
Seleccionar métricas para evaluar el rendimiento de la aplicación y el sistema -
Establecer objetivos de rendimiento para aplicaciones y sistemas -
Hacer puntos de referencia de rendimiento -
Análisis de rendimiento para localizar cuellos de botella -
Monitoreo de rendimiento y alertas
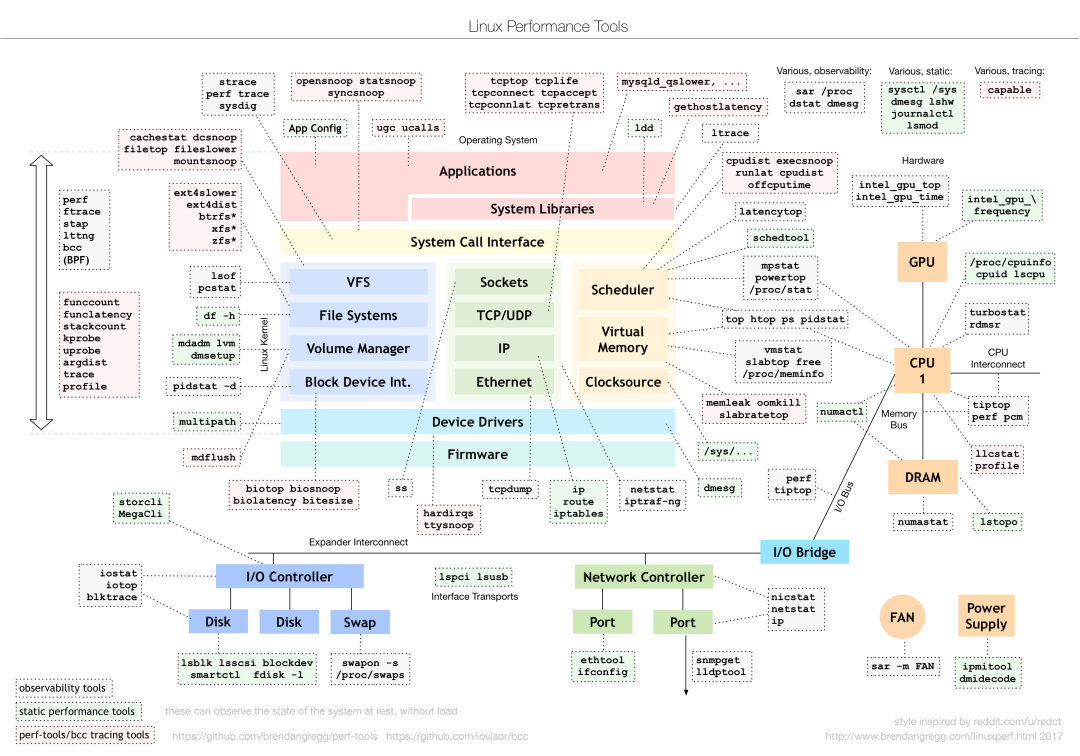
Se deben seleccionar diferentes herramientas de análisis de rendimiento para diferentes problemas de rendimiento. Las siguientes son herramientas de rendimiento de Linux de uso común y los tipos correspondientes de problemas de rendimiento analizados.
¿Cómo se debe entender "carga media"?
Carga media: El número medio de procesos que el sistema tiene en estado de ejecución y en estado ininterrumpido por unidad de tiempo, es decir, el número medio de procesos activos. No está directamente relacionado con el uso de la CPU como lo entendemos tradicionalmente.
El proceso ininterrumpible es el proceso que se encuentra en el proceso clave del modo kernel (como la respuesta de E/S común que espera al dispositivo). El estado ininterrumpible es en realidad un mecanismo de protección para que el sistema procese y los dispositivos de hardware.
promedio de carga razonable
En el entorno de producción real, se monitorea la carga promedio del sistema y se juzga la tendencia de cambio de la carga de acuerdo con los datos históricos. Cuando hay una tendencia alcista evidente en la carga, se llevan a cabo análisis e investigaciones oportunos. Por supuesto, también puede establecer un umbral (como cuando la carga promedio es superior al 70% de la cantidad de CPU)
En el trabajo real, a menudo confundimos los conceptos de promedio de carga y uso de CPU, pero los dos no son exactamente equivalentes:
-
Proceso intensivo de CPU, una gran cantidad de uso de CPU conducirá a un aumento en la carga promedio, en este momento los dos son consistentes -
Para los procesos intensivos de E/S, la espera de E/S también aumentará la carga promedio y el uso de la CPU no es necesariamente alto en este momento. -
Una gran cantidad de programación de procesos en espera de la CPU hará que la carga promedio aumente, y el uso de la CPU también será relativamente alto en este momento.
Cuando el promedio de carga es alto, puede deberse a procesos que hacen un uso intensivo de la CPU o puede deberse a una E/S ocupada. El análisis específico se puede combinar con la herramienta mpstat/pidstat para ayudar a analizar el origen de la carga
2UPC
Cambio de contexto de CPU (activado)
El cambio de contexto de la CPU es para guardar el contexto de la CPU (registro de la CPU y PC) de la tarea anterior, luego cargar el contexto de la nueva tarea en estos registros y el contador del programa, y finalmente saltar a la ubicación señalada por el contador del programa para ejecutar el nueva tarea. Entre ellos, el contexto guardado se almacenará en el kernel del sistema y se cargará cuando la tarea se reprograme para su ejecución para garantizar que el estado original de la tarea no se vea afectado.
Según el tipo de tarea, el cambio de contexto de la CPU se divide en:
-
cambio de contexto de proceso -
cambio de contexto de subproceso -
interruptor de contexto de interrupción
cambio de contexto de proceso
El proceso de Linux divide el espacio de ejecución del proceso en espacio del kernel y espacio del usuario de acuerdo con los permisos jerárquicos. La transición del modo de usuario al modo kernel debe realizarse a través de una llamada al sistema.
Un proceso de llamada al sistema en realidad realiza dos cambios de contexto de CPU:
-
Primero se guarda la posición de la instrucción del modo de usuario en el registro de la CPU, el registro de la CPU se actualiza a la posición de la instrucción del modo kernel y salta al modo kernel para ejecutar la tarea del kernel; -
Una vez que finaliza la llamada al sistema, los registros de la CPU restauran los datos de modo de usuario guardados originales y luego cambian al espacio de usuario para continuar ejecutándose.
El proceso de llamada al sistema no involucra recursos de modo de usuario de proceso, como la memoria virtual, ni cambia procesos. Es diferente del cambio de contexto de proceso en el sentido tradicional. Por lo tanto , la llamada al sistema a menudo se denomina cambio de modo privilegiado .
Los procesos son administrados y programados por el kernel, y el cambio de contexto del proceso solo puede ocurrir en el modo kernel. Por lo tanto, en comparación con las llamadas al sistema, antes de guardar el estado del kernel y los registros de la CPU del proceso actual, primero es necesario guardar la memoria virtual y la pila del proceso. Después de cargar el modo kernel del nuevo proceso, la memoria virtual y la pila de usuario del proceso también se actualizan.
Un proceso necesita cambiar de contexto solo cuando está programado para ejecutarse en la CPU. Existen los siguientes escenarios: las porciones de tiempo de la CPU se asignan a su vez, los recursos insuficientes del sistema hacen que el proceso se cuelgue, el proceso se suspende activamente a través de la función de suspensión, y el proceso de alta prioridad se adelanta al segmento de tiempo.Cuando el hardware interrumpe, el proceso en la CPU se suspende y realiza el servicio de interrupción en el kernel.
cambio de contexto de subproceso
Hay dos tipos de cambio de contexto de subprocesos:
-
Los subprocesos frontal y posterior pertenecen al mismo proceso, y los recursos de memoria virtual permanecen sin cambios al cambiar, solo se deben cambiar los datos privados, registros, etc. de los subprocesos; -
Los subprocesos delantero y trasero pertenecen a diferentes procesos, lo que es lo mismo que el cambio de contexto de proceso.
El cambio de subprocesos en el mismo proceso consume menos recursos, lo que también es la ventaja de los subprocesos múltiples.
interruptor de contexto de interrupción
El cambio de contexto de interrupción no involucra el modo de usuario del proceso, por lo que el contexto de interrupción solo incluye el estado necesario para la ejecución de la rutina de servicio de interrupción del modo kernel (registros de CPU, pila de kernel, parámetros de interrupción de hardware, etc.).
El procesamiento de interrupciones tiene una prioridad más alta que el proceso, por lo que el cambio de contexto de interrupción y el cambio de contexto de proceso no ocurren al mismo tiempo.
