En una arquitectura de microservicios a gran escala, el monitoreo de servicios y el análisis en tiempo real requieren grandes cantidades de datos de series temporales. La forma más eficiente de almacenar estos datos de series temporales es utilizar una base de datos de series temporales (TSDB). Uno de los desafíos importantes en el diseño de bases de datos de series temporales es encontrar un equilibrio entre eficiencia, escalabilidad y confiabilidad. Este documento presenta la base de datos de series temporales en memoria, Gorilla, incubada dentro de Facebook. El equipo de Facebook encontró:
-
Los usuarios de los sistemas de vigilancia se preocupan principalmente por el análisis agregado de datos en lugar de puntos de datos individuales. -
Los datos recientes son más valiosos que los datos anteriores para el análisis de la causa raíz de los problemas en línea
Gorilla está optimizado para una alta disponibilidad de lectura y escritura a costa de potencialmente desechar una pequeña cantidad de datos. Para mejorar la eficiencia de las consultas, el equipo de desarrollo utilizó técnicas de compresión agresivas:
-
marcas de tiempo delta de delta -
Valores de punto flotante XOR'd
En comparación con las soluciones basadas en HBase, Gorilla reduce el consumo de memoria 10 veces y permite que los datos se almacenen en la memoria, lo que reduce la latencia de las consultas 73 veces y aumenta el rendimiento de las consultas 14 veces. Estas mejoras de rendimiento también desbloquean más herramientas de supervisión y depuración, como el análisis de correlación y la visualización intensiva. Gorilla puede incluso resolver con gracia fallas de un solo punto a toda la zona de disponibilidad.
introducir
Los siguientes son los requisitos internos del FB para la base de datos de series temporales:
escribir dominar
La primera restricción en las bases de datos de series temporales es que los datos deben poder escribirse todo el tiempo, es decir, la alta disponibilidad de datos de escritura. Porque el clúster de servicios dentro de FB generará 10 millones de puntos de datos de muestra por segundo. Por el contrario, la lectura de datos suele ser varios órdenes de magnitud menor que la escritura de datos, porque los consumidores de datos son algunos paneles de control para operación y mantenimiento, desarrollo y uso, y sistemas automáticos de alarma, que tienen una frecuencia de solicitud baja y generalmente solo se enfocan en parte. de los datos de la serie temporal. Dado que los usuarios a menudo se preocupan por los resultados agregados de todo el conjunto de datos de series temporales, en lugar de un solo punto de datos, las garantías ACID en las bases de datos tradicionales no son los requisitos principales de las bases de datos de series temporales. Incluso en casos extremos, descartar una pequeña cantidad de Los datos no afectarán al núcleo.
Transición de estado
FB espera descubrir algunos eventos de transición de estado del sistema a tiempo, como:
-
Nueva versión del servicio lanzada -
Modificación de la configuración del servicio -
conmutador de red -
...
Por lo tanto, se requiere que la base de datos de series de tiempo admita la agregación detallada de datos muestreados dentro de una ventana de tiempo breve. Tener la capacidad de mostrar los eventos de transición de estado capturados en diez segundos puede ayudar a las herramientas automatizadas a identificar rápidamente los problemas y evitar que se propaguen.
Alta disponibilidad
Incluso cuando se produce una partición de red entre diferentes DC, los servicios dentro del DC deberían poder escribir datos de monitoreo en tiempo real en la base de datos de series temporales dentro del DC y también poder leer datos de ella.
Tolerancia a fallos
Tener la capacidad de replicar datos en varias regiones puede funcionar bien en caso de que surja un problema con un solo DC o una región geográfica completa.
Gorilla es una base de datos de series temporales desarrollada para cumplir con todos los requisitos anteriores. Puede entenderse como una caché de escritura simultánea de datos de series temporales. Dado que los datos están en la memoria, Gorilla puede procesar la mayoría de las solicitudes en 10 milisegundos. A través de la investigación sobre el almacén de datos operativos (ODS, solución de base de datos de series temporales basada en HBase) que se ha utilizado en FB durante mucho tiempo, se encontró que más del 85% de las consultas de datos solo involucran datos generados en las últimas 26 horas. Se encuentra que si se usa la base de datos en memoria en lugar de la base de datos basada en disco, se pueden cumplir los requisitos de tiempo de respuesta del usuario.
