Supervisar el curso del desarrollo.
negocio en etapa temprana
No hay monitoreo, todos miran manualmente la red del software del sistema operativo del servidor, etc.
Empresa en etapa inicial
Supervisión de secuencias de comandos semiautomáticas, utilizando una forma similar de secuencia de comandos de shell, para realizar la secuencia de comandos de supervisión más simple, iniciar sesión en la máquina en un bucle para comprobar algunos estados y luego grabar manualmente, sin alarma, sin automatización y sin gráficos de supervisión.
empresa a mediano plazo
Los programas/scripts/software/supervisión automatizados, la actualización y el reemplazo de scripts comenzaron a utilizar varios programas de software de código abierto y no abierto para construir y desarrollar la supervisión, transformar la supervisión en gráficos, agregar un sistema de alarma y tener una cierta supervisión. Realización automática , el monitoreo en esta etapa comienza a tomar forma gradualmente pero aún carece de la fineza de la precisión y la alarma de estabilidad.
Empresas de etapa media y tardía
Monitoreo de clúster de varias soluciones de monitoreo de ayuda exterior.
El monitoreo comenzó a ser autónomo y se agregaron varias automatizaciones. Además de los sistemas de monitoreo desarrollados y construidos por nosotros mismos, se usarán ampliamente varios monitoreos periféricos (monitoreo de varios productos básicos, como el monitoreo de monitoreo de computación en la nube Baoyoumeng, etc.) para
monitorear el desarrollo del monitoreo interno + monitoreo externo (el monitoreo interno es el monitoreo de uso propio incorporado, el monitoreo externo es un producto de monitoreo comercial que utiliza asistencia externa para monitorear la interfaz más externa del producto y el comportamiento del usuario a un nivel más macro)
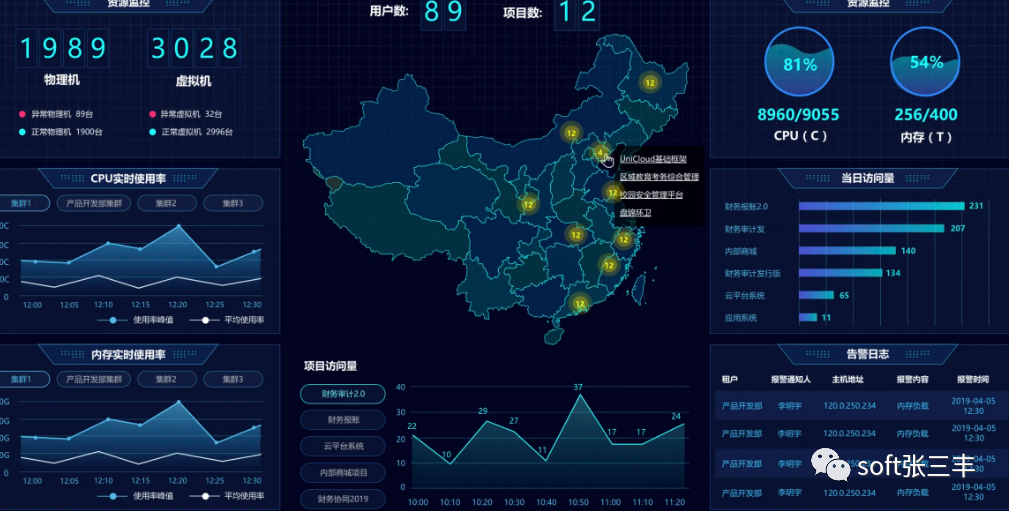
Monitoreo actual y futuro
De acuerdo con el estado de desarrollo actual,
el monitoreo futuro se mejorará continuamente en varios
-
Supervisión de la precisión de la autenticidad
-
Supervisión Automatización altamente integrada desatendida
-
Reducción incremental en los costos de monitoreo
-
Integración de monitorización y CMDB y desarrollo de sistemas de autorreparación
Con la construcción continua de operación y mantenimiento inteligente empresarial, CMDB es cada vez más importante como un medio importante de gobierno de datos de operación y mantenimiento. La gestión de configuración tradicional tiene problemas como la mala calidad de los datos, los escenarios de consumo único y la incapacidad para dar soporte a los negocios. El producto de gestión de configuración (CMDB) gestiona los metadatos de la operación y el mantenimiento de TI de la empresa y garantiza la exactitud de los datos, y promueve la implementación de escenarios de consumo de datos relacionados con el monitoreo de la operación y el mantenimiento, la gestión del servicio, la automatización de la operación y el mantenimiento y el análisis de la operación con soporte de datos configurable y mantenible.