Docker+K8s+Jenkins, tecnología convencional, solución completa de datos de video
Cambio de contexto de CPU (abajo)
Puede ver el cambio de contexto general del sistema a través de vmstat
vmstat 5 #每隔5s输出一组数据
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 103388 145412 511056 0 0 18 60 1 1 2 1 96 0 0
0 0 0 103388 145412 511076 0 0 0 2 450 1176 1 1 99 0 0
0 0 0 103388 145412 511076 0 0 0 8 429 1135 1 1 98 0 0
0 0 0 103388 145412 511076 0 0 0 0 431 1132 1 1 98 0 0
0 0 0 103388 145412 511076 0 0 0 10 467 1195 1 1 98 0 0
1 0 0 103388 145412 511076 0 0 0 2 426 1139 1 0 99 0 0
4 0 0 95184 145412 511108 0 0 0 74 500 1228 4 1 94 0 0
0 0 0 103512 145416 511076 0 0 0 455 723 1573 12 3 83 2 0
-
cs (cambio de contexto) número de cambios de contexto por segundo -
en (interrupción) Número de interrupciones por segundo -
r (en ejecución o ejecutable) la longitud de la cola lista, la cantidad de procesos en ejecución y en espera de la CPU -
b (Bloqueado) Número de procesos en un estado de suspensión ininterrumpida
Para ver los detalles de cada proceso, debe usar pidstat para ver el cambio de contexto de cada proceso
pidstat -w 5
14时51分16秒 UID PID cswch/s nvcswch/s Command
14时51分21秒 0 1 0.80 0.00 systemd
14时51分21秒 0 6 1.40 0.00 ksoftirqd/0
14时51分21秒 0 9 32.67 0.00 rcu_sched
14时51分21秒 0 11 0.40 0.00 watchdog/0
14时51分21秒 0 32 0.20 0.00 khugepaged
14时51分21秒 0 271 0.20 0.00 jbd2/vda1-8
14时51分21秒 0 1332 0.20 0.00 argusagent
14时51分21秒 0 5265 10.02 0.00 AliSecGuard
14时51分21秒 0 7439 7.82 0.00 kworker/0:2
14时51分21秒 0 7906 0.20 0.00 pidstat
14时51分21秒 0 8346 0.20 0.00 sshd
14时51分21秒 0 20654 9.82 0.00 AliYunDun
14时51分21秒 0 25766 0.20 0.00 kworker/u2:1
14时51分21秒 0 28603 1.00 0.00 python3
-
cswch Cambios de contexto voluntarios por segundo (cambios de contexto provocados por la incapacidad del proceso para obtener los recursos necesarios) -
nvcswch Número de cambios de contexto involuntarios por segundo (programación forzada por el sistema, como la rotación de intervalos de tiempo)
vmstat 1 1 #首先获取空闲系统的上下文切换次数
sysbench --threads=10 --max-time=300 threads run #模拟多线程切换问题
vmstat 1 1 #新终端观察上下文切换情况
此时发现cs数据明显升高,同时观察其他指标:
r列: 远超系统CPU个数,说明存在大量CPU竞争
us和sy列:sy列占比80%,说明CPU主要被内核占用
in列: 中断次数明显上升,说明中断处理也是潜在问题
Significa que hay demasiados procesos ejecutándose/esperando por la CPU, lo que da como resultado una gran cantidad de cambios de contexto, y el cambio de contexto conduce a un alto uso de la CPU del sistema.
pidstat -w -u 1 #查看到底哪个进程导致的问题
Se puede ver a partir de los resultados que sysbench provoca un alto uso de la CPU, pero la cantidad de contextos generados por pidstat no se suma. El análisis de sysbench simula el cambio de subprocesos, por lo que debe agregar el parámetro -t después de pidstat para ver las métricas del subproceso.
Además, para demasiadas interrupciones, podemos leer el archivo /proc/interrupts
watch -d cat /proc/interrupts
El cambio más rápido en la cantidad de veces que se encuentra es la interrupción de reprogramación (RES), que se usa para activar una CPU inactiva para programar la ejecución de nuevas tareas. El análisis todavía se debe al problema de programación de demasiadas tareas, lo cual es consistente con el análisis de cambio de contexto.
¿Qué debo hacer si el uso de la CPU de una aplicación alcanza el 100 %?
Como sistema operativo multitarea, Linux divide el tiempo de la CPU en intervalos de tiempo muy cortos, que el programador asigna a cada tarea por separado. Con el fin de mantener el tiempo de la CPU, Linux activa una interrupción de tiempo a través de una frecuencia de pulsaciones predefinida y utiliza los jiffies globales para registrar el número de pulsaciones desde el arranque. La interrupción de tiempo se produce una vez que este valor +1.
Uso de la CPU , tiempo distinto del tiempo de inactividad como porcentaje del tiempo total de la CPU. El uso de la CPU se puede calcular a partir de los datos en /proc/stat. Debido a que se utiliza el valor acumulado del número de tics desde el inicio de /proc/stat, se calcula el uso promedio de la CPU desde el inicio, que generalmente tiene poca importancia. La diferencia entre dos valores de un período de tiempo se puede tomar en un intervalo para calcular el uso promedio de la CPU en ese período de tiempo. La herramienta de análisis de rendimiento proporciona el uso promedio de la CPU en un período de tiempo. Preste atención a la configuración del intervalo.
El uso de la CPU se puede ver por parte superior o ps. El problema de la CPU del proceso se puede analizar a través de perf, que se basa en el muestreo de eventos de rendimiento, que no solo puede analizar varios eventos y el rendimiento del kernel del sistema, sino también analizar los problemas de rendimiento de aplicaciones específicas.
perf top / perf record / perf report (-g habilita el muestreo de relaciones de llamada)
sudo docker run --name nginx -p 10000:80 -itd feisky/nginx
sudo docker run --name phpfpm -itd --network container:nginx feisky/php-fpm
ab -c 10 -n 100 http://XXX.XXX.XXX.XXX:10000/ #测试Nginx服务性能
Se encuentra que el número de solicitudes por segundo se puede tolerar en este momento, y el número de solicitudes probadas se incrementa de 100 a 10.000 en este momento. Ejecute top en otra terminal para ver el uso de cada CPU. Se encontró que varios procesos php-fpm en el sistema causaron un aumento repentino en el uso de la CPU.
Luego use perf para analizar qué función en php-fpm causa el problema.
perf top -g -p XXXX #对某一个php-fpm进程进行分析
Se descubrió que sqrt y add_function consumían demasiada CPU. En este momento, mirando el código fuente, resultó que el segmento de código de prueba en sqrt no se eliminó antes del lanzamiento, lo que provocó un millón de ciclos. Después de eliminar el código inútil, se descubrió que la capacidad de carga de nginx mejoró significativamente
El uso de la CPU del sistema es muy alto, ¿por qué no puedo encontrar aplicaciones con una CPU alta?
sudo docker run --name nginx -p 10000:80 -itd feisky/nginx:sp
sudo docker run --name phpfpm -itd --network container:nginx feisky/php-fpm:sp
ab -c 100 -n 1000 http://XXX.XXX.XXX.XXX:10000/ #并发100个请求测试
En los resultados experimentales, la cantidad de solicitudes por segundo aún no es alta. Después de reducir la cantidad de solicitudes simultáneas a 5, la capacidad de carga de nginx aún es muy baja.
En este momento, se utilizan top y pidstat para detectar que el uso de la CPU del sistema es demasiado alto, pero no se encuentran procesos con un uso elevado de la CPU.
Cuando esto suceda, qué información falta en nuestro análisis, vuelva a ejecutar el comando superior y observe durante un tiempo. Se encuentra que hay demasiados procesos en el estado En ejecución en la cola lista, lo que excede la cantidad de solicitudes simultáneas que tenemos por 5. Al observar detenidamente los datos de ejecución del proceso, se encuentra que tanto nginx como php-fpm están en el estado de sueño, pero en realidad se están ejecutando algunos procesos de estrés.
El siguiente paso es usar pidstat para analizar estos procesos de estrés y encontrar que no hay salida. La validación cruzada con ps aux encontró que el proceso aún no existe. La descripción no es una cuestión de herramientas. Verifique la parte superior nuevamente y descubra que el número de proceso del proceso de estrés ha cambiado. En este momento, puede deberse a las siguientes dos razones:
-
El proceso sigue fallando y reiniciando (como falla de segmentación/error de configuración, etc.), en este momento, el sistema de monitoreo puede reiniciar el proceso después de que finaliza el proceso; -
Provocados por procesos a corto plazo, es decir, comandos externos invocados por otras aplicaciones a través de exec, estos comandos generalmente solo se ejecutan por un corto tiempo y finalizan, y es difícil usar herramientas como top con intervalos largos para encontrar
Puede usar pstree para encontrar el proceso principal de estrés y averiguar la relación de llamada.
pstree | grep stress
Se descubrió que el subproceso llamado por php-fpm era el subproceso llamado por php-fpm.Si observa el código fuente en este momento, puede ver que cada solicitud llamará a un comando de estrés para simular el I /O presión. El resultado mostrado por top antes es que el uso de la CPU ha aumentado. Si realmente es causado por el comando de estrés, debe analizarse más a fondo. Después de agregar el parámetro verbose=1 a cada solicitud en el código, puede ver el resultado del comando stress.El resultado de interrumpir la prueba del comando muestra que hay un error en la falla de creación del archivo causado por el problema de permisos cuando el comando de estrés se está ejecutando.
