eBPF ( Extended Berkeley Packet Filter ) se originó en el kernel de Linux y es un programa aislado que puede ejecutarse en el kernel del sistema operativo. Su tecnología extiende de manera segura y eficiente la funcionalidad del kernel. Sin cambiar el código fuente del kernel ni cargar módulos del kernel.
eBPF es ampliamente utilizado para:
-
Seguimiento del rendimiento del kernel
-
Ciberseguridad y Observabilidad
-
Seguridad en tiempo de ejecución de aplicaciones y contenedores
...
1. El proceso general de ejecución del programa eBPF
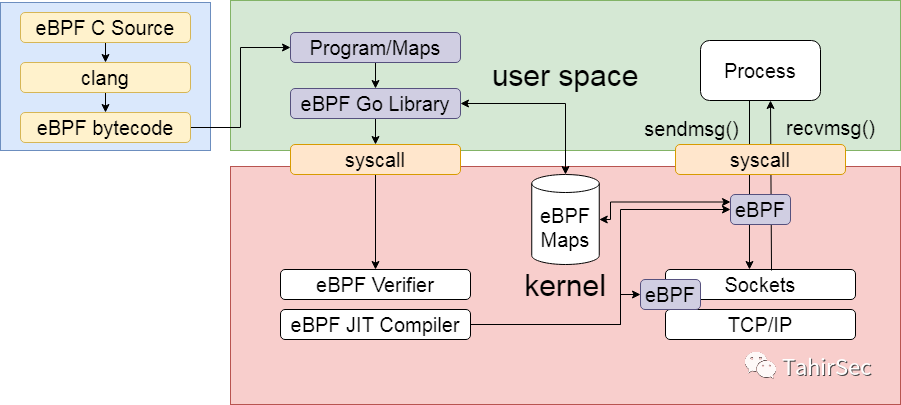
El programa eBPF primero usa C o Rust para escribir el programa eBPF, LLVM lo compila en código de bytes y el programa en modo de usuario usa la biblioteca eBPF para cargar el código de bytes eBPF en el kernel de Linux usando la llamada al sistema bpf.
Validador ebpf del núcleo, verificando el código de bytes BPF:
-
Si el proceso que inicia la llamada al sistema bpf tiene los permisos correspondientes, se requiere que el proceso tenga las capacidades de Linux relevantes (CAP_BPF) o permisos de root;
-
Verifique si el programa hará que el kernel se bloquee, por ejemplo, si hay variables no inicializadas, si hay declaraciones que pueden causar acceso de puntero nulo a la matriz fuera de los límites;
-
Compruebe si el programa se ejecuta en un tiempo limitado, eBPF solo permite bucles y saltos limitados, y solo permite ejecutar un número limitado de instrucciones.
Después de compilar el programa eBPF, se monta en el evento correspondiente en el kernel, como una llamada al sistema.Cuando se genera una llamada al sistema, el kernel se activa para llamar al programa eBPF correspondiente. El programa kernel ebpf interactúa con el programa en modo usuario a través de la estructura de datos del mapa para completar las funciones correspondientes.
2. Seguimiento de eBPF
2.1 Tipos de sondas
Sondeos del kernel: proporcionan acceso dinámico a los componentes internos del kernel
Tracepoints: proporciona acceso dinámico a los programas que se ejecutan en el espacio del usuario
Sondas de espacio de usuario: proporciona acceso dinámico a los programas que se ejecutan en el espacio de usuario
Puntos de seguimiento definidos estáticamente por el usuario: proporciona acceso estático a los programas que se ejecutan en el espacio del usuario
2.2 Sonda del núcleo
Las sondas del kernel pueden establecer indicadores dinámicos o interrupciones en cualquier instrucción del kernel, y cuando el kernel alcanza estos indicadores, se ejecutará el código adjunto a la sonda, después de lo cual el kernel reanudará el modo normal.
Las sondas de kernel se dividen en dos categorías: kprobes y kretprobes.
2.2.1 ksondas
kprobes permiten insertar programas BPF antes de ejecutar cualquier instrucción del kernel, es necesario conocer la firma de la función del punto de inserción, las sondas del kernel no son ABI (interfaz binaria del programa) estables, por lo que se debe tener cuidado al ejecutar programas que configuran sondas en diferentes kernel . versiones _ Cuando el kernel ejecuta la instrucción para configurar la sonda, comenzará a ejecutar el programa BPF desde el punto de ejecución del código y volverá al lugar donde se insertó el programa BPF para continuar la ejecución después de que se complete la ejecución del programa BPF.
