La octava "Sesión de intercambio de observabilidad nativa de Force Unleashing Cloud" El vicepresidente de I + D de Spruce Network, Xiang Yang, compartió "DeepFlow - Abriendo una nueva era de observabilidad altamente automatizada" , se lanzó oficialmente la primera versión de código abierto de DeepFlow , es una plataforma de observabilidad altamente automatizada puede reducir significativamente la carga de enterrar, codificar y mantener para los desarrolladores.
Haga clic en la tarjeta a continuación para ver la reproducción del video.
 Bilibili , Transaction Guarantee , Buy with Confidence , DeepFlow
Bilibili , Transaction Guarantee , Buy with Confidence , DeepFlow  - Mini programas queabren una nueva era de observabilidad altamente automatizada
- Mini programas queabren una nueva era de observabilidad altamente automatizada
Hola amigos de la sala de transmisión en vivo, estoy muy feliz de compartir con ustedes el lanzamiento oficial de la primera versión de código abierto de DeepFlow. Creo que a través de mi presentación de hoy , todos pueden sentir una nueva era de observabilidad altamente automatizada, seamos testigos y abrámosla juntos.
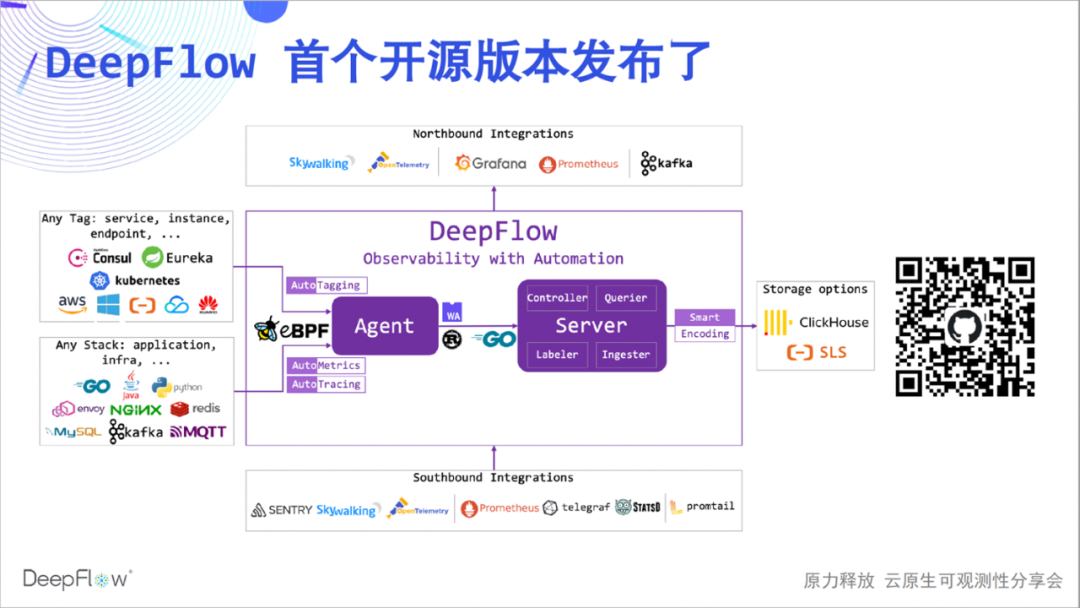
El siguiente es el diagrama de arquitectura de la versión comunitaria de DeepFlow. Algunos amigos no saben mucho sobre DeepFlow, así que lo presentaré brevemente. DeepFlow es una plataforma de observabilidad de desarrollo propio de Yunshan Network. Basada en una serie de innovaciones en eBPF y otras tecnologías, está altamente automatizada, lo que reduce significativamente la carga de trabajo para que los desarrolladores construyan la observabilidad.