En este momento, todavía es solo una suposición, y el siguiente paso es continuar analizándolo a través de la herramienta perf. El informe de rendimiento muestra que el estrés ocupa una gran cantidad de CPU y se puede optimizar solucionando el problema de permisos.
¿Qué debo hacer si aparece una gran cantidad de procesos ininterrumpidos y procesos zombis en el sistema?
estado del proceso
-
R Running/Runnable, que indica que el proceso está en la cola de espera de la CPU, ejecutándose o esperando para ejecutarse; -
D Disk Sleep, estado de suspensión ininterrumpida, generalmente significa que el proceso está interactuando con el hardware y no se permite que el proceso de interacción sea interrumpido por otros procesos; -
Z Zombie, proceso zombie, significa que el proceso realmente ha finalizado, pero el proceso principal no ha recuperado sus recursos; -
S Suspensión interrumpible, que puede interrumpir el estado de suspensión, lo que significa que el sistema suspende el proceso porque está esperando un evento. Cuando ocurra el evento de espera, se despertará y entrará en el estado R; -
I Idle, el estado inactivo, se usa en subprocesos del núcleo inactivos inactivos. Este estado no hará que aumente la carga promedio; -
T Stop/Traced, indicando que el proceso está en estado suspendido o rastreado (SIGSTOP/SIGCONT, GDB debugging); -
X Dead, el proceso está muerto y no se verá en top/ps.
Para el estado ininterrumpible, generalmente finaliza en muy poco tiempo y puede ignorarse. Sin embargo, si el sistema o el hardware fallan, el proceso puede permanecer en un estado ininterrumpible durante mucho tiempo, o incluso aparecer una gran cantidad de estados ininterrumpibles en el sistema.En este momento, es necesario prestar atención a si hay un estado ininterrumpido. Problema de rendimiento de E/S.
Los procesos zombis generalmente se encuentran en aplicaciones multiproceso.Cuando el proceso principal no tiene tiempo para procesar el estado del proceso secundario, el proceso secundario sale temprano y el proceso secundario se convierte en un proceso zombi. Una gran cantidad de procesos zombis se quedarán sin números de proceso PID, lo que provocará que no se establezcan nuevos procesos.
Problema de disco O_DIRECT
sudo docker run --privileged --name=app -itd feisky/app:iowait
ps aux | grep '/app'
Se puede ver que hay múltiples procesos de aplicaciones ejecutándose en este momento, y los estados son Ss+ y D+ respectivamente. La última s indica que el proceso es el proceso líder de una sesión, y el signo + indica el grupo de procesos en primer plano.
El grupo de procesos representa un grupo de procesos interrelacionados, y el proceso secundario es un miembro del grupo donde se encuentra el proceso principal. Una sesión es un grupo de uno o más procesos que comparten el mismo terminal de control.
Use top para ver los recursos del sistema y encuentre que: 1) La carga promedio aumenta gradualmente y la carga promedio alcanza la cantidad de CPU en 1 minuto, lo que indica que el sistema puede tener un cuello de botella en el rendimiento; 2) Hay muchos procesos zombies y aumentan constantemente; 3) El uso de CPU de us y sys no es alto, pero iowait es relativamente alto; 4) El uso de CPU de cada proceso no es alto, pero dos procesos están en estado D y pueden estar esperando IO .
El análisis de los datos actuales muestra que el iowait es demasiado alto, lo que conduce a un aumento en la carga promedio del sistema, y el crecimiento continuo de los procesos zombis indica que algunos programas no han podido limpiar adecuadamente los recursos de los procesos secundarios.
Utilice dstat para analizar, ya que puede ver el uso de la CPU y los recursos de E/S al mismo tiempo, lo cual es conveniente para el análisis comparativo.
dstat 1 10 #间隔1秒输出10组数据
Se puede ver que cuando wai (iowait) aumenta, la solicitud de lectura del disco será muy grande, lo que indica que el aumento de iowait está relacionado con la solicitud de lectura del disco. A continuación, analice qué proceso está leyendo el disco en ese momento.
El número del proceso en el estado D que vio anteriormente top, use pidstat -d -p XXX para mostrar las estadísticas de E/S del proceso. Se encuentra que ninguno de los procesos en el estado D tiene operaciones de lectura y escritura. Use pidstat -d para ver las estadísticas de E/S de todos los procesos y vea que el proceso de la aplicación está realizando operaciones de lectura de disco, leyendo 32 MB de datos por segundo. Un proceso debe usar una llamada al sistema para acceder al disco en el estado del núcleo. El siguiente punto es encontrar la llamada al sistema del proceso de la aplicación.
sudo strace -p XXX #对app进程调用进行跟踪
No hay permiso para reportar un error, porque ya ha sido rooteado. Entonces, en este caso, lo primero que debe verificar es si el estado del proceso es normal. El comando ps encuentra que el proceso ya está en el estado Z, es decir, el proceso zombie.
En este caso, herramientas como top pidstat no pueden brindar más información. En este momento, como en la Parte 5, use perf record -d y perf report para analizar y ver la pila de llamadas del proceso de la aplicación.
Se puede ver que la aplicación está leyendo datos a través de la llamada del sistema sys_read(), y cuando el proceso se ve desde new_sync_read y blkdev_direct_IO, se realiza una operación de lectura directa. La solicitud se lee directamente desde el disco y el iowait es no aumenta a través de la memoria caché.
Después del análisis capa por capa, la causa raíz es la E/S directa del disco dentro de la aplicación. Luego ubique la posición del código específico para la optimización.
proceso zombi
Después de la optimización anterior, iowait cae significativamente, pero la cantidad de procesos zombis aún aumenta. Primero, ubique el proceso principal del proceso zombi, imprima el árbol de llamadas del proceso zombi a través de pstree -aps XXX y encuentre que el proceso principal es el proceso de la aplicación.
Verifique el código de la aplicación para ver si el procesamiento del final del proceso secundario es correcto (si se llama a wait()/waitpid(), si hay un controlador para registrar la señal SIGCHILD, etc.).
Cuando aumenta iowait, primero use herramientas como dstat y pidstat para confirmar si hay un problema de E / S del disco y luego averigüe qué procesos están causando la E / S. Si no puede usar strace para analizar directamente la llamada al proceso, debe puede usar la herramienta perf para analizarlo.
Para el problema de los zombis, use pstree para encontrar el proceso principal y luego mire el código fuente para verificar la lógica de procesamiento para la terminación del proceso secundario.
Métricas de rendimiento de la CPU
-
uso de CPU
-
Uso de la CPU del usuario, incluido el modo de usuario (usuario) y el modo de usuario de baja prioridad (agradable). Si este indicador es demasiado alto, la aplicación está ocupada. -
Uso de la CPU del sistema, el porcentaje de tiempo que la CPU se ejecuta en modo kernel (excluyendo interrupciones) Un indicador alto indica que el kernel está ocupado. -
Uso de CPU en espera de E/S, iowait, un valor alto de este indicador indica que el sistema tarda mucho tiempo en interactuar con la E/S del dispositivo de hardware. -
Uso de CPU de interrupción suave/dura, un indicador alto indica una gran cantidad de interrupciones en el sistema. -
robar CPU/CPU invitada, que indica el porcentaje de CPU ocupado por la máquina virtual. -
promedio de carga
Idealmente, la carga promedio es igual a la cantidad de CPU lógicas, lo que indica que cada CPU se utiliza por completo. Si es mayor que eso, el sistema tiene una carga pesada.