La tecnología y las herramientas que actualmente son prácticas para la empresa.
-
Supervisión de secuencias de comandos (actualmente, las empresas que aún utilizan la forma más primitiva de ejecución de secuencias de comandos para la recopilación y la supervisión aún no son infrecuentes
para ahorrar costos) -
Herramientas de monitoreo de código abierto/no abierto como: Nagios / Cacti / icinga / Zabbix / Ntop / prometheus / etc.
-
Sistema de alarma: Pagerduty / sistema de alarma por voz autoconstruido / sistema de correo autoconstruido / notificación por SMS autoconstruida / varios productos de alarma comerciales
Supervisar algunos de los problemas a los que se enfrenta actualmente
-
La automatización de la vigilancia aún no es suficiente
-
Rara vez se integra perfectamente con CMDB
-
El monitoreo aún requiere mucha mano de obra
-
La precisión y la autenticidad del monitoreo están mejorando lentamente
-
La formulación de herramientas y programas de monitoreo es relativamente descuidada
-
El énfasis en el monitoreo en sí aún debe mejorarse
La vigilancia ideal del futuro
-
Sistema completo de monitoreo de autorreparación
Después de todo, el monitoreo y las alarmas solo pueden encontrar problemas. Lidiar con problemas después de que ocurren aún requiere mucha intervención manual.
En el futuro, cuando se perfeccione el sistema de autorreparación, los problemas en varios niveles serán reparados por diversas tecnologías, como la integración continua automática y el almacenamiento en búfer del sistema de recuperación de desastres de inteligencia artificial.
-
Monitoreo de enlace verdadero
Un modelo idealizado de la precisión del monitoreo y alerta desarrollado hasta el nivel final.
Por ejemplo: cuando el sistema envía información de alarma, a menudo se envían juntas una gran cantidad de alarmas en varios niveles para encubrir el problema real, lo que es muy desfavorable para que podamos encontrar y tratar el problema en tiempo real.
Por ejemplo, el problema real es que una nueva consulta conjunta de la base de datos consume demasiados recursos del sistema, lo que resulta en una gran cantidad de recursos en todos los aspectos que se consumen e indirectamente causan varios problemas de enlace.
Como resultado, las alarmas en varios niveles se suceden una tras otra, como alarmas de registro, alarmas de consulta lenta, alarmas de memoria de CPU de base de datos, alarmas de acumulación de enlace TCP de capa de programa y alarmas de código de retorno HTTP 5xx 499.
Todas las alarmas de caché de CPU del sistema, alarmas de caída de tráfico de usuario de monitoreo de nivel empresarial.
Todos los tipos de alarmas que se han activado han sido expuestos. Como resultado, la verdadera razón detrás de esta consulta de bane DB no se encontró mediante el monitoreo o se encontró, pero se sumergió por completo.
El último sistema de alarma ideal para el futuro puede ignorar todas las alarmas irrelevantes, verificar el problema en forma de enlace y alarmar el lugar que eventualmente causó el problema, para que la operación y el desarrollo puedan responder y tratarlo de inmediato.