2.2.2 sondas kret
Los kretprobes se insertan en el programa BPF cuando la instrucción del núcleo tiene un valor de retorno. Por lo general, usamos kprobes y kretprobes en un programa BPF para obtener una comprensión integral de las instrucciones del núcleo.
2.3 Puntos de seguimiento
Los puntos de seguimiento son marcadores estáticos del código del kernel que se pueden usar para adjuntar código a un kernel en ejecución. La principal diferencia entre los puntos de rastreo y los kprobes es que los desarrolladores del kernel escriben y modifican los puntos de rastreo en el kernel. Dado que el trackpoint existe estáticamente, el ABI del rastreador es el más estable.
Los desarrolladores del kernel agregan puntos de seguimiento, por lo que es posible que los puntos de seguimiento no cubran todos los subsistemas del kernel.
El contenido del directorio /sys/kernel/debug/tracing/events puede ver todos los puntos de seguimiento disponibles en el sistema.
Cada subdirectorio del resultado anterior corresponde a un punto de seguimiento al que se puede adjuntar un programa BPF. Hay dos archivos adicionales: el primer archivo es enable, que permite habilitar y deshabilitar todos los puntos de rastreo del subsistema BPF. Si el contenido de este archivo es 0, significa que el punto de rastreo está deshabilitado. Si el contenido del archivo es 1, el punto de rastreo está habilitado.
Las sondas de kernel y los puntos de seguimiento brindan acceso completo al kernel. Utilice puntos de rastreo siempre que sea posible porque son más seguros.
2.4 Sonda de espacio de usuario
Las sondas de espacio de usuario permiten establecer indicadores dinámicos en programas que se ejecutan en el espacio de usuario. Son equivalentes a las sondas del kernel, y las sondas del espacio del usuario son sistemas de monitoreo que se ejecutan en el espacio del usuario. Cuando definimos la sonda, el kernel creará una trampa en la instrucción adjunta, y cuando el programa ejecute la instrucción, el kernel activará el evento para llamar a la función de sonda llamando a la función de devolución de llamada. Uprobes también puede acceder a cualquier biblioteca a la que esté vinculado el programa y, siempre que se conozca el nombre de la instrucción, se puede rastrear la llamada correspondiente.
Al igual que las sondas del kernel, las sondas del espacio de usuario también se dividen en dos categorías: uprobes y uretporbes, según la etapa del ciclo de instrucción en la que se encuentre el programa BPF insertado.
2.4.1 Sondas superiores
Los Uprobes son ganchos que el kernel inserta en un conjunto de instrucciones específico del programa antes de ejecutarlo. Las firmas de funciones pueden variar para diferentes versiones del kernel. En Linux, puede usar el comando nm para enumerar todos los símbolos incluidos en el archivo de objeto ELF y verificar si la instrucción de seguimiento existe en el programa.
2.4.2 sondas uretrales
uretprobes son sondas paralelas kretprobes, adecuadas para su uso en programas de espacio de usuario. Agrega el programa BPF al valor de retorno de la instrucción, lo que permite acceder al valor de retorno desde los registros a través del código BPF.
La combinación de uprobes y uretprobes puede escribir programas BPF más complejos.
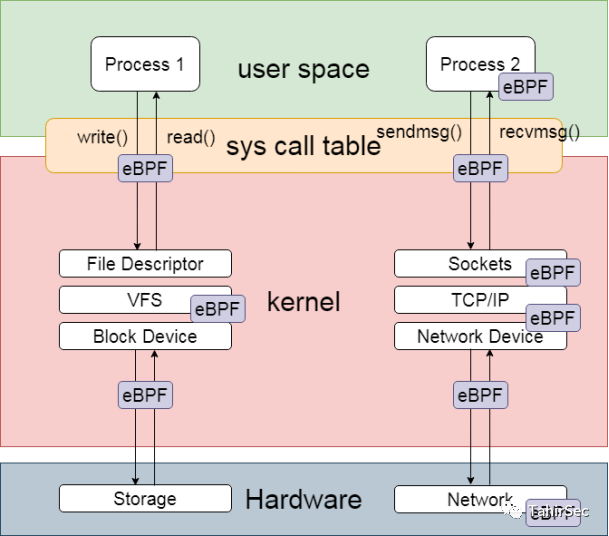
● eBPF permite la creación de puntos de seguimiento en el kernel en
○ Llamadas al sistema
○ Interfaz de red (socket/xdp)
○ Entrada/salida de función
○ Puntos de seguimiento del kernel
○ Contenedores (cgroups)
○ Función de modo de usuario
...
