Presta atención, no te pierdas en productos secos 👆
Introducción
Este artículo aprende y comprende principalmente las características del mapa al explorar la estructura de datos y la implementación del código fuente del mapa en golang, incluida la exploración del modelo, el acceso y la expansión del mapa. Bienvenido a discutir juntos.
Modelo de memoria subyacente del mapa
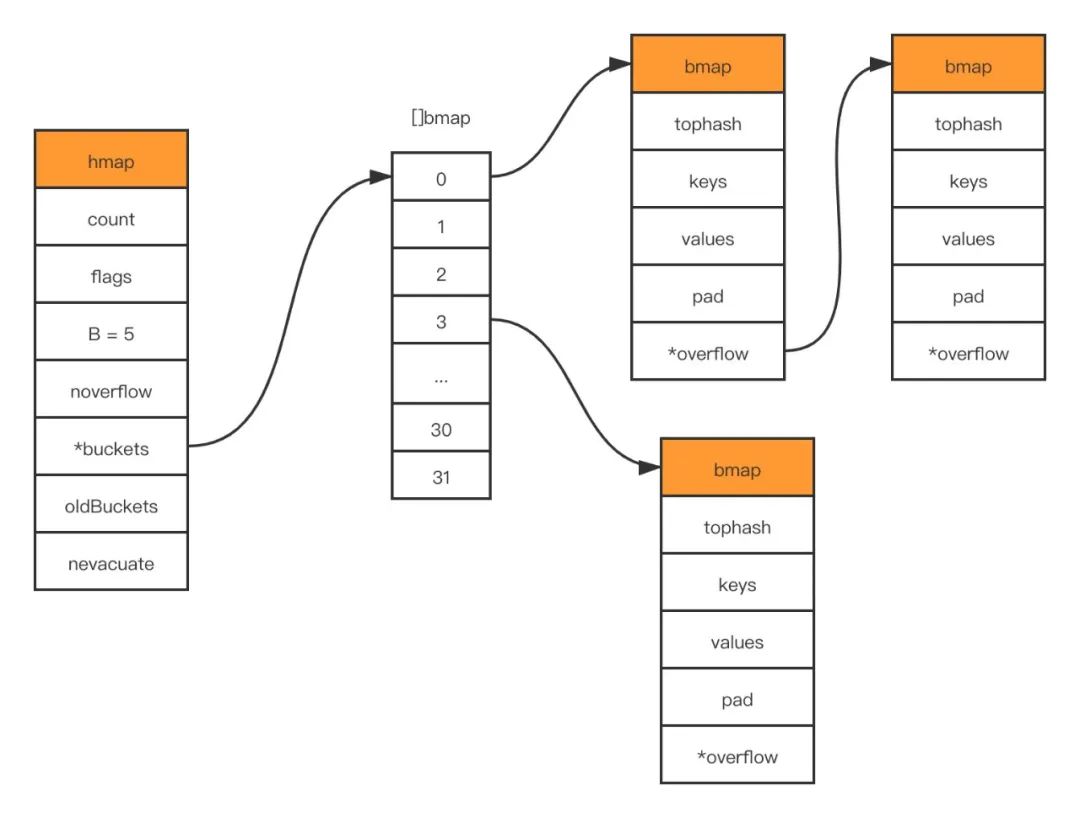
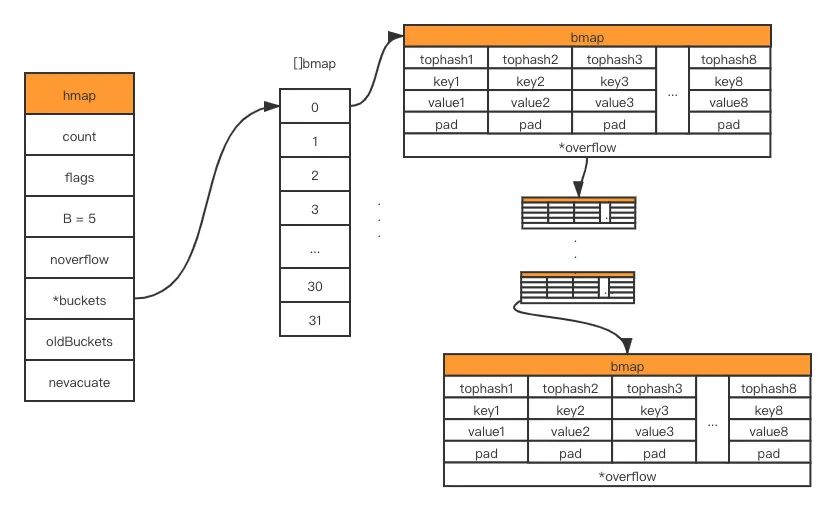
En el código fuente de golang, la estructura subyacente que representa el mapa es hmap, que es la abreviatura de hashmap
type hmap struct {
// map中存入元素的个数, golang中调用len(map)的时候直接返回该字段
count int
// 状态标记位,通过与定义的枚举值进行&操作可以判断当前是否处于这种状态
flags uint8
B uint8 // 2^B 表示bucket的数量, B 表示取hash后多少位来做bucket的分组
noverflow uint16 // overflow bucket 的数量的近似数
hash0 uint32 // hash seed (hash 种子) 一般是一个素数
buckets unsafe.Pointer // 共有2^B个 bucket ,但是如果没有元素存入,这个字段可能为nil
oldbuckets unsafe.Pointer // 在扩容期间,将旧的bucket数组放在这里, 新buckets会是这个的两倍大
nevacuate uintptr // 表示已经完成扩容迁移的bucket的指针, 地址小于当前指针的bucket已经迁移完成
extra *mapextra // optional fields
}
B es el logaritmo de la longitud de la matriz de cubetas, es decir, la longitud de la matriz de cubetas es 2^B. El cubo es esencialmente un puntero que apunta a un espacio de memoria, y la estructura a la que apunta es la siguiente:
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
}