-
cambio de contexto de proceso
Incluyendo el cambio voluntario cuando no se pueden obtener recursos y el cambio involuntario cuando el sistema se ve obligado a programar. El cambio de contexto en sí mismo es una función central para garantizar el funcionamiento normal de Linux. El cambio excesivo consumirá el tiempo de CPU del proceso en ejecución original en los registros, y el kernel ocupa y la memoria virtual y otros datos guardados y recuperados
-
Proporción de aciertos de caché de CPU
Para la reutilización de la memoria caché de la CPU, cuanto mayor sea la tasa de aciertos, mejor será el rendimiento.Entre ellos, L1/L2 se usa comúnmente en un solo núcleo y L3 se usa en multinúcleo.
herramientas de rendimiento
-
Cargar caso promedio -
Primero use el tiempo de actividad para verificar el promedio de carga del sistema -
Después de juzgar que la carga ha aumentado, use mpstat y pidstat para ver el uso de CPU de cada CPU y cada proceso respectivamente. Descubra el proceso que causa la carga promedio más alta. -
caso de cambio de contexto -
Primero use vmstat para ver la cantidad de cambios e interrupciones de contexto del sistema -
Luego use pidstat para observar el cambio de contexto voluntario e involuntario del proceso -
Finalmente, observe el cambio de contexto del hilo a través de pidstat -
Alto uso de CPU de un caso de proceso -
Primero use la parte superior para ver el uso de la CPU del sistema y el proceso, y ubique el proceso -
Luego use perf top para observar la cadena de llamadas del proceso y ubicar la función específica -
Casos con alto uso de CPU del sistema -
Primero use top para verificar el uso de la CPU del sistema y el proceso, top/pidstat no puede encontrar el proceso con un alto uso de la CPU -
Revisar la salida superior -
Comience con procesos que tengan un uso bajo de la CPU pero que estén en estado de ejecución -
El registro/informe de rendimiento encuentra las causas del proceso a corto plazo (herramienta execsnoop) -
Casos de procesos ininterrumpidos y zombis -
Primero use top para observar el auge de iowait y encontrar una gran cantidad de procesos ininterrumpidos y zombies -
strace no puede rastrear las llamadas al sistema de proceso -
Perf analiza la cadena de llamadas y descubre que la causa raíz proviene de la E/S directa del disco -
Caso de interrupción suave -
Top observa que el uso de CPU de interrupción suave del sistema es alto -
查看/proc/softirqs找到变化速率较快的几种软中断 -
sar命令发现是网络小包问题 -
tcpdump找出网络帧的类型和来源, 确定SYN FLOOD攻击导致
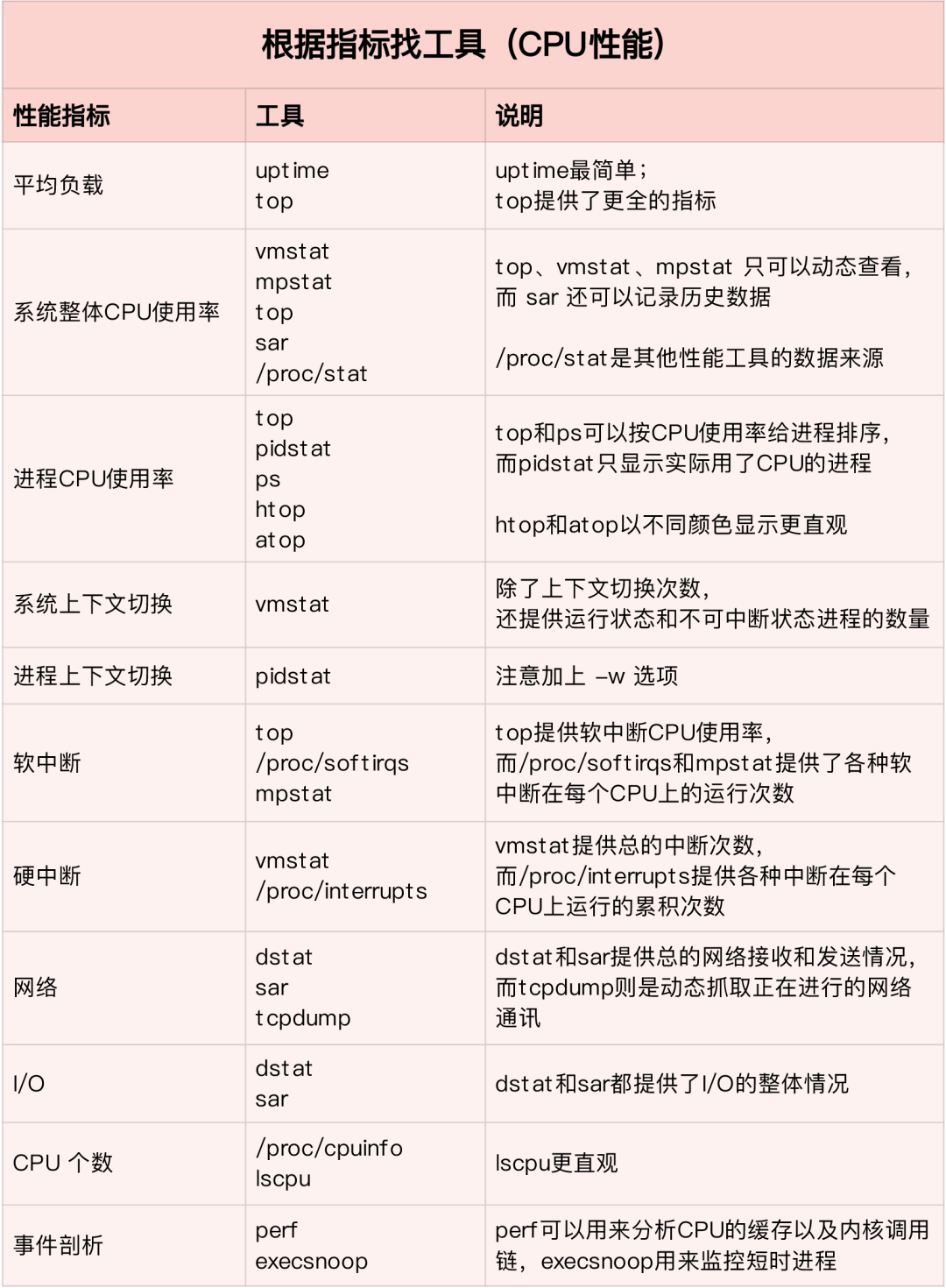
根据不同的性能指标来找合适的工具:
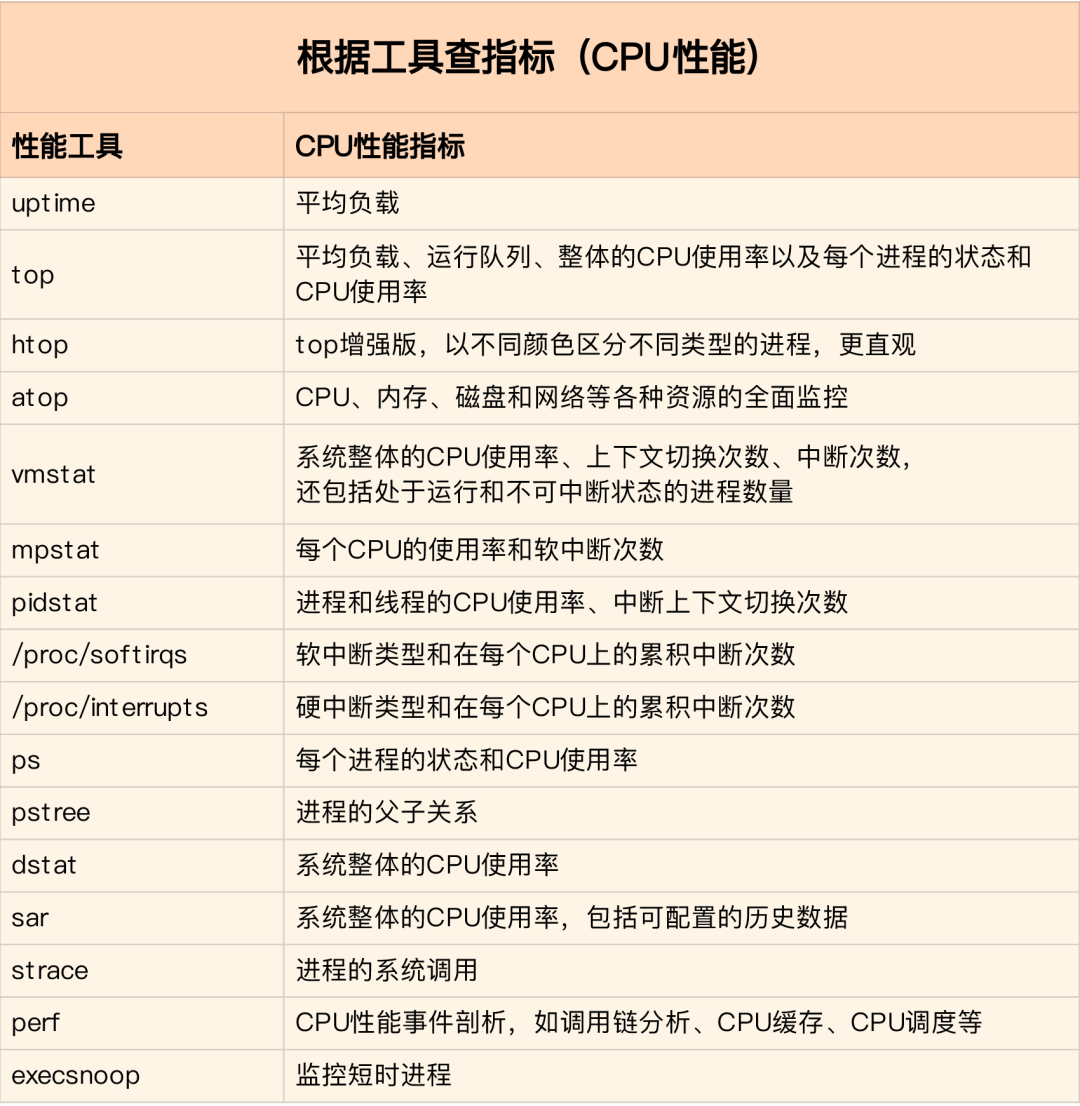
在生产环境中往往开发者没有权限安装新的工具包,只能最大化利用好系统中已经安装好的工具. 因此要了解一些主流工具能够提供哪些指标分析.