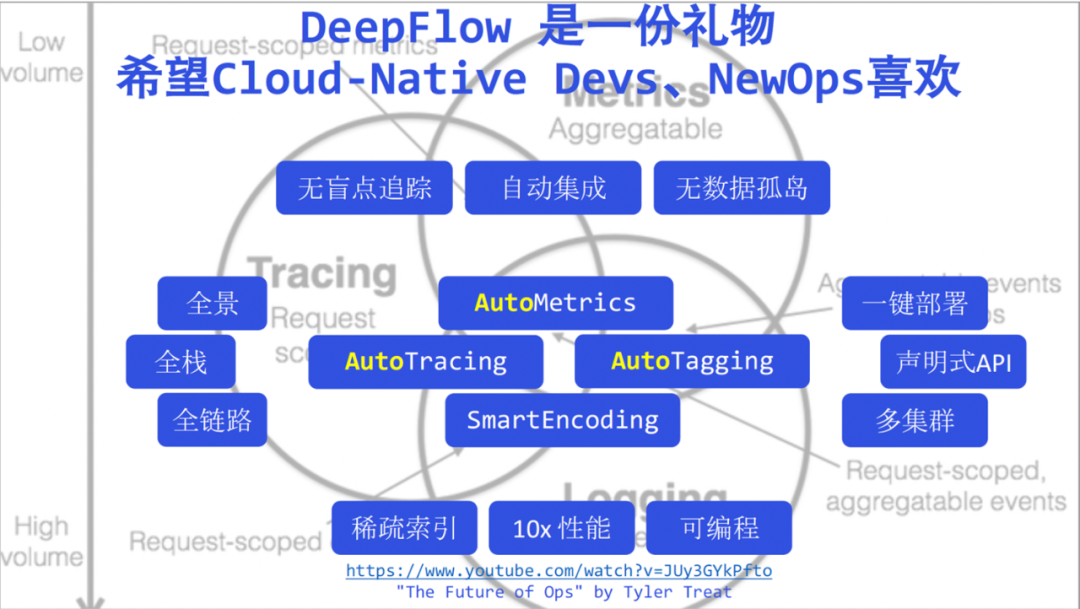
Podemos ver que puede sincronizar automáticamente los recursos, los servicios, la etiqueta personalizada de K8 e inyectarla en los datos de observación como una etiqueta (Etiquetado automático), puede recopilar automáticamente las métricas de rendimiento de la aplicación y los datos de seguimiento sin codificación (AutoMetrics, AutoTagging), el innovador SmartEncoding El mecanismo reduce el consumo de recursos de almacenamiento de etiquetas en un factor de 10. Además, tiene buenas capacidades de integración, puede integrar una amplia gama de fuentes de datos y proporciona una buena interfaz orientada al norte basada en SQL. El núcleo de DeepFlow es de código abierto basado en la licencia Apache 2.0, ¡bienvenido a darnos 🌟 Estrella ( escanee el código QR a continuación )!
Cuando hablamos de altos niveles de automatización, ¿qué mensaje estamos tratando de transmitir? El compartir de hoy partirá de cuatro aspectos:
-
En primer lugar, presenta AutoMetrics, la capacidad de recopilación automática de datos de indicadores de DeepFlow, que muestra automáticamente la relación entre los indicadores de rendimiento completos y los servicios panorámicos;
-
Lo siguiente son las capacidades de integración automatizadas de Prometheus y Telegraf, que recopilan los datos de indicadores más completos y resuelven el problema de los silos de datos y la alta cardinalidad;
-
Después de eso, lo llevaré a experimentar AutoTracing, la innovadora capacidad de rastreo distribuido automatizado de DeepFlow basada en eBPF Creo que esta es definitivamente una innovación de clase mundial;
-
Finalmente, las capacidades de integración automatizadas de OpenTelemetry y SkyWalking demuestran increíbles capacidades de seguimiento distribuido sin puntos ciegos y resuelven el problema del seguimiento incompleto.
Un alto grado de automatización puede permitir a los desarrolladores dedicar más tiempo al desarrollo comercial y los equipos pueden trabajar juntos para resolver problemas de manera más fluida.