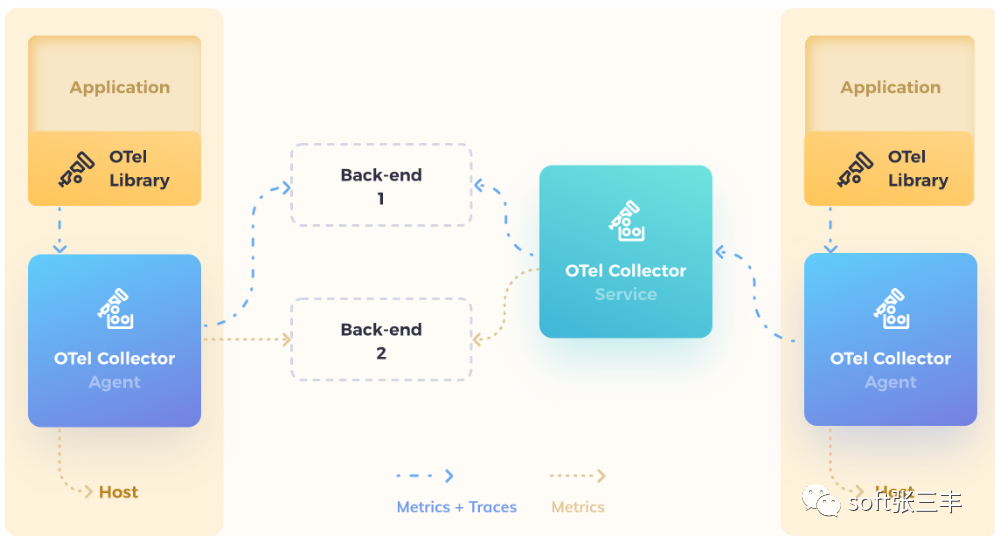
Sistema de vigilancia y alarma Prometheus
Sanfeng, cuenta pública: sistema de alarma y monitoreo suave Zhang Sanfeng Prometheus
Los datos de métricas finalmente obtenidos por Prometheus se muestran en forma de K / V. De acuerdo con el valor clave, podemos consultar el valor correspondiente, pero necesitamos obtener el elemento de monitoreo del rendimiento de un sistema (aplicación) que queremos calculando el datos, y luego configure los Umbrales correspondientes para las alarmas
Tome el uso de la CPU como ejemplo
node_cpu es una clave devuelta por node_exporter, que se puede usar para contar el uso de la CPU
Esta clave representa el valor acumulativo del intervalo de tiempo de CPU subyacente en Linux
Tiempo de CPU: comienza a funcionar desde el momento en que el sistema enciende la CPU. Registrará la cantidad acumulada de tiempo que usa en el trabajo y lo guardará en el sistema.
El tiempo de uso de la CPU acumulado también se divide en varios tipos de estado importantes
El tiempo de CPU se divide en tiempo de usuario (tiempo de uso en modo usuario)/tiempo de sistema (tiempo de uso en modo kernel)/tiempo agradable (tiempo de uso de asignación de valor agradable)/tiempo de inactividad (tiempo de inactividad)/irq (tiempo de interrupción), etc.
Uso de la CPU: la suma de todos los estados de la CPU excepto el estado inactivo (inactivo)/tiempo total de la CPU, es decir, uso de la CPU = 100%-inactivo/total
node_cpu representa el valor acumulado del tiempo de uso de cada núcleo de la CPU y cada estado
La línea de comando de consulta de números de Prometheus proporciona una función de cálculo muy rica
aumento (): para el valor del contador que aumenta continuamente, intercepte el incremento durante un período de tiempo, como aumentar (node_cpu [1m]) representa el incremento del tiempo total de la CPU dentro de un minuto
La CPU en el trabajo real es multinúcleo, y los datos recopilados también son el tiempo de CPU de cada núcleo
sum(): actúa como una adición
sum (aumento (node_cpu [1m])) significa el incremento del tiempo de CPU en todos los núcleos dentro de un minuto
El tiempo de uso de la CPU en estado inactivo se obtiene mediante el filtrado de etiquetas node_cpu{mode="idel"}
sum(increment(node_cpu{mode=“idel”}[1m]) ) significa el incremento del tiempo de CPU de todos los núcleos en estado inactivo en un minuto
Pero la consulta en el navegador de expresiones son los datos de todos los hosts de monitoreo.Usar la función sum() significa agregar la CPU de todos los clientes a la suma.