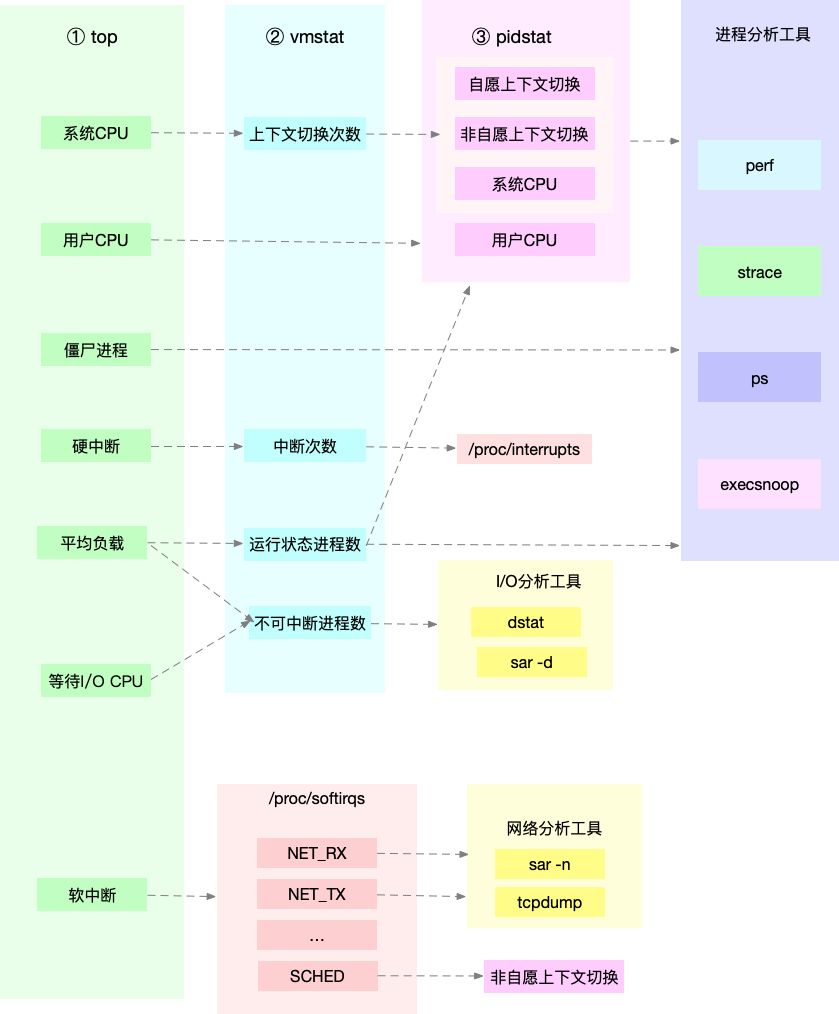
先运行几个支持指标较多的工具, 如top/vmstat/pidstat,根据它们的输出可以得出是哪种类型的性能问题. 定位到进程后再用strace/perf分析调用情况进一步分析. 如果是软中断导致用/proc/softirqs
CPU优化
-
应用程序优化
-
编译器优化: 编译阶段开启优化选项, 如gcc -O2 -
算法优化 -
异步处理: 避免程序因为等待某个资源而一直阻塞,提升程序的并发处理能力. (将轮询替换为事件通知) -
多线程代替多进程: 减少上下文切换成本 -
善用缓存: 加快程序处理速度 -
系统优化
-
CPU绑定: 将进程绑定要1个/多个CPU上,提高CPU缓存命中率,减少CPU调度带来的上下文切换 -
CPU独占: CPU亲和性机制来分配进程 -
优先级调整:使用nice适当降低非核心应用的优先级 -
为进程设置资源显示: cgroups设置使用上限,防止由某个应用自身问题耗尽系统资源 -
NUMA优化: CPU尽可能访问本地内存 -
中断负载均衡: irpbalance,将中断处理过程自动负载均衡到各个CPU上 -
TPS、QPS、系统吞吐量的区别和理解
-
QPS(TPS)
-
并发数
-
响应时间
QPS(TPS)=并发数/平均相应时间
-
用户请求服务器
-
服务器内部处理
-
服务器返回给客户
QPS类似TPS,但是对于一个页面的访问形成一个TPS,但是一次页面请求可能包含多次对服务器的请求,可能计入多次QPS
-
QPS (Queries Per Second)每秒查询率,一台服务器每秒能够响应的查询次数.
-
TPS (Transactions Per Second)每秒事务数,软件测试的结果.
-
系统吞吐量, 包括几个重要参数:
3内存
Linux内存是怎么工作的
内存映射
大多数计算机用的主存都是动态随机访问内存(DRAM),只有内核才可以直接访问物理内存。Linux内核给每个进程提供了一个独立的虚拟地址空间,并且这个地址空间是连续的。这样进程就可以很方便的访问内存(虚拟内存)。
虚拟地址空间的内部分为内核空间和用户空间两部分,不同字长的处理器地址空间的范围不同。32位系统内核空间占用1G,用户空间占3G。64位系统内核空间和用户空间都是128T,分别占内存空间的最高和最低处,中间部分为未定义。
并不是所有的虚拟内存都会分配物理内存,只有实际使用的才会。分配后的物理内存通过内存映射管理。为了完成内存映射,内核为每个进程都维护了一个页表,记录虚拟地址和物理地址的映射关系。页表实际存储在CPU的内存管理单元MMU中,处理器可以直接通过硬件找出要访问的内存。
当进程访问的虚拟地址在页表中查不到时,系统会产生一个缺页异常,进入内核空间分配物理内存,更新进程页表,再返回用户空间恢复进程的运行。
MMU以页为单位管理内存,页大小4KB。为了解决页表项过多问题Linux提供了多级页表和HugePage的机制。
虚拟内存空间分布
用户空间内存从低到高是五种不同的内存段:
-
只读段 代码和常量等 -
数据段 全局变量等 -
堆 动态分配的内存,从低地址开始向上增长 -
文件映射 动态库、共享内存等,从高地址开始向下增长 -
栈 包括局部变量和函数调用的上下文等,栈的大小是固定的。一般8MB
内存分配与回收
分配
malloc对应到系统调用上有两种实现方式:
-
brk() 针对小块内存(<128K),通过移动堆顶位置来分配。内存释放后不立即归还内存,而是被缓存起来。 -
**mmap()**针对大块内存(>128K),直接用内存映射来分配,即在文件映射段找一块空闲内存分配。
前者的缓存可以减少缺页异常的发生,提高内存访问效率。但是由于内存没有归还系统,在内存工作繁忙时,频繁的内存分配/释放会造成内存碎片。
后者在释放时直接归还系统,所以每次mmap都会发生缺页异常。在内存工作繁忙时,频繁内存分配会导致大量缺页异常,使内核管理负担增加。
上述两种调用并没有真正分配内存,这些内存只有在首次访问时,才通过缺页异常进入内核中,由内核来分配
回收
内存紧张时,系统通过以下方式来回收内存:
-
回收缓存:LRU算法回收最近最少使用的内存页面;
-
回收不常访问内存:把不常用的内存通过交换分区写入磁盘
-
杀死进程:OOM内核保护机制 (进程消耗内存越大oom_score越大,占用CPU越多oom_score越小,可以通过/proc手动调整oom_adj)
echo -16 > /proc/$(pidof XXX)/oom_adj
如何查看内存使用情况
free来查看整个系统的内存使用情况
top/ps来查看某个进程的内存使用情况
-
VIRT 进程的虚拟内存大小 -
RES 常驻内存的大小,即进程实际使用的物理内存大小,不包括swap和共享内存 -
SHR 共享内存大小,与其他进程共享的内存,加载的动态链接库以及程序代码段 -
%MEM 进程使用物理内存占系统总内存的百分比
怎样理解内存中的Buffer和Cache?