En la primavera de 2015, el sistema de monitoreo dentro de FB generó más de 2 mil millones de conjuntos de series temporales, 12 millones por segundo y 1 billón de puntos de datos por día. Suponiendo que cada punto de muestra requiera 16 bytes de almacenamiento, eso significa 16 TB de memoria por día. El equipo de Gorilla redujo la cantidad de bytes requeridos por punto de muestra a 1,37 a través de un algoritmo de compresión de punto flotante basado en XOR, lo que redujo el requisito de memoria total en un factor de casi 12.
Para cumplir con los requisitos de disponibilidad, el equipo de Gorilla implementa varias instancias de Gorilla en diferentes regiones y DC Los tiempos de las instancias sincronizan los datos entre sí, pero no se garantiza la consistencia. Las solicitudes de lectura de datos se reenviarán a la instancia de Gorilla más cercana.
Antecedentes y necesidades
SAO
ODS es una parte importante del sistema de monitoreo de servicios en línea de FB, que consta de una base de datos de series temporales basada en HBash, servicio de consulta de datos y sistema de alarma. Su arquitectura general se muestra en la siguiente figura:
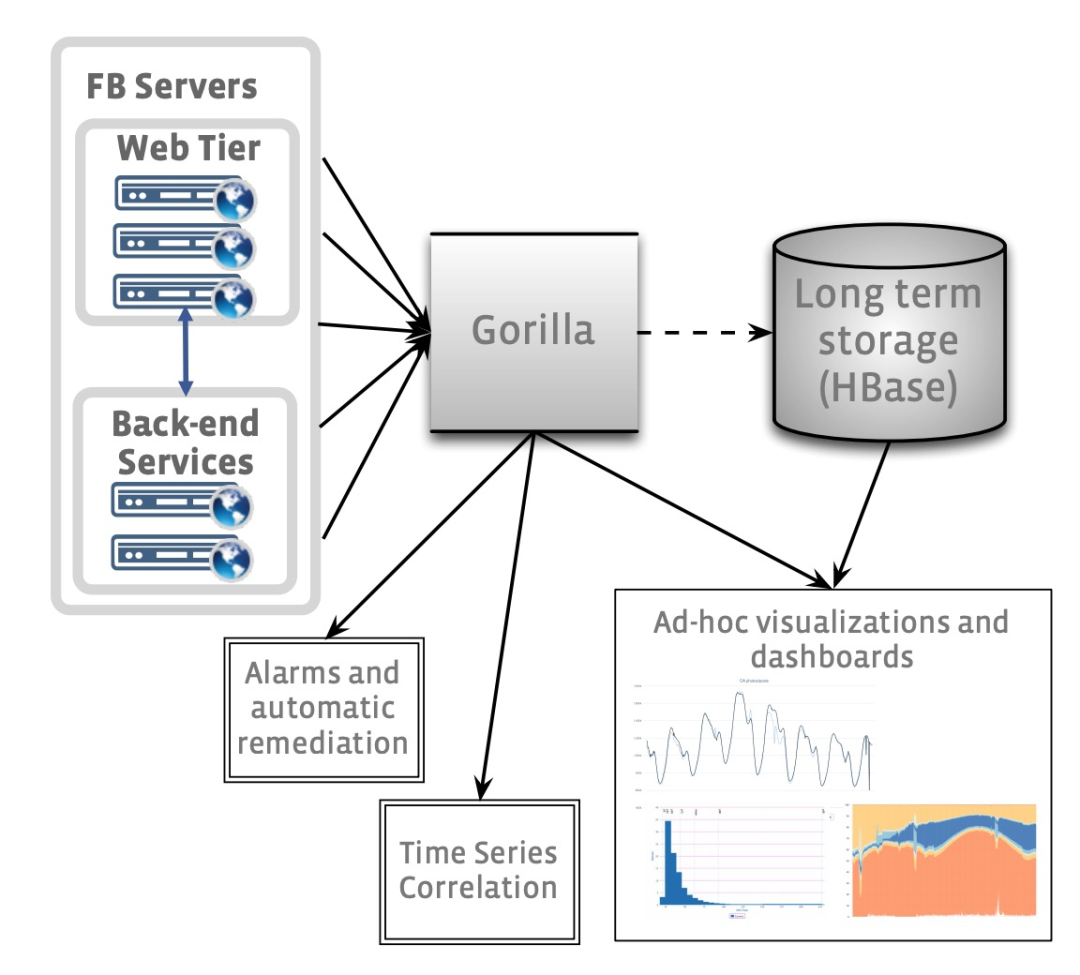
Los consumidores de SAO se componen principalmente de dos partes:
-
Sistema de gráficos interactivos para que los desarrolladores analicen problemas -
Sistema de alarma automático
A principios de 2013, el equipo de monitoreo de FB se dio cuenta de que la base de datos de series temporales basada en HBase no podía manejar la carga de lectura futura. Aunque la demora de la consulta de datos durante el análisis de iconos era tolerable, el cuantil 90 de la consulta de varios segundos había bloqueado la alarma automática. .de funcionamiento normal. Con otras soluciones listas para usar hoy en día, el equipo de monitoreo centró su atención en las soluciones de almacenamiento en caché. Aunque ODS utiliza una caché de lectura simple, esta solución solo almacena en caché los datos de series temporales comunes en varios gráficos, pero cada vez que el gráfico consulta los datos más recientes, seguirá habiendo una falla de caché, momento en el que se leen los datos. HBase. El equipo de monitoreo también consideró usar Memcache como un caché de escritura directa, pero escribir una gran cantidad de los datos más recientes cada vez generaría mucho tráfico en Memcache, y esta solución finalmente fue rechazada. Los equipos de monitoreo necesitan soluciones más eficientes.
Gorila necesita
La siguiente es una declaración de requisitos para la nueva solución:
-
2 mil millones de conjuntos de datos de series temporales diferentes, cada conjunto de datos de series temporales se identifica mediante una cadena única -
700 millones de muestras de datos por minuto -
Ahorre 26 horas de datos completos -