● eBPF permite crear sondas:
○ Sondeo del núcleo (kprobe)
○ Sonda de usuario (upprobe)
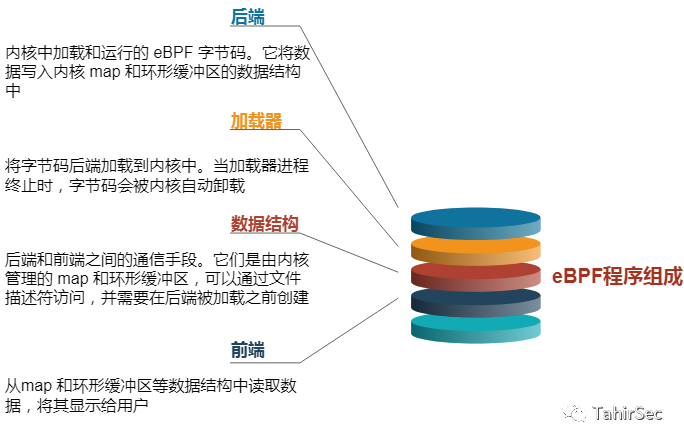
3. Componentes del programa eBPF
4. mapeo eBPF
Los mapas BPF se almacenan en el kernel como clave/valor y se puede acceder a ellos mediante cualquier programa BPF. Los programas de espacio de usuario también pueden acceder a mapas BPF a través de descriptores de archivos. Cualquier tipo de datos que implemente un tamaño específico se puede almacenar en un mapa BPF. El kernel trata las claves y los valores como bloques binarios, lo que significa que al kernel no le importa qué contiene exactamente el mapa BPF.
Los validadores BPF utilizan varias medidas de seguridad para garantizar que los mapas BPF se creen y accedan de manera segura.
La forma más sencilla de crear un mapa BPF es usar la llamada al sistema bpf. Si el primer parámetro de esta llamada al sistema se establece en BPF_MAP_CREATE, significa crear un nuevo mapa. Esta llamada devolverá el descriptor de archivo asociado con la creación del mapa. El segundo parámetro de la llamada al sistema bpf es la configuración del mapa BPF.
union bpf_attr(){struct {__u32 map_type; /*bpf_map_type*/__u32 key_size;__u32 value_size;__u32 max_entries;__u32 map_flags;};}
El tercer parámetro de la llamada al sistema bpf es establecer el tamaño de la propiedad, creando una asignación de tabla hash de claves y enteros sin signo:
union bpf_attr_my_map {.map_type = BPF_MAP_TYPE_HASH,.key_size = sizeof(int),.value_size = sizeof(int),.max_entries = 100,.map_flags = BPF_F_NO_PREALLOC,};int fd = bpf(BPF_MAP_CREATE, &my_map, sizeof(my_map));
Si la llamada al sistema falla, el kernel devuelve - 1. Hay tres razones para la falla, que se distinguen por errno.
-
Si el atributo no es válido, el núcleo devuelve EINVAL.
-
Si no hay suficientes privilegios para realizar la operación, el núcleo devuelve EPERM.
-
Si no hay suficiente memoria para mantener el mapeo, el núcleo devolverá ENOMEM.
4.1 Creación de mapas BPF usando convenciones ELF
Algunas convenciones y funciones auxiliares existen en el kernel para generar y usar mapas BPF. A pesar de que estas convenciones se ejecutan en el kernel, la capa inferior todavía está a través de la llamada al sistema bpf para crear la asignación.