Pero esta es solo la estructura de la superficie (src/runtime/hashmap.go), que se alimenta durante la compilación, creando una nueva estructura dinámicamente:
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr // 内存对齐使用,可能不需要
overflow uintptr // 当bucket 的8个key 存满了之后
}
bmap es la estructura de datos subyacente de lo que a menudo llamamos "cubos". Un cubo puede almacenar hasta 8 claves/valores. Map usa la función hash para obtener el valor hash para decidir a qué cubo asignar, y luego de acuerdo con la parte superior 8 bits del valor hash Encuentra dónde ponerlo en el cubo La
composición del mapa específico se muestra en la siguiente figura:
Almacenamiento y recuperación de mapas
En el mapa, el almacenamiento y la recuperación esencialmente están haciendo un trabajo, es decir:
-
Consulta donde se debe almacenar el k/v actual. -
Asignación/valor, así entendemos el posicionamiento de la llave en el mapa y entendemos el acceso.
código de bajo nivel
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool) {
// map 为空,或者元素数为 0,直接返回未找到
if h == nil || h.count == 0 {
return unsafe.Pointer(&zeroVal[0]), false
}
// 不支持并发读写
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
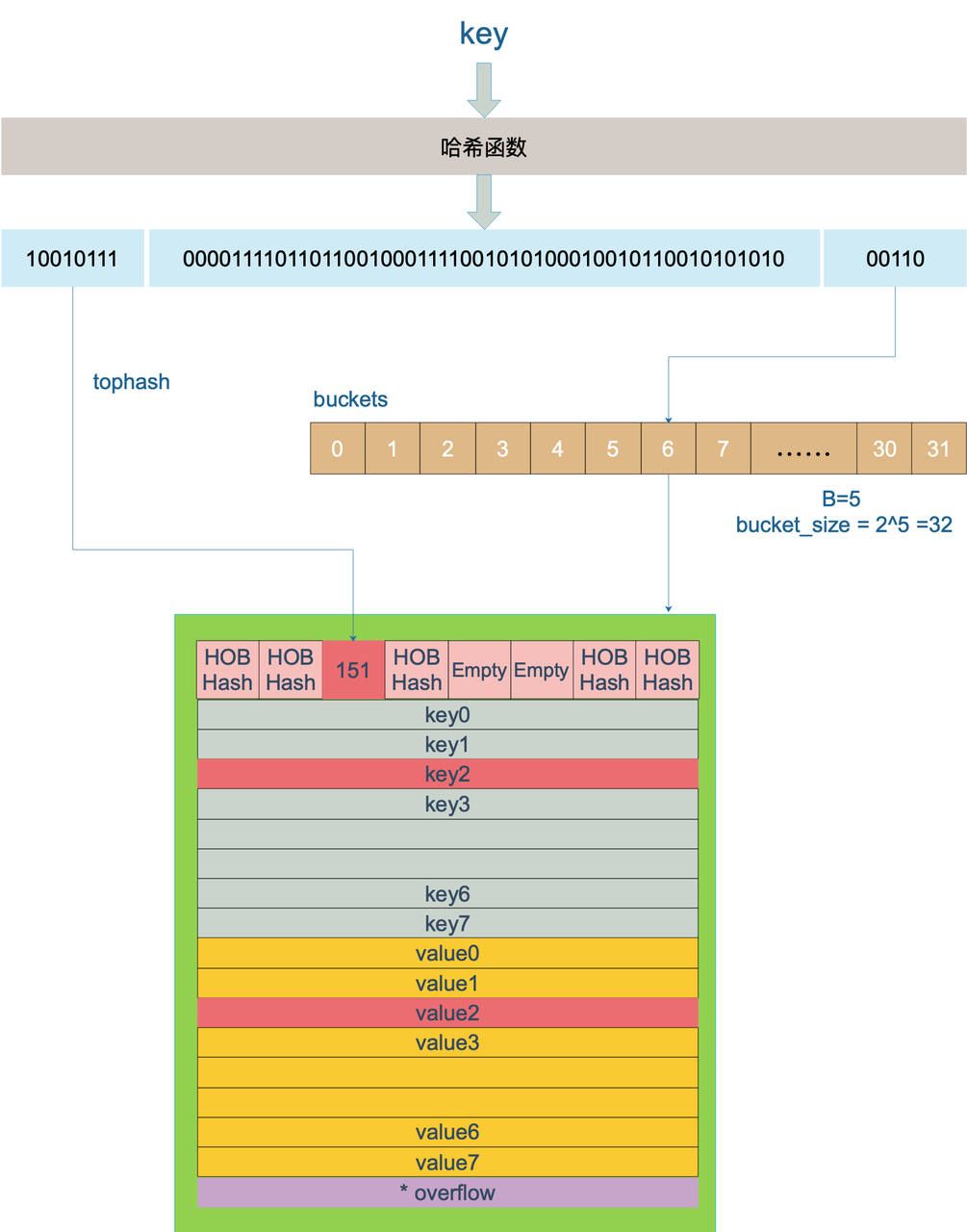
// 根据hash 函数算出hash值,注意key的类型不同可能使用的hash函数也不同
hash := t.hasher(key, uintptr(h.hash0))
// 如果 B = 5,那么结果用二进制表示就是 11111 , 返回的是B位全1的值
m := bucketMask(h.B)
// 根据hash的后B位,定位在bucket数组中的位置