Lectura de datos completada en 1 ms -
El intervalo de muestreo mínimo admitido es de 15 s. -
Dos nodos de réplica para admitir la tolerancia a fallas, incluso si un nodo muere, puede continuar procesando solicitudes de lectura -
Capacidad para escanear rápidamente todos los datos de la memoria -
Soporta el doble de crecimiento anual
Comparación con otros sistemas TSDB
Debido a que Gorilla está diseñado para mantener todos los datos en la memoria, su estructura de datos en memoria es diferente de otras bases de datos de series temporales. Gracias a este diseño, los desarrolladores también pueden pensar en Gorilla como un caché de escritura directa para bases de datos de series temporales basadas en disco.
OpenTSDB
OpenTSDB es una solución de base de datos de series temporales que continúa con HBase, que es muy similar a la capa de almacenamiento HBase de ODS. El diseño de la estructura de la mesa de los dos sistemas es muy similar, y también se adoptan soluciones similares de optimización y expansión horizontal. Sin embargo, como se mencionó anteriormente, las soluciones basadas en disco son difíciles de respaldar la necesidad de consultas rápidas. La capa de almacenamiento HBase de ODS reducirá deliberadamente la precisión de muestreo de los datos antiguos, ahorrando así la ocupación general del espacio; OpenTSDB guardará la precisión total de los datos. Sacrificar la precisión de los datos antiguos puede generar una mayor velocidad de consulta de datos antiguos y ahorro de espacio, lo que el equipo de FB cree que vale la pena. El modelo de datos de OpenTSDB para identificar datos de series temporales es más rico que el de Gorilla, y cada grupo de datos de series temporales se puede etiquetar con cualquier grupo de datos clave-valor, las llamadas etiquetas. Gorilla solo usa una cadena para marcar datos de series temporales y se basa en la capa superior para extraer la información que identifica los datos de series temporales.
Susurro (Grafito)
Graphite almacena datos de series temporales en un disco local en formato Whisper. El formato de susurro espera que el intervalo de muestreo de los datos de la serie temporal sea estable, si el intervalo de muestreo tiembla, Graphite no puede hacer nada. Por el contrario, si el intervalo de muestreo de los datos de la serie temporal es estable, Gorilla puede almacenar los datos de manera más eficiente y Gorilla también puede manejar intervalos inestables. En Graphite, cada conjunto de datos de series temporales existe en un archivo separado, y los nuevos puntos de muestra sobrescriben los datos antiguos durante un cierto período de tiempo; Gorilla es similar, pero la diferencia es que almacena los datos en la memoria. Dado que Graphite es una base de datos de series temporales basada en disco, tampoco cumple con los requisitos internos de FB.