La función auxiliar bpf_map_create encapsula el código que usamos anteriormente y puede inicializar fácilmente el mapa a pedido.
int fd;fd = bpf_map_create(BPF_MAP_TYPE_HASH, sizeof(int), sizeof(int), 100, BPF_F_NO_PREALOC);
4.2 Uso del mapeo BPF
La comunicación entre el kernel y el espacio del usuario es la base para escribir programas BPF. Tanto el código del programa del kernel como el del espacio del usuario pueden acceder al mapa, pero usan diferentes firmas de API.
4.2.1 Actualización de elementos del mapa BPF
Cree contenido de actualización de mapas, el kernel proporciona una función de ayuda bpf_map_update_elem para lograrlo.
El programa del kernel debe cargar la función bpf_map_update_elem desde el archivo bpf/bpf_helpers.h, y el programa del usuario debe cargarse desde el archivo tools/lib/bpf/bpf.h, por lo que la firma de la función a la que accede el programa del kernel es diferente. de la firma de la función a la que accede el espacio de usuario.
El programa del kernel puede acceder directamente al mapa, mientras que el programa del usuario necesita usar el descriptor de archivo para hacer referencia al mapa.
int key, value, result;key = 1, value = 1234;result = bpf_map_update_elem(map_data[0].fd, &key, &value, BPF_ANY);if(result == 0)printf("Map updated with new element\n");elseprintf("Failed to update map with new value: %d (%s)\n", result, strerror(errno));
4.2.2 Lectura de elementos del mapa BPF
BPF proporciona dos funciones auxiliares diferentes para leer elementos del mapa dependiendo de dónde se esté ejecutando el programa. Ambos nombres de funciones son bpf_map_lookup_elem.
Lea el mapa desde el espacio del núcleo:
int key, value, result;key = 1;result = bpf_map_lookup_elem(&my_map, &key, &value);if(result == 0)printf("Value to read from the map: '%d'\n", value);elseprintf("Failed to read value from the map: %d (%s)\n", result, strerror(errno));
Lea el mapa desde el espacio del usuario:
int key, value, result;key = 1;result = bpf_map_lookup_elem(map_data[0].fd, &key, &value);if(result == 0)printf("Value to read from the map: '%d'\n", value);elseprintf("Failed to read value from the map: %d (%s)\n", result, strerror(errno));
El primer parámetro en bpf_map_lookup_elem se reemplazará con el descriptor de archivo asignado. La función auxiliar se comporta igual que el ejemplo anterior.
4.2.3 Eliminación de elementos del mapa BPF
BPF proporciona dos funciones auxiliares diferentes para eliminar elementos del mapa dependiendo de dónde se ejecute el programa. Ambos nombres de función son bpf_map_delete_element.
Elimine el valor insertado en el mapa del espacio del kernel:
int key, value, result;key = 1;result = bpf_map_delete_element(&my_map, &key);if(result == 0)printf("Element deleted from the map\n");elseprintf("Failed to delete element from the map: %d (%s)\n", result, strerror(errno));
Lea el mapa desde el espacio del usuario:
int key, value, result;key = 1;result = bpf_map_delete_element(map_data[0].fd, &key);if(result == 0)printf("Element deleted from the map\n");elseprintf("Failed to delete element from the map: %d (%s)\n", result, strerror(errno));
4.2.4 Iterando sobre elementos del mapa BPF
Encuentra cualquier elemento en BPF. BPF proporciona la instrucción bpf_map_get_next_key, que solo se aplica a los programas que se ejecutan en el espacio del usuario.
int next_key, lookup_key;lookup_key = -1;while(bpf_map_get_next_key(map_data[0].fd, &lookup_key, &next_key) == 0){printf("The next key in the map is: '%d'\n", next_key);lookup_key = next_key;}
4.2.5 Búsqueda y eliminación de elementos del mapa
bpf_map_lookup_and_delete_elem. Esta función es para encontrar la clave especificada en el mapa y eliminar el elemento. Al mismo tiempo, el programa asigna el valor del elemento a una variable.
int key, value, result, it;key = 1;for (it =0; it < 2; it++){result = bpf_map_lookup_and_delete_element(map_data[0].fd, &key, &value);if(result == 0)printf("Value read from the map: '%d'\n", value);elseprintf("Failed to read value from the map: %d (%s)\n", result, strerror(errno));}
4.2.6 Acceso simultáneo a elementos del mapa
Acceder a los mismos elementos del mapa al mismo tiempo puede crear condiciones de carrera en los programas BPF. BPF agrega el concepto de bloqueo de giro BPF, que puede bloquear los elementos del mapa a los que se accede cuando se operan los elementos del mapa. Los spinlocks solo están disponibles para arreglos, hash y mapas de almacenamiento de cgroup.