Así que echemos un vistazo a la primera viñeta de hoy, AutoMetrics.
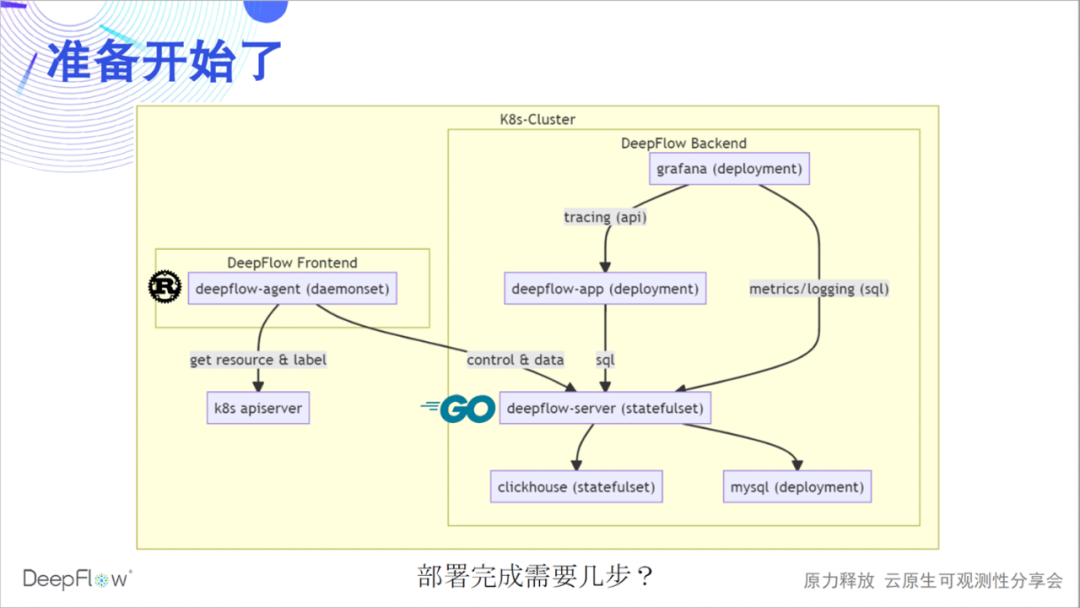
Precalientemos e implementemos un conjunto completo de DeepFlow. La siguiente figura muestra la arquitectura de software de DeepFlow más claramente: el agente de flujo profundo implementado por Rust recopila datos como interfaz y sincroniza los recursos y la información de etiquetas con el servidor ap de K8s; el servidor de flujo profundo implementado por Golang es responsable del control de gestión, la carga uso compartido y consulta de almacenamiento como backend. Usamos MySQL para almacenar metadatos, ClickHouse para almacenar observaciones y admitir el reemplazo de extensiones, y Grafana para mostrar las observaciones.
En la actualidad, también tenemos un proceso de aplicación de flujo profundo implementado en Python para proporcionar una API de seguimiento distribuida, que se reescribirá en Golang y se fusionará gradualmente en el servidor de flujo profundo. deepflow-server proporciona SQL API hacia arriba, en base a lo cual desarrollamos DeepFlow DataSource y Panels de Grafana, como la topología y el seguimiento distribuido. deepflow-agent puede ejecutarse en el host o en el entorno K8s, pero deepflow-server debe ejecutarse en K8s. Adivinemos cuántos pasos se necesitan para implementar DeepFlow en un clúster K8s.
Sí, solo se necesita un paso, copiar y pegar estos pocos nombres de timón para completar la implementación. Si tiene una computadora a su lado, puede consultar la documentación de implementación para implementar ahora, y esperar proporcionar comentarios sobre la experiencia de implementación en la sala de transmisión en vivo o en nuestro grupo de WeChat.