buffer是对磁盘数据的缓存,cache是对文件数据的缓存,它们既会用在读请求也会用在写请求中
如何利用系统缓存优化程序的运行效率
缓存命中率
缓存命中率是指直接通过缓存获取数据的请求次数,占所有请求次数的百分比。命中率越高说明缓存带来的收益越高,应用程序的性能也就越好。
安装bcc包后可以通过cachestat和cachetop来监测缓存的读写命中情况。
安装pcstat后可以查看文件在内存中的缓存大小以及缓存比例
#首先安装Go
export GOPATH=~/go
export PATH=~/go/bin:$PATH
go get golang.org/x/sys/unix
go ge github.com/tobert/pcstat/pcstat
dd缓存加速
dd if=/dev/sda1 of=file bs=1M count=512 #生产一个512MB的临时文件
echo 3 > /proc/sys/vm/drop_caches #清理缓存
pcstat file #确定刚才生成文件不在系统缓存中,此时cached和percent都是0
cachetop 5
dd if=file of=/dev/null bs=1M #测试文件读取速度
#此时文件读取性能为30+MB/s,查看cachetop结果发现并不是所有的读都落在磁盘上,读缓存命中率只有50%。
dd if=file of=/dev/null bs=1M #重复上述读文件测试
#此时文件读取性能为4+GB/s,读缓存命中率为100%
pcstat file #查看文件file的缓存情况,100%全部缓存
O_DIRECT选项绕过系统缓存
cachetop 5
sudo docker run --privileged --name=app -itd feisky/app:io-direct
sudo docker logs app #确认案例启动成功
#实验结果表明每读32MB数据都要花0.9s,且cachetop输出中显示1024次缓存全部命中
但是凭感觉可知如果缓存命中读速度不应如此慢,读次数时1024,页大小为4K,五秒的时间内读取了1024*4KB数据,即每秒0.8MB,和结果中32MB相差较大。说明该案例没有充分利用缓存,怀疑系统调用设置了直接I/O标志绕过系统缓存。因此接下来观察系统调用.
strace -p $(pgrep app)
#strace 结果可以看到openat打开磁盘分区/dev/sdb1,传入参数为O_RDONLY|O_DIRECT
这就解释了为什么读32MB数据那么慢,直接从磁盘读写肯定远远慢于缓存。找出问题后我们再看案例的源代码发现flags中指定了直接IO标志。删除该选项后重跑,验证性能变化。
内存泄漏,如何定位和处理?
对应用程序来说,动态内存的分配和回收是核心又复杂的一个逻辑功能模块。管理内存的过程中会发生各种各样的“事故”:
-
没正确回收分配的内存,导致了泄漏 -
访问的是已分配内存边界外的地址,导致程序异常退出
内存的分配与回收
虚拟内存分布从低到高分别是只读段,数据段,堆,内存映射段,栈五部分。其中会导致内存泄漏的是:
-
堆:由应用程序自己来分配和管理,除非程序退出这些堆内存不会被系统自动释放。 -
内存映射段:包括动态链接库和共享内存,其中共享内存由程序自动分配和管理
内存泄漏的危害比较大,这些忘记释放的内存,不仅应用程序自己不能访问,系统也不能把它们再次分配给其他应用。 内存泄漏不断累积甚至会耗尽系统内存.
如何检测内存泄漏
预先安装systat,docker,bcc
sudo docker run --name=app -itd feisky/app:mem-leak
sudo docker logs app
vmstat 3
可以看到free在不断下降,buffer和cache基本保持不变。说明系统的内存一致在升高。但并不能说明存在内存泄漏。此时可以通过memleak工具来跟踪系统或进程的内存分配/释放请求
/usr/share/bcc/tools/memleak -a -p $(pidof app)
从memleak输出可以看到,应用在不停地分配内存,并且这些分配的地址并没有被回收。通过调用栈看到是fibonacci函数分配的内存没有释放。定位到源码后查看源码来修复增加内存释放函数即可.
为什么系统的Swap变高
系统内存资源紧张时通过内存回收和OOM杀死进程来解决。其中可回收内存包括:
-
缓存/缓冲区,属于可回收资源,在文件管理中通常叫做文件页 -
在应用程序中通过fsync将脏页同步到磁盘 -
交给系统,内核线程pdflush负责这些脏页的刷新 -
被应用程序修改过暂时没写入磁盘的数据(脏页),要先写入磁盘然后才能内存释放 -
内存映射获取的文件映射页,也可以被释放掉,下次访问时从文件重新读取
对于程序自动分配的堆内存,也就是我们在内存管理中的匿名页,虽然这些内存不能直接释放,但是Linux提供了Swap机制将不常访问的内存写入到磁盘来释放内存,再次访问时从磁盘读取到内存即可。
Swap原理
Swap本质就是把一块磁盘空间或者一个本地文件当作内存来使用,包括换入和换出两个过程:
-
换出:将进程暂时不用的内存数据存储到磁盘中,并释放这些内存 -
换入:进程再次访问内存时,将它们从磁盘读到内存中
Linux如何衡量内存资源是否紧张?
-
直接内存回收 新的大块内存分配请求,但剩余内存不足。此时系统会回收一部分内存;
-
kswapd0 内核线程定期回收内存。为了衡量内存使用情况,定义了pages_min,pages_low,pages_high三个阈值,并根据其来进行内存的回收操作。
-
剩余内存 < pages_min,进程可用内存耗尽了,只有内核才可以分配内存
-
pages_min < 剩余内存 < pages_low,内存压力较大,kswapd0执行内存回收,直到剩余内存 > pages_high
-
pages_low < 剩余内存 < pages_high,内存有一定压力,但可以满足新内存请求
-
剩余内存 > pages_high,说明剩余内存较多,无内存压力
pages_low = pages_min 5 / 4 pages_high = pages_min 3 / 2
NUMA 与 SWAP
很多情况下系统剩余内存较多,但SWAP依旧升高,这是由于处理器的NUMA架构。
在NUMA架构下多个处理器划分到不同的Node,每个Node都拥有自己的本地内存空间。在分析内存的使用时应该针对每个Node单独分析
numactl --hardware #查看处理器在Node的分布情况,以及每个Node的内存使用情况
内存三个阈值可以通过/proc/zoneinfo来查看,该文件中还包括活跃和非活跃的匿名页/文件页数。
当某个Node内存不足时,系统可以从其他Node寻找空闲资源,也可以从本地内存中回收内存。通过/proc/sys/vm/zone_raclaim_mode来调整。
-
0表示既可以从其他Node寻找空闲资源,也可以从本地回收内存 -
1,2,4表示只回收本地内存,2表示可以会回脏数据回收内存,4表示可以用Swap方式回收内存。
swappiness
在实际回收过程中Linux根据/proc/sys/vm/swapiness选项来调整使用Swap的积极程度,从0-100,数值越大越积极使用Swap,即更倾向于回收匿名页;数值越小越消极使用Swap,即更倾向于回收文件页。
注意:这只是调整Swap积极程度的权重,即使设置为0,当剩余内存+文件页小于页高阈值时,还是会发生Swap。
Swap升高时如何定位分析
free #首先通过free查看swap使用情况,若swap=0表示未配置Swap
#先创建并开启swap
fallocate -l 8G /mnt/swapfile
chmod 600 /mnt/swapfile
mkswap /mnt/swapfile
swapon /mnt/swapfile
free #再次执行free确保Swap配置成功
dd if=/dev/sda1 of=/dev/null bs=1G count=2048 #模拟大文件读取
sar -r -S 1 #查看内存各个指标变化 -r内存 -S swap
#根据结果可以看出,%memused在不断增长,剩余内存kbmemfress不断减少,缓冲区kbbuffers不断增大,由此可知剩余内存不断分配给了缓冲区
#一段时间之后,剩余内存很小,而缓冲区占用了大部分内存。此时Swap使用之间增大,缓冲区和剩余内存只在小范围波动
停下sar命令
cachetop5 #观察缓存
#可以看到dd进程读写只有50%的命中率,未命中数为4w+页,说明正式dd进程导致缓冲区使用升高
watch -d grep -A 15 ‘Normal’ /proc/zoneinfo #观察内存指标变化
#发现升级内存在一个小范围不停的波动,低于页低阈值时会突然增大到一个大于页高阈值的值
说明剩余内存和缓冲区的波动变化正是由于内存回收和缓存再次分配的循环往复。有时候Swap用的多,有时候缓冲区波动更多。此时查看swappiness值为60,是一个相对中和的配置,系统会根据实际运行情况来选去合适的回收类型.