Hay dos funciones auxiliares en el kernel para usar con spinlocks: bpf_spin_lock lock, bpf_spin_unlock unlock. Los programas de usuario pueden usar el indicador BPF_F_LOCK.
El uso de un spinlock primero requiere crear el elemento al que desea bloquear el acceso y luego agregar una señal a ese elemento.
struct concurrent_element{struct bpf_spin_lock semaphore;int count;}
Podemos declarar un mapa que contenga estos elementos. El mapeo debe anotarse con el formato de tipo BPF (BTF) para que el validador sepa cómo interpretar el BTF. BTF puede proporcionar información más rica al kernel y otras herramientas al agregar información de depuración a los objetos binarios. En el kernel, podemos usar las macros del kernel de libbpf para anotar este mapa concurrente.
struct bpf_map_def SEC("maps") concurrent_map = {.type = BPF_MAP_TYPE_HASH,.key_size = sizeof(int),.value_size = sizeof(struct concurrent_element),.max_entries = 100,};BPF_ANNOTATE_KV_PAIR(concurrent_map, int, struct concurrent_element);
Utilice estas dos funciones auxiliares para proteger estos elementos de las condiciones de carrera.
5. Tipos de mapeo BPF
5.1 Mapeo de tablas hash
Las asignaciones de tablas hash son las primeras asignaciones de propósito general agregadas a BPF. El tipo de mapa se define como BPF_MAP_TYPE_HASH.
5.2 Mapeo de matrices
El mapa de matriz es el segundo mapa BPF agregado al kernel. El tipo de mapa se define como BPF_MAP_TYPE_ARRAY. Cuando se inicializa un mapa de matriz, todos los elementos se asignan previamente en la memoria y se establecen en cero. La clave es el índice en la matriz y debe tener exactamente cuatro bytes de tamaño. Los elementos de un mapa de matriz no se pueden eliminar.
5.3 Asignación de matriz de programas
El mapa de la matriz del programa se agrega al primer mapa dedicado del núcleo. El tipo de mapa se define como BPF_MAP_TYPE_PROC_ARRAY. Este tipo contiene una referencia al programa BPF, el descriptor de archivo del programa BPF. El tipo de mapeo de matriz de programa se puede usar junto con la función auxiliar bpf_tail_call para saltar entre programas, romper el límite de la instrucción máxima de un solo programa BPF y reducir la complejidad de la implementación. La clave y el valor deben tener un tamaño de cuatro bytes. Al saltar a un nuevo programa, el nuevo programa usará la misma pila de memoria, por lo que el programa no usará toda la memoria disponible. Si salta a un programa que no existe, la llamada final fallará y volverá a continuar con la ejecución del programa actual.
5.4 Asignación de matriz de eventos de rendimiento
Este mapa de tipos almacena datos de perf_events en un búfer de anillo para la comunicación en tiempo real entre programas BPF y programas de espacio de usuario.
El tipo de mapa se define como BPF_MAP_TYPE_PERF_EVENT_ARRAY. Puede reenviar eventos emitidos por herramientas de seguimiento del kernel a programas de espacio de usuario para su posterior procesamiento.
Declarar la estructura del evento:
struct data_t{u32 pid;char program_name[16];}
Cree una asignación para enviar eventos al espacio del usuario:
struct bpf_map_def SEC("maps") events = {.type = BPF_MAP_TYPE_PERF_EVENT_ARRAY,.key_size = sizeof(int),.value_size = sizeof(u32),.max_entries = 2,}
Después de declarar el tipo de datos y el mapeo, podemos crear un programa BPF para capturar los datos y enviarlos al espacio del usuario:
SEC("kprobe/sys_exec")int bpf_capture_exec(struct pt_regs *ctx){data_t data;data.pid = bpf_get_current_pid_tgid() >> 32;bpf_get_current_comm(&data.program_name, sizeof(data.program_name));bpf_perf_event_output(ctx, &events, 0, &data, sizeof(data));return 0;}
referencia
"Tecnología de observación del kernel de Linux BPF"
https://ebpf.io/zh-cn/