by(): el valor sumado por sum se divide en una capa de acuerdo con el método especificado
por (instancia) significa distinguir diferentes máquinas
sum(increment(node_cpu{mode=“idel”}[1m]) )by(instancia) representa el incremento del tiempo de CPU de todos los núcleos en un minuto en el estado inactivo de una sola máquina
sum(increment(node_cpu[1m]) )by(instance) representa el incremento del tiempo de CPU de todos los núcleos en un minuto en todos los estados de una sola máquina
1-sum( aumento(node_cpu{modo=“idel”}[1m]) )por(instancia)/sum(aumento(node_cpu[1m]) )por(instancia)*100 significa el uso de todos los núcleos de CPU de un solo tarifa de la máquina
Los datos de tipo contador, cuando se usan, deben combinarse con la función de aumento () o tasa () para que los datos sean significativos
Los datos de tipo Calibre son mucho más simples que los datos de tipo Contador. Los datos de monitoreo obtenidos se emiten directamente (no es necesario modificar funciones como aumentar () y tasa (), y se puede obtener la entrada incremental por unidad de tiempo para para obtener las expectativas del usuario (gráfico significativo)
1. Filtrado de datos
1. Filtrado de etiquetas
(nota de texto debajo del gráfico de Prometheus)
Los diferentes datos recopilados se pueden distinguir por color, y los datos que se mostrarán se pueden seleccionar haciendo clic en
El formato es key{label1="value1", label2="value2", … }. Cuando la etiqueta proviene de los datos recopilados, los exportadores la proporcionan de forma predeterminada o definida por el usuario (por ejemplo, al consultar node_cpu_seconds_total, node_cpu_seconds_total{cpu ="1",instancia= "localhost:9100",trabajo="agente",modo="usuario"})
Puede especificar una etiqueta al consultar:
coincidencia exacta = :node_cpu_seconds_total{modo="inactivo"}
Coincidencia aproximada ~=:node_cpu_seconds_total{mode=~".*"}
Falta de coincidencia aproximada !=: node_cpu_seconds_total{mode!="idle.*"}
2. Filtrado numérico
Ejemplo: node_cpu_seconds_total{modo=~".*"} > 6000
nodo_exportador
1 Supervisar el uso de la CPU
(1) La recopilación de CPU de Linux por parte de Prometheus no devuelve directamente un porcentaje de CPU listo para usar, sino que devuelve el valor acumulativo del intervalo de tiempo de CPU subyacente en el sistema Linux, en lugar de ver el uso de la CPU de forma sencilla a través del Tasa de comando superior o tiempo de actividad.
(2) Tiempo de la CPU: después de encender el sistema Linux, la CPU comienza a entrar en el estado de trabajo. La CPU registra la cantidad acumulada de "tiempo" utilizado en el trabajo y lo guarda en el sistema operativo. El tiempo de uso de la CPU en cada estado se acumula desde 0, y node_exporter captura los valores de tiempo acumulados de 8 estados de CPU de uso común:
tiempo de usuario de la cpu: tiempo de uso del modo de usuario de la cpu
sys time: tiempo de uso del estado del sistema/núcleo
buen tiempo: buen tiempo de uso de asignación de valor
tiempo de inactividad: tiempo de inactividad
irq: tiempo de interrupción
… y muchos más
(3) La tasa de uso de la CPU se refiere a los diversos estados de la CPU, la suma de todos los demás estados excepto inactivo dividido por el tiempo total de la CPU: node_cpu_seconds_total es el tiempo total de la CPU utilizada por la CPU desde el arranque hasta el actual ; Por lo tanto, el algoritmo de uso de la CPU: (1 - sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by(instance) / sum(increase(node_cpu_seconds_total{}[1m])) by(instance)) * 100
Explicación de la fórmula:
Supongamos que el sistema se inicia y se ejecuta durante 30 minutos (ignore la cantidad de núcleos temporalmente, suponiendo 1 núcleo). Durante este tiempo, el uso de la CPU es el siguiente: 8 minutos en modo usuario + 15 minutos en modo kernel + 0,5 minutos en IO estado de espera + 20 minutos en estado inactivo + 0 minutos en otros estados; luego uso de la CPU = (suma del tiempo de uso de la CPU en todos los estados no inactivos) / (suma del tiempo de CPU en todos los estados), es decir, (usuario(8m) + sys(1.5m) + iowa(0.5m) + 0)/(30m))= ((30m) - inactivo(20m) / (30m))=33.3%, el uso promedio de CPU en estos 30 minutos es 30%.