InflujoDB
El modelo de datos de InfluxDB es más expresivo que OpenTSDB, y cada muestra de la serie temporal puede tener metadatos completos, pero este enfoque también hace que el almacenamiento de datos ocupe más espacio en disco. InfluxDB también admite la implementación de clústeres y la expansión horizontal, y el equipo de operación y mantenimiento no necesita administrar clústeres de HBase/Hadoop. Ya existe un equipo dedicado en FB responsable de operar y mantener el clúster de HBase, por lo que este no es un problema para el equipo de ODS. Al igual que otros sistemas, InfluxDB también almacena datos en disco y su eficiencia de consulta es mucho menor que la de las bases de datos en memoria.
Arquitectura Gorila
En Gorilla, cada muestra de datos de serie temporal consta de un triple:
-
clave de cadena: se utiliza para identificar la serie temporal a la que pertenece -
marca de tiempo (int64): marca de tiempo -
valor (float64): valor de muestra
Gorilla utiliza un nuevo algoritmo de compresión de series temporales que reduce el espacio necesario para almacenar cada muestra de datos de series temporales de los 16 bytes anteriores a un promedio de 1,37 bytes.
Al fragmentar cada conjunto de datos de series temporales en un determinado servicio de Gorilla a través de una clave de cadena, se puede lograr fácilmente la expansión horizontal. Dieciocho meses después del lanzamiento oficial de Gorilla, se requieren alrededor de 1,3 TB de memoria para almacenar 26 horas de datos, y cada clúster requiere 20 máquinas. Al momento de escribir, cada clúster ya requiere 80 máquinas.
Gorilla protege contra puntos únicos de falla, particiones de red e incluso fallas completas de DC al escribir simultáneamente datos de series temporales en dos máquinas en diferentes regiones. Una vez que se encuentra una falla, todas las solicitudes de lectura se reenviarán al servicio en la región alternativa para garantizar que los usuarios no tengan una percepción obvia de la falla.
compresión de series de tiempo
Gorilla tiene dos requisitos principales para el algoritmo de compresión:
-
Compresión de transmisión: no es necesario leer los datos completos -
Compresión sin pérdida: sin pérdida de precisión de datos
Comparando el análisis de datos de muestra continua, se puede observar que:
-
El intervalo entre marcas de tiempo consecutivas suele ser constante, como 15 segundos -
La diferencia de codificación binaria entre valores de datos consecutivos es pequeña
Entonces, Gorilla usa diferentes algoritmos de compresión para marcas de tiempo y valores de datos. Antes de analizar el algoritmo específico, puede observar el proceso general del algoritmo:
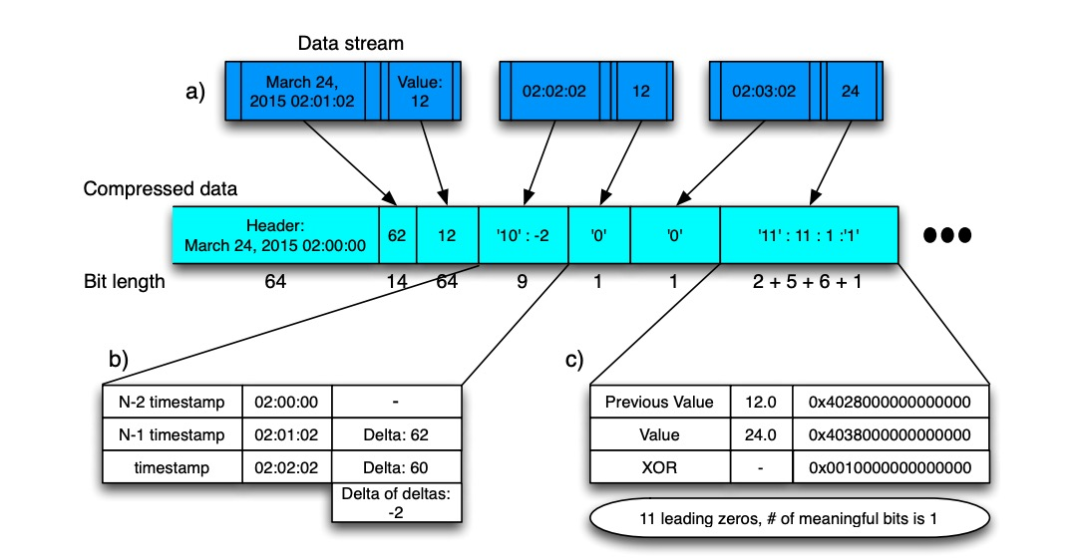
-
La marca de tiempo de inicio se registra al comienzo de cada bloque de datos -
Los primeros datos de muestra -
La marca de tiempo almacena la diferencia con la marca de tiempo de inicio -
Los valores de los datos se almacenan tal cual -
Comience con los datos de la segunda muestra -
La marca de tiempo almacena delta de delta -
Los valores de los datos se almacenan como diferencias.