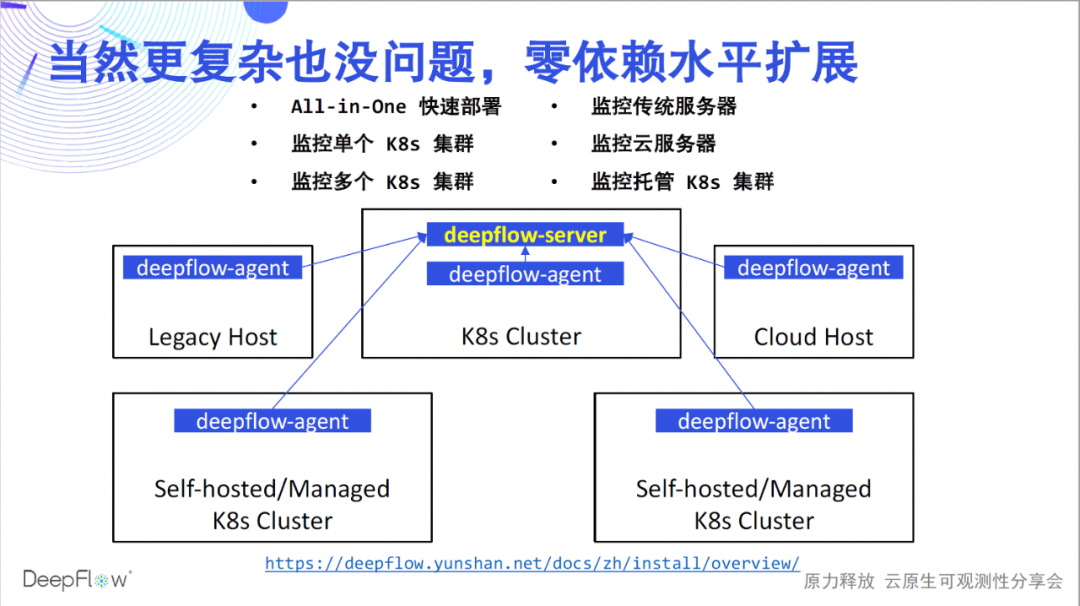
helm repo add deepflow https:helm repo update deepflowhelm install deepflow -n deepflow deepflow/deepflow --create-namespace
La implementación en este momento solo resuelve el problema de monitoreo de un clúster K8s y, por supuesto, las capacidades de DeepFlow no se limitan a esto. En referencia a la documentación de implementación , DeepFlow se puede implementar sin problemas en varios escenarios. Admitimos una experiencia rápida todo en uno de un solo nodo; admitimos el monitoreo de múltiples clústeres de K8 e inyectamos automáticamente recursos de K8 y etiquetas de etiquetas personalizadas para todos los datos; admitimos el monitoreo de servidores tradicionales y servidores en la nube e inyectamos automáticamente etiquetas de recursos de la nube para todos los datos; Finalmente, también admitimos el monitoreo de clústeres K8 administrados e inyectamos automáticamente K8 y etiquetas de recursos en la nube. En todos estos escenarios, DeepFlow puede escalar horizontalmente sin depender de ningún componente externo. Ahora que la implementación está completa, comencemos nuestro viaje de observabilidad altamente automatizado.