(4) La recopilación de datos en la parte inferior de Prometheus, el seguimiento formado por el algoritmo preciso, es más preciso y creíble.
(5) Dividir la fórmula de cálculo del uso de la CPU
En general, el uso de la CPU se obtiene mediante el método de (1-inactivo/total)*100 %:
(1 - sum(aumento(node_cpu_segundos_total{modo="inactivo"}[1m])) por(instancia) / sum(aumento(node_cpu_segundos_total{}[1m])) por(instancia)) * 100
1) Seleccione la clave a utilizar
node_cpu_seconds_total: En este momento, cuando se ingrese el resultado de la ejecución en la consola de Prometheus, habrá mucho tiempo de uso de la CPU en varios estados que seguirá aumentando.
2) Filtre el tiempo de CPU inactivo y el tiempo total de CPU
node_cpu_seconds_total{mode="idle"}: en este momento, ingrese el resultado de la ejecución en la consola de Prometheus y continúe aumentando el tiempo de uso inactivo de la CPU de cada núcleo de la CPU después del filtrado.
node_cpu_seconds_total{}: ingrese el resultado de la ejecución en la consola de Prometheus en este momento, y el tiempo total de uso de CPU de cada núcleo de CPU después del filtrado continúa creciendo
3) Obtenga el incremento del tiempo de CPU inactivo en un minuto y el incremento del tiempo total de CPU en un minuto
aumento (node_cpu_seconds_total{mode="idle"}[1m]), en este momento, ingrese el resultado de la ejecución en la Consola de Prometheus, el tiempo de uso inactivo incremental de cada núcleo de CPU después de filtrar dentro de un minuto
aumentar (node_cpu_seconds_total{}[1m]), en este momento, ingrese el resultado de la ejecución en la consola de Prometheus, y el tiempo total de uso de la CPU de cada núcleo de la CPU después del filtrado se incrementa en un minuto
4) Sume la suma incremental del tiempo de inactividad de la CPU de todos los núcleos de la CPU en un minuto y la suma incremental del tiempo total de todos los núcleos de la CPU en un minuto
sum(increase(node_cpu_seconds_total{mode="idle"}[1m])), en este momento, el resultado de ejecución ingresado en la consola de Prometheus es el tiempo de uso de CPU inactivo filtrado de cada núcleo de CPU de todos los servidores monitoreados dentro de un minuto sum de incrementos
sum(increase(node_cpu_seconds_total{}[1m])), en este momento, el resultado de ejecución ingresado en la consola de Prometheus es la suma de los incrementos del tiempo total de uso de la CPU dentro de un minuto de cada núcleo de CPU de todos los servidores monitoreados después filtración
5) Distinguir el tiempo de uso inactivo de la CPU resumido y el tiempo total de uso de la CPU por servidor
sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by(instancia), en este momento, el resultado de ejecución ingresado en la consola de Prometheus es que el tiempo de uso de CPU inactivo filtrado de cada núcleo de CPU de cada servidor es uno Suma de incrementos en minutos
sum(increase(node_cpu_seconds_total{}[1m])) por(instancia), en este momento, el resultado de ejecución ingresado en la consola de Prometheus es el incremento del tiempo total de uso de CPU de cada núcleo de CPU de cada servidor después de filtrar dentro de uno suma de minutos
6) Calcular según la fórmula (1-inactivo/total)*100%:
(1 - sum(aumento(node_cpu_segundos_total{modo="inactivo"}[1m])) por(instancia) / sum(aumento(node_cpu_segundos_total{}[1m])) por(instancia)) * 100
(6) De la misma manera, encuentre el uso de CPU en otros estados
nosotros: (sum(aumento(node_cpu_segundos_total{modo="usuario"}[1m])) por(instancia) / sum(aumento(node_cpu_segundos_total{}[1m])) por(instancia)) * 100