Compresión de marcas de tiempo
Al analizar los datos de series temporales en el ODS, el equipo de Gorilla observó que la mayoría de las muestras de series temporales llegan al servicio en intervalos fijos, como 60 segundos. La ventana de tiempo es generalmente estable, aunque hay retrasos o avances ocasionales de 1 segundo.
Suponiendo que el delta de las marcas de tiempo continuas es: 60, 60, 59, 61, entonces el delta del delta es: 0, -1, 2, así que a través de la hora de inicio, el delta de los primeros datos y la hora de inicio, y todo el resto El delta del delta del punto de muestra puede almacenar los datos completos.
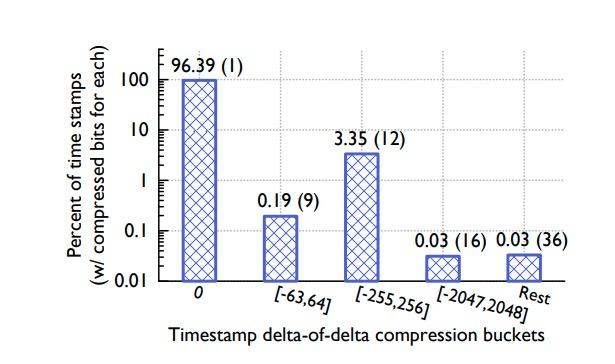
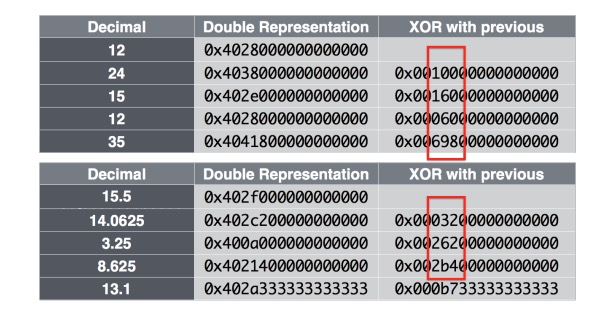
El intervalo seleccionado para D en el algoritmo puede obtener la máxima relación de compresión sobre los datos reales. Los datos de una serie temporal pueden perder puntos de datos en cualquier momento, por lo que puede aparecer una secuencia delta de este tipo: 60, 60, 121, 59. En este momento, el delta del delta es: 0, 61, -62 y 10 bits de datos necesita ser almacenado. La siguiente figura muestra el rendimiento estadístico de la compresión de temporización:
Compresión de valores
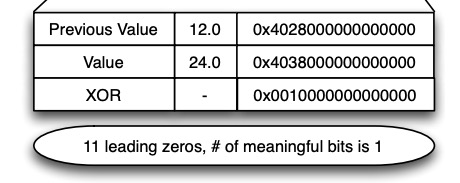
Al analizar los datos de ODS, el equipo de Gorilla observó que la mayoría de los valores de datos de series temporales adyacentes no varían significativamente. Según el formato de codificación de punto flotante definido en IEEE 754:
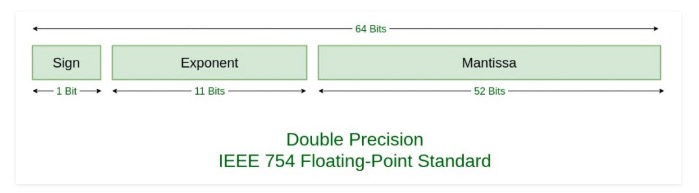
Por lo general, entre valores adyacentes, algunos bits delante del signo, el exponente y la mantisa no cambiarán, como se muestra en la siguiente figura:
Entonces, usando esto, podemos comprimir los datos registrando la información diferente en el XOR de valores adyacentes. El flujo completo del algoritmo es el siguiente:
-
El primer valor se almacena sin comprimir -
Si el resultado de XOR con el valor anterior es 0, es decir, el valor no ha cambiado, almacena 1 bit, '0' -
Si el resultado de XOR con el valor anterior no es 0, almacene 1 bit primero, '1' -
(Bit de control '0'): si el intervalo XOR actual está en el intervalo XOR anterior, la información de posición del intervalo XOR anterior se puede reutilizar y solo se almacena el valor XOR dentro del intervalo -
(Bit de control '1'): si el intervalo XOR actual no está en el intervalo XOR anterior, primero use 5 bits para almacenar el número de prefijo 0, luego use 6 bits para almacenar la longitud del intervalo y finalmente almacene el XOR valor dentro del intervalo
Para obtener más información, consulte el ejemplo del diagrama de flujo, a saber:
La siguiente figura muestra el rendimiento estadístico del algoritmo de compresión de valores de datos de series temporales:
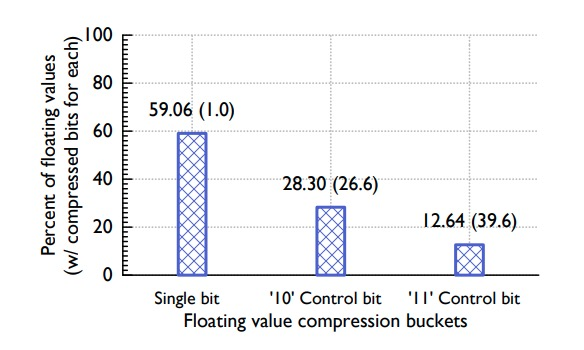
-
El 59% de los valores necesitan solo 1 bit para almacenar -
El 28% de los valores necesitan solo 26,6 bits para almacenar -
El 13% de los valores requieren 39,6 bits para almacenar
Hay una compensación a considerar aquí: el lapso de tiempo cubierto por cada bloque de datos. Un lapso de tiempo mayor puede obtener una tasa de compresión más alta, pero cuantos más recursos se requieran para la descompresión, los resultados estadísticos específicos se muestran a continuación:
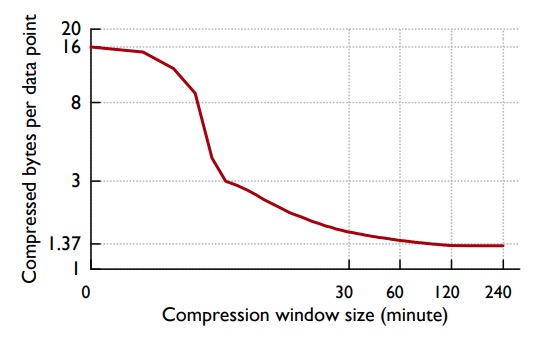
En la figura se puede ver que después de 2 horas, el beneficio marginal de aumentar la tasa de compresión al aumentar el lapso ya es muy pequeño, por lo que Gorilla finalmente elige un lapso de tiempo de 2 horas.