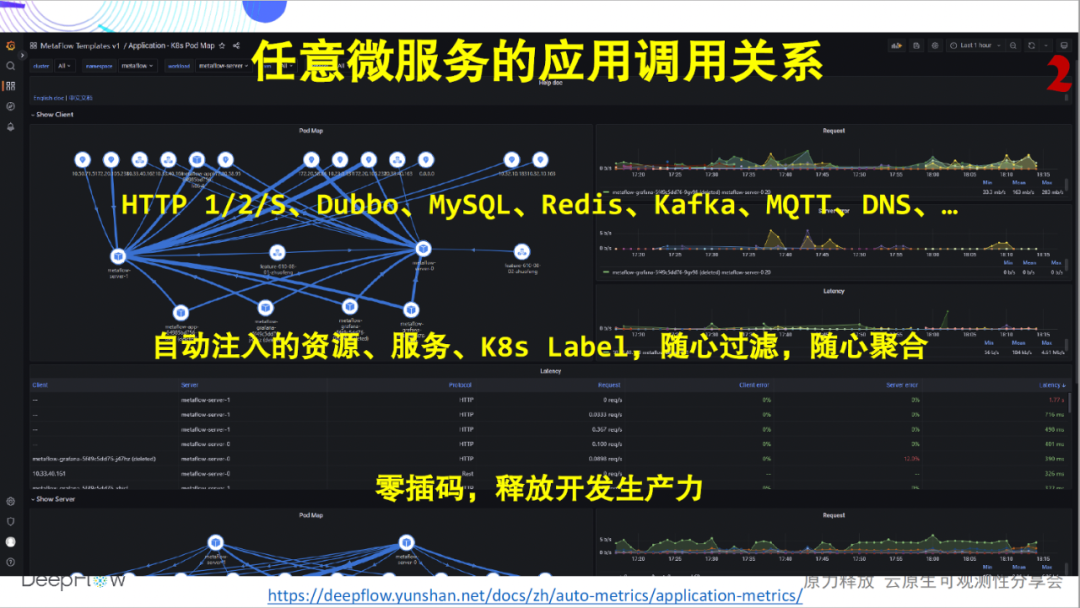
 Los indicadores dorados de los que hablamos con más frecuencia son generalmente la Solicitud, el Error y el Retraso del servicio. La siguiente figura muestra los indicadores ROJOS de rendimiento de la aplicación de cualquier microservicio que se puede mostrar después de implementar DeepFlow, sin importar en qué idioma se implemente. Actualmente admitimos la recopilación de datos de métricas para aplicaciones HTTP 1/2/S, Dubbo, MySQL, Redis, Kafka, MQTT y DNS, y la lista de soporte sigue creciendo. Inyectaremos automáticamente docenas o incluso cientos de campos de etiquetas de dimensión para todos los datos de indicadores, incluidos recursos, servicios y etiquetas personalizadas de K8, lo que permite a los usuarios agregar y profundizar de manera flexible. Pero aquí queremos enfatizar la capacidad de automatización, el equipo de desarrollo de estos indicadores ya no tendrá que preocuparse por conectar el código, y el equipo de operación y mantenimiento ya no tendrá que preocuparse por empujar siempre el desarrollo para conectar el código. La automatización de DeepFlow hace que cada equipo sea más productivo y que el trabajo en equipo sea más armonioso.
Los indicadores dorados de los que hablamos con más frecuencia son generalmente la Solicitud, el Error y el Retraso del servicio. La siguiente figura muestra los indicadores ROJOS de rendimiento de la aplicación de cualquier microservicio que se puede mostrar después de implementar DeepFlow, sin importar en qué idioma se implemente. Actualmente admitimos la recopilación de datos de métricas para aplicaciones HTTP 1/2/S, Dubbo, MySQL, Redis, Kafka, MQTT y DNS, y la lista de soporte sigue creciendo. Inyectaremos automáticamente docenas o incluso cientos de campos de etiquetas de dimensión para todos los datos de indicadores, incluidos recursos, servicios y etiquetas personalizadas de K8, lo que permite a los usuarios agregar y profundizar de manera flexible. Pero aquí queremos enfatizar la capacidad de automatización, el equipo de desarrollo de estos indicadores ya no tendrá que preocuparse por conectar el código, y el equipo de operación y mantenimiento ya no tendrá que preocuparse por empujar siempre el desarrollo para conectar el código. La automatización de DeepFlow hace que cada equipo sea más productivo y que el trabajo en equipo sea más armonioso.
 Mirando otra imagen, además de un solo servicio, DeepFlow también puede presentar la relación de llamada de aplicación entre cualquier microservicio. Nuevamente, interpolación completamente cero. A través del documento , puede iniciar sesión en nuestro entorno de demostración en línea para una experiencia de la vida real.