如何“快准狠”找到系统内存存在的问题
内存性能指标
系统内存指标
-
已用内存/剩余内存 -
共享内存 (tmpfs实现) -
可用内存:包括剩余内存和可回收内存 -
缓存:磁盘读取文件的页缓存,slab分配器中的可回收部分 -
缓冲区:原始磁盘块的临时存储,缓存将要写入磁盘的数据
进程内存指标
-
虚拟内存:5大部分 -
常驻内存:进程实际使用的物理内存,不包括Swap和共享内存 -
共享内存:与其他进程共享的内存,以及动态链接库和程序的代码段 -
Swap内存:通过Swap换出到磁盘的内存
缺页异常
-
可以直接从物理内存中分配,次缺页异常 -
需要磁盘IO介入(如Swap),主缺页异常。此时内存访问会慢很多
内存性能工具
根据不同的性能指标来找合适的工具:
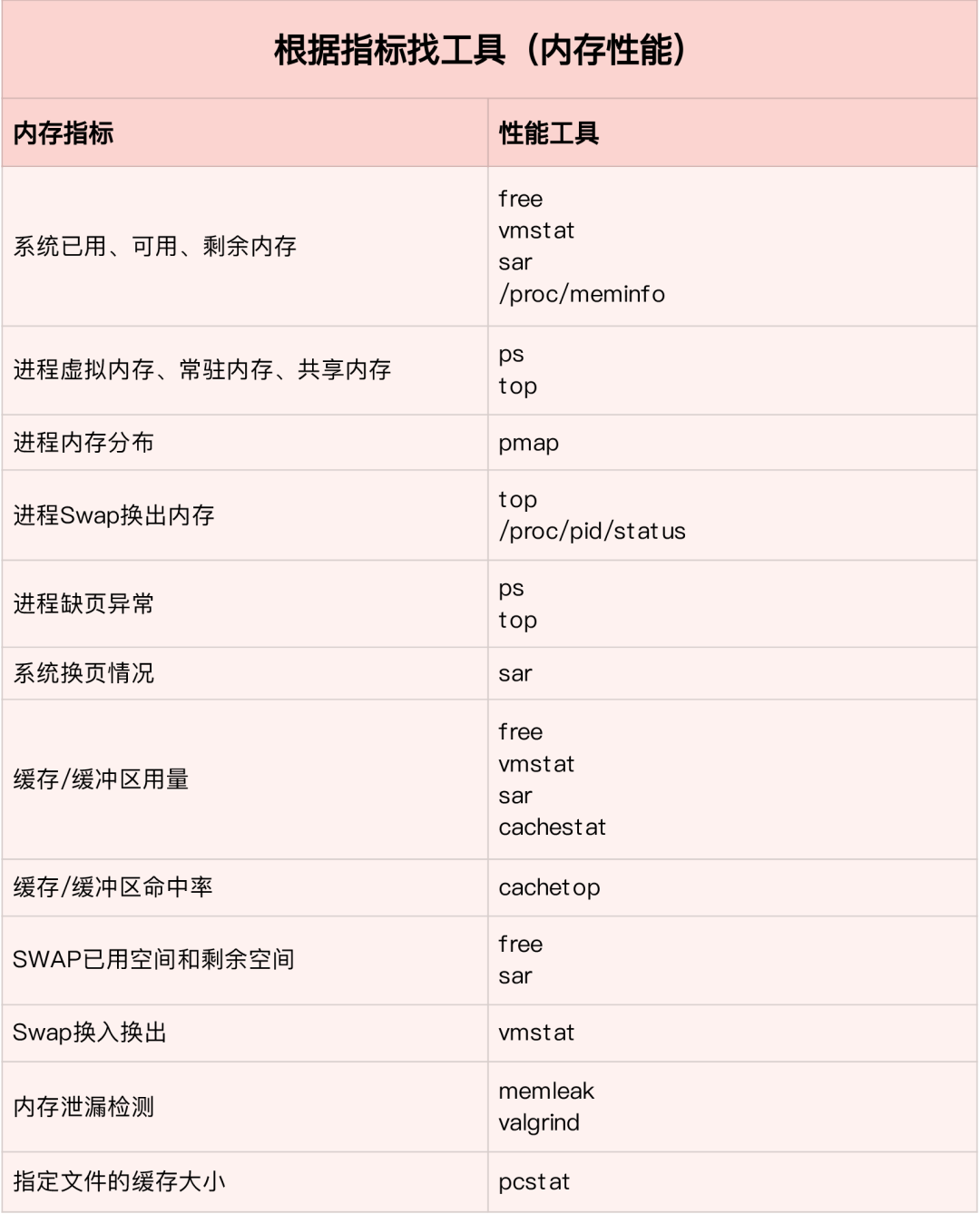
内存分析工具包含的性能指标:
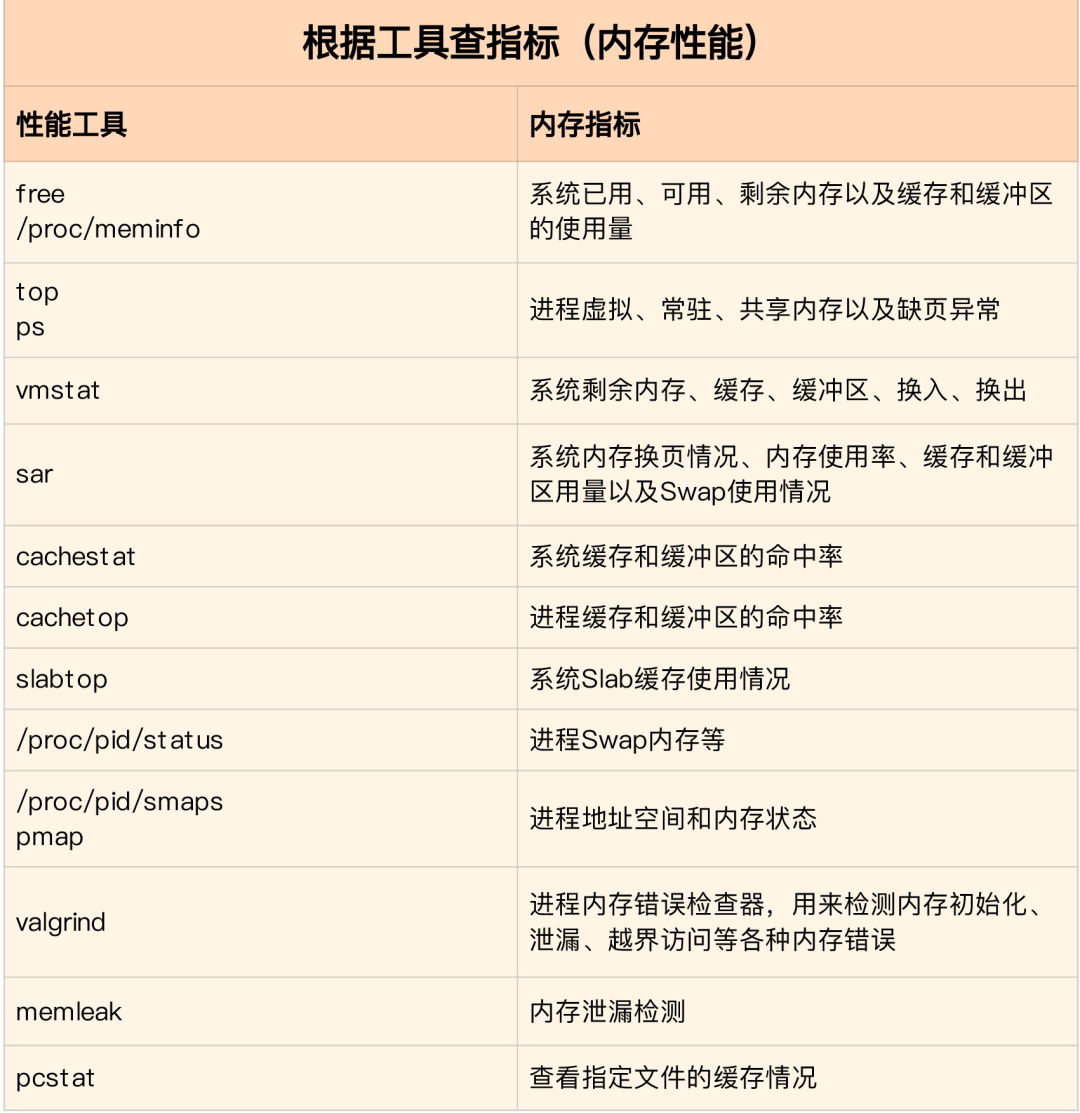
如何迅速分析内存的性能瓶颈
通常先运行几个覆盖面比较大的性能工具,如free,top,vmstat,pidstat等
-
先用free和top查看系统整体内存使用情况 -
再用vmstat和pidstat,查看一段时间的趋势,从而判断内存问题的类型 -
最后进行详细分析,比如内存分配分析,缓存/缓冲区分析,具体进程的内存使用分析等
常见的优化思路:
-
最好禁止Swap,若必须开启则尽量降低swappiness的值 -
减少内存的动态分配,如可以用内存池,HugePage等 -
尽量使用缓存和缓冲区来访问数据。如用堆栈明确声明内存空间来存储需要缓存的数据,或者用Redis外部缓存组件来优化数据的访问 -
cgroups等方式来限制进程的内存使用情况,确保系统内存不被异常进程耗尽 -
/proc/pid/oom_adj调整核心应用的oom_score,保证即使内存紧张核心应用也不会被OOM杀死
vmstat使用详解
vmstat命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。可以看到整个机器的CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使用率和内存使用率(使用场景不一样)。
vmstat 2
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 1379064 282244 11537528 0 0 3 104 0 0 3 0 97 0 0
0 0 0 1372716 282244 11537544 0 0 0 24 4893 8947 1 0 98 0 0
0 0 0 1373404 282248 11537544 0 0 0 96 5105 9278 2 0 98 0 0
0 0 0 1374168 282248 11537556 0 0 0 0 5001 9208 1 0 99 0 0
0 0 0 1376948 282248 11537564 0 0 0 80 5176 9388 2 0 98 0 0
0 0 0 1379356 282256 11537580 0 0 0 202 5474 9519 2 0 98 0 0
1 0 0 1368376 282256 11543696 0 0 0 0 5894 8940 12 0 88 0 0
1 0 0 1371936 282256 11539240 0 0 0 10554 6176 9481 14 1 85 1 0
1 0 0 1366184 282260 11542292 0 0 0 7456 6102 9983 7 1 91 0 0
1 0 0 1353040 282260 11556176 0 0 0 16924 7233 9578 18 1 80 1 0
0 0 0 1359432 282260 11549124 0 0 0 12576 5495 9271 7 0 92 1 0
0 0 0 1361744 282264 11549132 0 0 0 58 8606 15079 4 2 95 0 0
1 0 0 1367120 282264 11549140 0 0 0 2 5716 9205 8 0 92 0 0
0 0 0 1346580 282264 11562644 0 0 0 70 6416 9944 12 0 88 0 0
0 0 0 1359164 282264 11550108 0 0 0 2922 4941 8969 3 0 97 0 0
1 0 0 1353992 282264 11557044 0 0 0 0 6023 8917 15 0 84 0 0
# 结果说明
- r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
- b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的。
- swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
- free 空闲的物理内存的大小,我的机器内存总共8G,剩余3415M。
- buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用300多M
- cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
- si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
- so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
- bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
- bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
- in 每秒CPU的中断次数,包括时间中断
- cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
- us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
- sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
- id 空闲CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
- wt 等待IO CPU时间
pidstat 使用详解
pidstat主要用于监控全部或指定进程占用系统资源的情况,如CPU,内存、设备IO、任务切换、线程等。
使用方法:
-
pidstat –d interval times 统计各个进程的IO使用情况 -
pidstat –u interval times 统计各个进程的CPU统计信息 -
pidstat –r interval times 统计各个进程的内存使用信息 -
pidstat -w interval times 统计各个进程的上下文切换 -
p PID 指定PID
1、统计IO使用情况
pidstat -d 1 10
03:02:02 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
03:02:03 PM 0 816 0.00 918.81 0.00 jbd2/vda1-8
03:02:03 PM 0 1007 0.00 3.96 0.00 AliYunDun
03:02:03 PM 997 7326 0.00 1904.95 918.81 java
03:02:03 PM 997 8539 0.00 3.96 0.00 java
03:02:03 PM 0 16066 0.00 35.64 0.00 cmagent