estructuras de datos en memoria
La estructura de datos en memoria de Gorilla se muestra a continuación
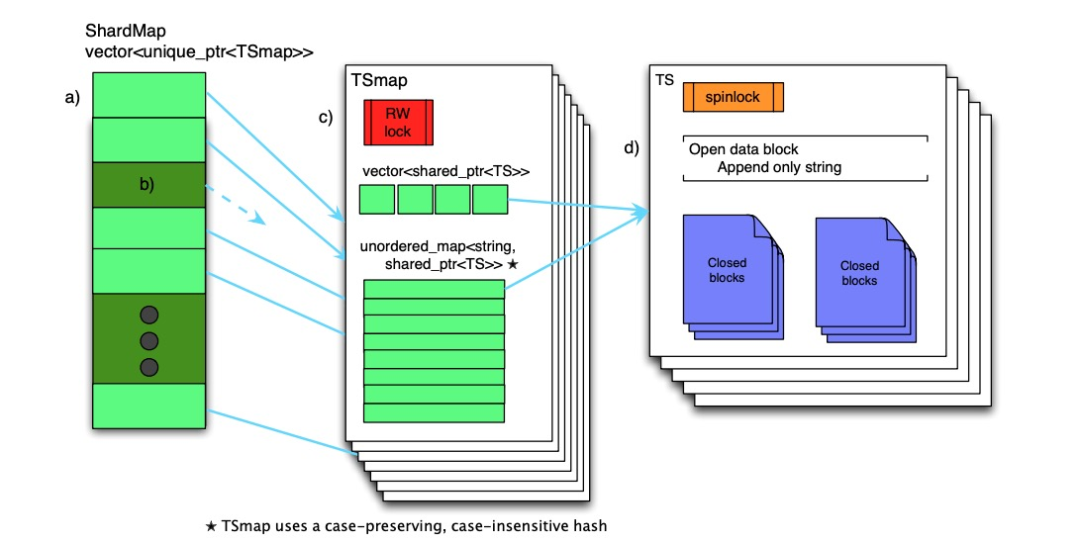
Toda la estructura de datos se puede dividir en tres capas:
-
FragmentoMapa -
TSmap -
TS
FragmentoMapa
Se mantiene un ShardMap en cada nodo Gorilla, que es responsable de asignar el valor hash del nombre de la serie temporal al TSmap correspondiente. Si el puntero correspondiente en ShardMap está vacío, los datos de la serie temporal de destino no están en el nodo actual (fragmento). Dado que la cantidad de fragmentos en el sistema es constante y se espera que sea del orden de 3 dígitos, el costo de almacenar un ShardMap es bajo. El acceso simultáneo a ShardMap se controla mediante un bloqueo giratorio de lectura y escritura.
TSmap
TSmap es un índice de datos de series temporales. Consta de las siguientes dos partes:
-
Un vector de punteros a todos los TS, marcados como vector -
Un diccionario que asigna hashes de nombres de series temporales a punteros TS, mapa etiquetado
El vector se usa para escanear rápidamente todos los datos; el mapa se usa para satisfacer solicitudes de consulta rápidas y estables. El control de concurrencia de TSmap se implementa a través de un bloqueo giratorio de lectura y escritura. Al escanear datos completos, solo necesita copiar el vector, que está compuesto por un lote de punteros, que es muy rápido y tiene una pequeña sección crítica; al eliminar datos, se eliminan mediante marcas de desecho y se reciclan pasivamente.
TS
Cada conjunto de datos de series temporales se compone de una serie de bloques de datos, cada bloque de datos guarda 2 horas de datos, el último bloque de datos aún está abierto y los datos más recientes se mantienen en él. Los datos solo se pueden agregar al último bloque de datos. Una vez que hayan transcurrido 2 horas, el bloque de datos se cerrará. El bloque de datos cerrado no se puede modificar hasta que se borre la memoria.
Al leer los datos, todos los bloques de datos involucrados en la consulta se copiarán y devolverán directamente al cliente RPC.El cliente completa el proceso de descompresión de los datos.
estructura del disco
Uno de los objetivos de diseño de Gorilla es ser resistente a puntos únicos de falla, por lo que Gorilla también necesita usar almacenamiento persistente para la recuperación de fallas. El almacenamiento persistente elegido por Gorilla es GlusterFS, que es un sistema de archivos distribuido compatible con POSIX con 3 copias de seguridad predeterminadas. También se pueden utilizar otros sistemas de archivos distribuidos, como HDFS. El equipo de Gorilla también consideró usar MySQL o RocksDB independientes, pero finalmente no tuvo otra opción porque Gorilla no requería soporte de lenguaje de consulta.
Un nodo Gorilla mantendrá datos para múltiples fragmentos, por lo que creará una carpeta para cada fragmento. Cada carpeta contiene cuatro tipos de archivos:
-
Listas clave -
Registros de solo anexar -
Archivos de bloques completos -
Archivos de puntos de control
Listas clave
Key Lists es en realidad una asignación de nombres de temporización a identificadores enteros, que son los valores de compensación de temporizaciones en el vector TSmap. Gorilla actualiza periódicamente los datos de las listas de claves.