Mirando otra imagen, además de un solo servicio, DeepFlow también puede presentar la relación de llamada de aplicación entre cualquier microservicio. Nuevamente, interpolación completamente cero. A través del documento , puede iniciar sesión en nuestro entorno de demostración en línea para una experiencia de la vida real.
Eso es todo? ¡Mucho más que eso! En un entorno nativo de la nube, la complejidad de la red aumenta significativamente, convirtiéndose en una caja negra para la resolución de problemas, y la localización de problemas suele ser una conjetura. DeepFlow tiene capacidades de monitoreo de pila completa del rendimiento de la aplicación y puede recopilar automáticamente cientos de indicadores como el rendimiento, la excepción de establecimiento de conexión, el retraso en el establecimiento de conexión, el retraso en la transmisión, la ventana cero, la retransmisión, la concurrencia, etc. de cualquier microservicio .
De manera similar, DeepFlow también puede presentar la relación de llamadas de red entre cualquier microservicio. Todavía completamente cero-interpolación.
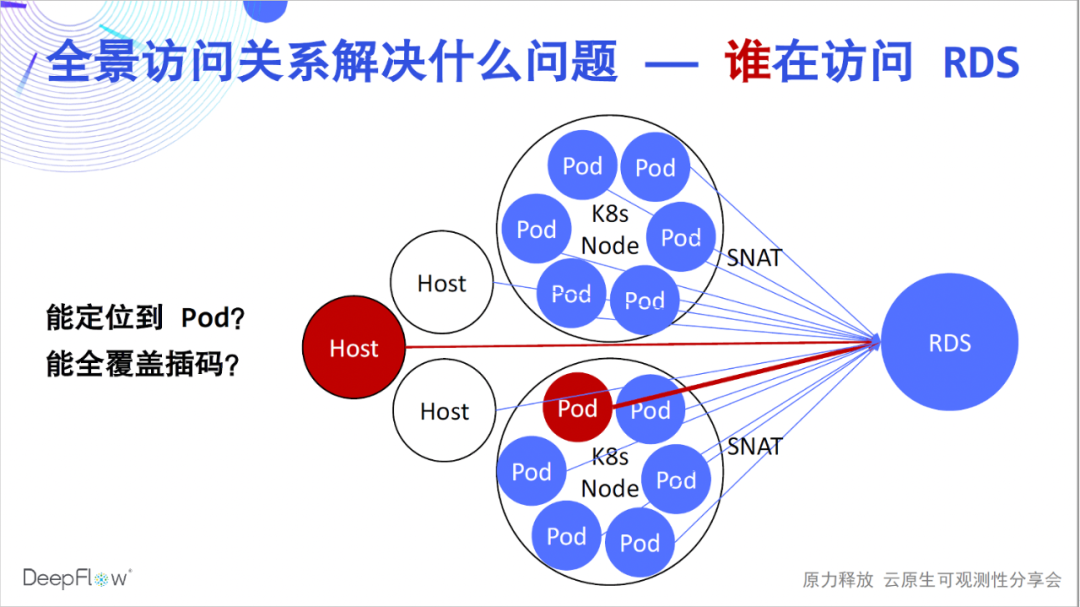
Bueno, creo que todos han comenzado a sentir más verdaderamente el aliento de la alta automatización. Pero, ¿qué problemas resuelven? Confiando en la relación de acceso panorámico automático, los clientes de DeepFlow Enterprise Edition pueden resolver rápidamente una gran cantidad de problemas de ubicación de fallas, como la operación y el mantenimiento de RDS utilizados para ubicar qué cliente causó la mayor carga de acceso. Debido a la existencia de SNAT en el entorno K8s, no hay forma de saber a qué Pods se está accediendo. En el método tradicional, solo podemos insertar códigos en el lado del cliente, pero es difícil lograr una cobertura completa. Resolver tales problemas con DeepFlow es muy fácil, simplemente busque en el RDS para obtener métricas de rendimiento para todos los clientes que acceden a él.