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + (hash&m)*uintptr(t.bucketsize)))
// 当 h.oldbuckets 非空时,说明 map 发生了扩容
// 这时候,新的 buckets 里可能还没有老的内容
// 所以一定要在老的里面找,否则有可能发生“消失”的诡异现象
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// 说明之前只有一半的 bucket,需要除 2
m >>= 1
}
oldb := (*bmap)(unsafe.Pointer(uintptr(c) + (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
// tophash 取其高 8bit 的值
top := tophash(hash)
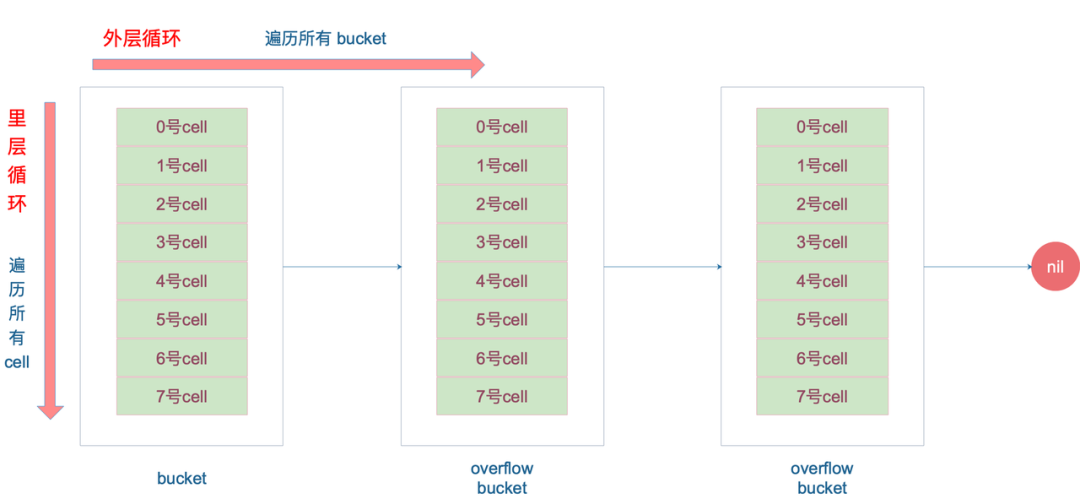
// 一个 bucket 在存储满 8 个元素后,就再也放不下了,这时候会创建新的 bucket,挂在原来的 bucket 的 overflow 指针成员上
// 遍历当前bucket的所有链式bucket
for ; b != nil; b = b.overflow(t) {
// 在bucket的8个位置上查询
for i := uintptr(0); i < bucketCnt; i++ {
// 如果找到了相等的 tophash,那说明就是这个 bucket 了
if b.tophash[i] != top {
continue
}
// 根据内存结构定位key的位置
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey {
k = *((*unsafe.Pointer)(k))
}
// 校验找到的key是否匹配
if t.key.equal(key, k) {
// 定位v的位置
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
if t.indirectvalue {
v = *((*unsafe.Pointer)(v))
}
return v, true
}
}
}
// 所有 bucket 都没有找到,返回零值和 false
return unsafe.Pointer(&zeroVal[0]), false
}
proceso de direccionamiento
Expansión del Mapa
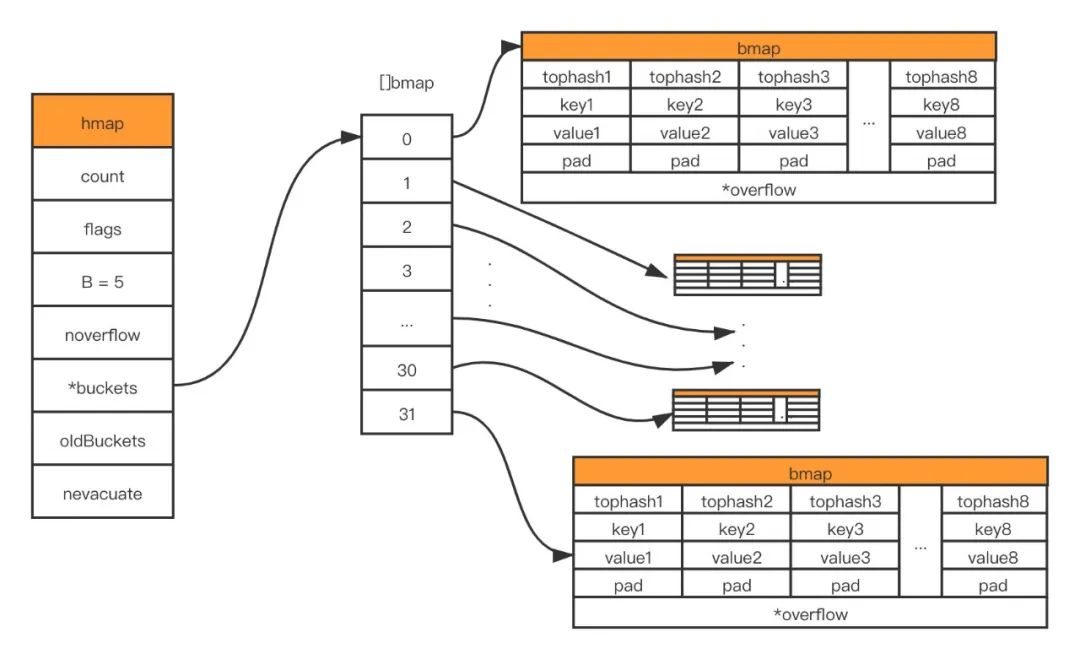
En golang, map y slice primero solicitan un pequeño espacio de memoria durante la inicialización y expanden dinámicamente la capacidad en el proceso de almacenamiento continuo de map. Hay dos tipos de expansión, expansión incremental y expansión igual (reorganizar y asignar memoria). Echemos un vistazo a cómo se activa la expansión:
-
El factor de carga supera el umbral y el umbral definido en el código fuente es 6,5. (Desencadenar expansión incremental) -
Demasiados cubos de desbordamiento: cuando B es inferior a 15, es decir, el número total de cubos 2^B es inferior a 2^15, si el número de cubos de desbordamiento supera los 2^B; cuando B >= 15, es decir, el número total de cubos 2^B es mayor o igual a 2^15, si el número de cubos de desbordamiento supera los 2^15. (activar expansión igual)
primer caso
segundo caso
Pedido de mapas
objMap := make(map[string]int)
for i := 0; i < 5; i++ {
objMap[strconv.Itoa(i)] = i
}
for i := 0 ; i < 5; i ++ {
var valStr1, valStr2 string
for k, v := range objMap {
fmt.Println(k)
fmt.Println(v)
valStr1 += k
}
for k, v := range objMap {
fmt.Println(k)
fmt.Println(v)
valStr2 += k
}
fmt.Println(valStr1 == valStr2)
if valStr1 != valStr2 {
fmt.Println("not equal")
}
}
fmt.Println("end")

-
Escenario de uso típico: un escenario de uso típico para el mapa es que no se requiere un acceso seguro desde varias rutinas. -
Escenarios atípicos (requiere operaciones atómicas): el mapa puede ser parte de una estructura de datos más grande o un cálculo ya sincronizado.
, // 不支持并发读写
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}