Registros de solo anexar
A medida que todas las muestras de datos de series temporales fluyen hacia los nodos de Gorilla, Gorilla escribe sus datos comprimidos intercalados en el archivo de registro. Pero el archivo de registro aquí no es WAL, y Gorilla no tiene la intención de proporcionar compatibilidad con ACID. Cuando los datos de registro tengan 64 KB completos en la memoria, se agregarán al archivo de registro correspondiente en GlusterFS. En caso de falla, es probable que se pierda una pequeña cantidad de datos, pero vale la pena el sacrificio para mejorar el rendimiento de escritura.
Archivos de bloques completos
Cada 2 horas, Gorilla comprime los bloques y los copia en GlusterFS. Cada vez que se conserva un dato, Gorilla crea un archivo de punto de control y elimina el archivo de registro correspondiente. El archivo de punto de control se usa para identificar si la persistencia del bloque de datos fue exitosa o no. Durante la conmutación por recuperación, Gorilla carga datos anteriores a través de puntos de control y archivos de registro.
Tolerancia a fallos
En términos de tolerancia a fallas, Gorilla admite preferentemente los siguientes escenarios:
-
Punto único de falla, si es una falla temporal, el cliente no se da cuenta, a menudo se usa para lanzamientos de nuevas versiones -
Fallas regionales a gran escala: como particiones de red en toda la región
Alta disponibilidad
Gorilla mantiene la disponibilidad del servicio al mantener dos instancias separadas en DC en dos regiones diferentes. Cuando se escribe el mismo conjunto de datos secuenciales, se enviará a estas dos instancias independientes, pero no se garantiza la atomicidad de las dos operaciones de escritura. Cuando una región falla, las solicitudes de lectura se intentarán en la otra región. Si la región falla durante más de 1 minuto, no se le enviarán solicitudes de lectura hasta que los datos de la instancia en la región se hayan escrito normalmente durante 26 horas.
Dentro de cada zona, se utiliza un ShardManager basado en Paxos para mantener la relación entre fragmentos y nodos. Cuando falla un nodo, ShardManager redistribuye los fragmentos que mantiene a otros nodos dentro del clúster. La transferencia de fragmentos generalmente se puede completar en segundos 30. Durante el proceso de transferencia de fragmentos, el cliente que escribe los datos almacenará en caché los datos que se escribirán y almacenará en caché los datos de último minuto como máximo. Cuando el cliente descubre que la operación de transferencia de fragmentos se completó, el cliente vaciará inmediatamente el caché y escribirá los datos en el nodo. Si la transferencia de fragmentos es demasiado lenta, las solicitudes de lectura se pueden reenviar manual o automáticamente a otra región.
Cuando se asigna un nuevo fragmento a un nodo, ese nodo necesita leer todos los datos de GlusterFS. Por lo general, lleva 5 minutos cargar y preprocesar estos datos. Mientras el nodo está recuperando datos, los datos de muestra de serie temporal recién escritos se colocan en una cola pendiente. Después de que falla el nodo anterior, la solicitud de lectura puede leer parte de los datos y marcarlos antes de que el nuevo nodo haya terminado de cargar los datos del fragmento. Si el cliente encuentra que los datos están marcados como datos parciales, volverá a solicitar los datos en otra área y devolverá estos últimos si los datos están completos, y devolverá dos conjuntos de datos parciales si falla.
Finalmente, FB todavía usa HBase TSDB para almacenar datos a largo plazo, y los ingenieros aún pueden usarlo para analizar datos de series temporales pasadas.
Nuevas herramientas en Gorilla
Dado que los datos de Gorilla se mantienen en la memoria, esto permite un análisis más en tiempo real.
-
El motor de análisis de correlación se utiliza principalmente para descubrir rápidamente datos de series temporales altamente correlacionados para ayudar en el análisis de causa raíz. -
dibujo de monitor -
Análisis agregado
Dirección en papel: http://www.vldb.org/pvldb/vol8/p1816-teller.pdf
Traducción original: https://zhenghe.gitbook.io/open-courses/papers-we-love/gorilla-a-fast-scalable-in-memory-time-series-database