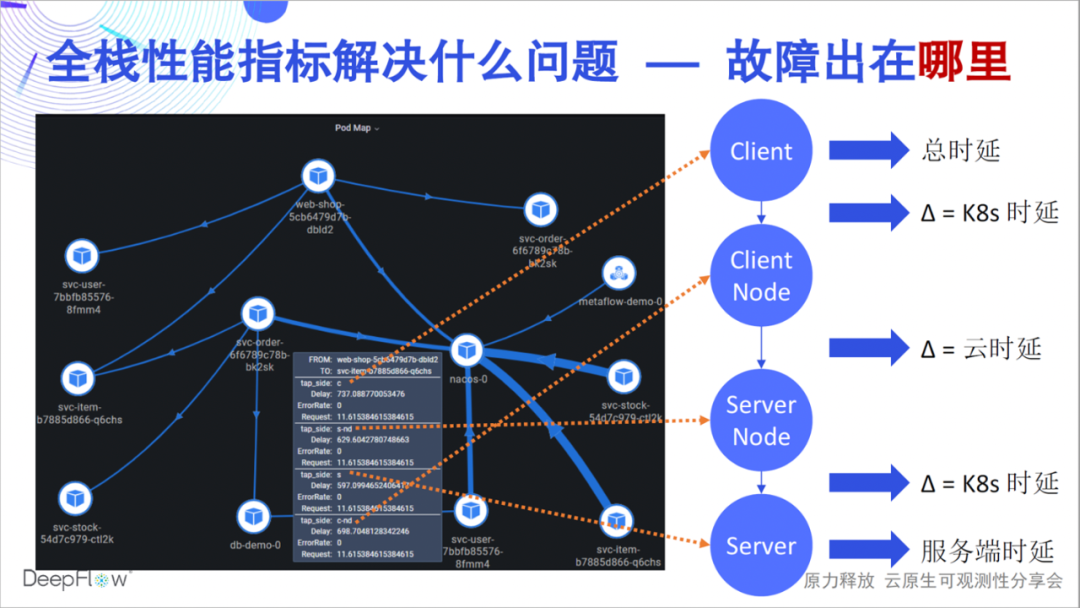
 Entonces, ¿qué problemas pueden resolver las métricas de rendimiento de pila completa? Una falla puede ser que la latencia de una API sea demasiado alta, pero ¿qué enlace es la causa de la latencia, de qué equipo debe ser responsable y qué tan rápido puede su equipo resolver ese problema? La capacidad de pila completa de DeepFlow puede responder rápidamente al estado de rendimiento de una relación de acceso en cada nodo clave. Por ejemplo, como se muestra en esta figura, podemos distinguir con precisión si el cuello de botella está en el pod del servidor, la red K8 del servicio o la red en la nube. y cliente K8s La red, o el propio cliente. DeepFlow hace que la resolución de problemas en un entorno distribuido sea tan fácil como una sola máquina, sin dejar de estar completamente automatizado.
Entonces, ¿qué problemas pueden resolver las métricas de rendimiento de pila completa? Una falla puede ser que la latencia de una API sea demasiado alta, pero ¿qué enlace es la causa de la latencia, de qué equipo debe ser responsable y qué tan rápido puede su equipo resolver ese problema? La capacidad de pila completa de DeepFlow puede responder rápidamente al estado de rendimiento de una relación de acceso en cada nodo clave. Por ejemplo, como se muestra en esta figura, podemos distinguir con precisión si el cuello de botella está en el pod del servidor, la red K8 del servicio o la red en la nube. y cliente K8s La red, o el propio cliente. DeepFlow hace que la resolución de problemas en un entorno distribuido sea tan fácil como una sola máquina, sin dejar de estar completamente automatizado.