sy: (sum(aumento(node_cpu_segundos_total{modo="sistema"}[1m])) por(instancia) / sum(aumento(node_cpu_segundos_total{}[1m])) por(instancia)) * 100
ni: (sum(aumento(node_cpu_segundos_total{modo="agradable"}[1m])) por(instancia) / sum(aumento(node_cpu_segundos_total{}[1m])) por(instancia)) * 100
id: (sum(aumento(node_cpu_segundos_total{modo="inactivo"}[1m])) por(instancia) / sum(aumento(node_cpu_segundos_total{}[1m])) por(instancia)) * 100
wa: (sum(aumento(node_cpu_segundos_total{modo="iowait"}[1m])) por(instancia) / sum(aumento(node_cpu_segundos_total{}[1m])) por(instancia)) * 100
hola: (sum(aumento(node_cpu_segundos_total{modo="irq"}[1m])) por(instancia) / sum(aumento(node_cpu_segundos_total{}[1m])) por(instancia)) * 100
si: (sum(aumento(node_cpu_segundos_total{modo="softirq"}[1m])) por(instancia) / sum(aumento(node_cpu_segundos_total{}[1m])) por(instancia)) * 100
st: (sum(aumento(node_cpu_segundos_total{modo="robar"}[1m])) por(instancia) / sum(aumento(node_cpu_segundos_total{}[1m])) por(instancia)) * 100
Es decir, el uso de la CPU consultado por el comando superior:
(7) En el entorno de producción, la alta tasa de uso de la CPU de más del 70-80% generalmente se debe a la gran cantidad de CPU del usuario en el modo de usuario. El uso de la CPU en modo usuario está estrechamente relacionado con la ejecución de la aplicación. Cuando se ejecuta una gran cantidad de procesos en el servidor para procesar tareas en paralelo, y los procesos se cambian con frecuencia entre páginas, el consumo de CPU en modo usuario es el más grande
Al monitorear, la tasa de uso del % de usuario generalmente no se enumera por separado, porque a excepción del alto uso de la CPU causado por iowait y la alta tasa de uso de algunos estados del kernel del sistema, la mayoría de los casos son causados por el % de usuario.
En muchos casos, cuando el uso de E/S del disco duro del servidor es demasiado grande, la CPU esperará el retorno de E/S para entrar en el tiempo de espera de la CPU del tipo interrumpible, por lo que también es necesaria la supervisión de ioespera de la CPU.
usuario: (sum(aumento(node_cpu_segundos_total{modo="usuario"}[1m])) por(instancia) / sum(aumento(node_cpu_segundos_total{}[1m])) por(instancia)) * 100
iowait: (sum(aumento(node_cpu_segundos_total{modo="iowait"}[1m])) por(instancia) / sum(aumento(node_cpu_segundos_total{}[1m])) por(instancia)) * 100
El umbral para el monitoreo de la CPU, establecido en 99 % o 100 %: en general, un servidor con un uso de la CPU del 80 % al 90 % aún puede procesar solicitudes, pero la velocidad será más lenta; una vez que el uso de la CPU esté entre el 98 % y el 100 % %, entonces todo el servidor casi pierde disponibilidad. (La optimización para el sistema Linux es muy importante, controle el servidor a través de varios parámetros del kernel y parámetros del software, trate de no dejar que la CPU se acumule al 99% -100%)
Vigilancia de Prometeo (1)
Sanfeng, cuenta pública: seguimiento suave de Zhang Sanfeng Prometheus (1)
Vigilancia de Prometeo (2)
Sanfeng, cuenta pública: seguimiento suave de Zhang Sanfeng Prometheus (2)
Vigilancia de Prometeo (3)
Sanfeng, cuenta pública: seguimiento suave de Zhang Sanfeng Prometheus (3)
Vigilancia de Prometeo (4)
Sanfeng, cuenta pública: seguimiento suave de Zhang Sanfeng Prometheus (4)
teoría distribuida
Sanfeng, cuenta pública: teoría distribuida suave de Zhang Sanfeng
Agregue WeChat al grupo de comunicación WeChat del microservicio y tenga en cuenta que el microservicio ingresa a la comunicación del grupo

Preste atención a la cuenta pública suave Zhang Sanfeng 