03:02:03 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
03:02:04 PM 0 816 0.00 1924.00 0.00 jbd2/vda1-8
03:02:04 PM 997 7326 0.00 11156.00 1888.00 java
03:02:04 PM 997 8539 0.00 4.00 0.00 java
-
UID -
PID -
kB_rd/s: 每秒进程从磁盘读取的数据量 KB 单位 read from disk each second KB -
kB_wr/s: 每秒进程向磁盘写的数据量 KB 单位 write to disk each second KB -
kB_ccwr/s: 每秒进程向磁盘写入,但是被取消的数据量,This may occur when the task truncates some dirty pagecache. -
iodelay: Block I/O delay, measured in clock ticks -
Command: 进程名 task name
2、统计CPU使用情况
# 统计CPU
pidstat -u 1 10
03:03:33 PM UID PID %usr %system %guest %CPU CPU Command
03:03:34 PM 0 2321 3.96 0.00 0.00 3.96 0 ansible
03:03:34 PM 0 7110 0.00 0.99 0.00 0.99 4 pidstat
03:03:34 PM 997 8539 0.99 0.00 0.00 0.99 5 java
03:03:34 PM 984 15517 0.99 0.00 0.00 0.99 5 java
03:03:34 PM 0 24406 0.99 0.00 0.00 0.99 5 java
03:03:34 PM 0 32158 3.96 0.00 0.00 3.96 2 ansible
-
UID -
PID -
%usr: 进程在用户空间占用 cpu 的百分比 -
%system: 进程在内核空间占用 CPU 百分比 -
%guest: 进程在虚拟机占用 CPU 百分比 -
%wait: 进程等待运行的百分比 -
%CPU: 进程占用 CPU 百分比 -
CPU: 处理进程的 CPU 编号 -
Command: 进程名
3、统计内存使用情况
# 统计内存
pidstat -r 1 10
Average: UID PID minflt/s majflt/s VSZ RSS %MEM Command
Average: 0 1 0.20 0.00 191256 3064 0.01 systemd
Average: 0 1007 1.30 0.00 143256 22720 0.07 AliYunDun
Average: 0 6642 0.10 0.00 6301904 107680 0.33 java
Average: 997 7326 10.89 0.00 13468904 8395848 26.04 java
Average: 0 7795 348.15 0.00 108376 1233 0.00 pidstat
Average: 997 8539 0.50 0.00 8242256 2062228 6.40 java
Average: 987 9518 0.20 0.00 6300944 1242924 3.85 java
Average: 0 10280 3.70 0.00 807372 8344 0.03 aliyun-service
Average: 984 15517 0.40 0.00 6386464 1464572 4.54 java
Average: 0 16066 236.46 0.00 2678332 71020 0.22 cmagent
Average: 995 20955 0.30 0.00 6312520 1408040 4.37 java
Average: 995 20956 0.20 0.00 6093764 1505028 4.67 java
Average: 0 23936 0.10 0.00 5302416 110804 0.34 java
Average: 0 24406 0.70 0.00 10211672 2361304 7.32 java
Average: 0 26870 1.40 0.00 1470212 36084 0.11 promtail
-
UID -
PID -
Minflt/s: la cantidad de fallas de página por segundo (fallas de página menores), la cantidad de fallas de página generadas al asignar direcciones de memoria virtual a direcciones de memoria física -
Majflt/s: el número de fallas de página principales por segundo (fallas de página principales), cuando la dirección de memoria virtual se asigna a la dirección de memoria física, la página correspondiente está en el intercambio -
Uso de memoria virtual VSZ: unidad de KB de memoria virtual utilizada por el proceso -
RSS: La memoria física utilizada por el proceso en KB -
%MEM: uso de memoria -
Comando: el nombre de la tarea de comando del proceso
4. Ver el uso de procesos específicos
pidstat -T ALL -r -p 20955 1 10
03:12:16 PM UID PID minflt/s majflt/s VSZ RSS %MEM Command
03:12:17 PM 995 20955 0.00 0.00 6312520 1408040 4.37 java
03:12:16 PM UID PID minflt-nr majflt-nr Command
03:12:17 PM 995 20955 0 0 javaFINAL
Sitio oficial: www.linuxprobe.com
Enciclopedia de comandos de Linux: www.linuxcool.com

Profesor Liu Trent QQ: 5604241
Grupo de intercambio técnico de Linux: 3586725
(Nuevo grupo, en el grupo caliente...)
Los lectores que quieran aprender el sistema Linux pueden hacer clic en el botón "Leer el texto original" para comprender el libro "Linux debe aprenderse así", y también es muy adecuado para que lo lea el personal profesional de operación y mantenimiento, convirtiéndose en un alto- valioso libro de referencia para ayudarle en su trabajo!