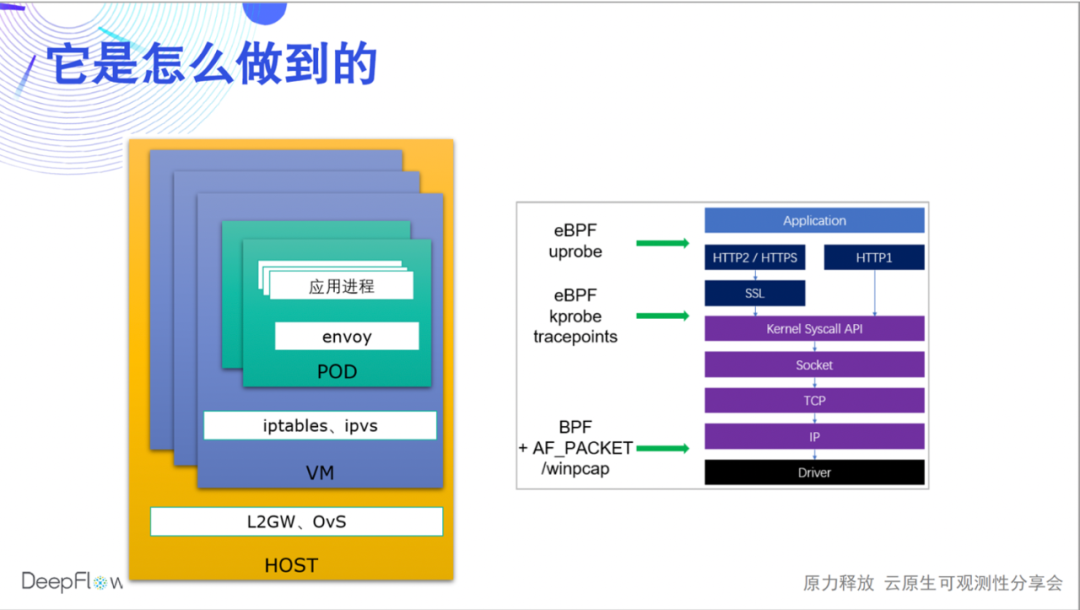
 ¿Cómo lo hace DeepFlow? Hoy solo podemos tocar el agua, y habrá más transmisiones en vivo y artículos para compartir el mecanismo subyacente. Usamos eBPF y BPF para recopilar los datos de rendimiento de cada solicitud (Flow en nombre de DeepFlow) durante la aplicación, las llamadas al sistema y la transmisión de red, y los asociamos automáticamente. De esta forma, por un lado, podemos cubrir todos los puntos finales de comunicación (microservicios), y por otro lado, también podemos correlacionar los datos de rendimiento de cada salto y localizar rápidamente el problema en el proceso de aplicación, Sidecar, Pod virtual. tarjeta de red y tarjeta de red de nodo. , DeepFlow Enterprise Edition puede seguir localizando tarjetas de red host, tarjetas de red de puerta de enlace NFV, puertos de elementos de red física, etc.
¿Cómo lo hace DeepFlow? Hoy solo podemos tocar el agua, y habrá más transmisiones en vivo y artículos para compartir el mecanismo subyacente. Usamos eBPF y BPF para recopilar los datos de rendimiento de cada solicitud (Flow en nombre de DeepFlow) durante la aplicación, las llamadas al sistema y la transmisión de red, y los asociamos automáticamente. De esta forma, por un lado, podemos cubrir todos los puntos finales de comunicación (microservicios), y por otro lado, también podemos correlacionar los datos de rendimiento de cada salto y localizar rápidamente el problema en el proceso de aplicación, Sidecar, Pod virtual. tarjeta de red y tarjeta de red de nodo. , DeepFlow Enterprise Edition puede seguir localizando tarjetas de red host, tarjetas de red de puerta de enlace NFV, puertos de elementos de red física, etc.
 Todavía hay mucho trabajo para continuar iterando. Sabemos que los campos de encabezado de HTTP2/gRPC están comprimidos. Actualmente, admitimos el análisis de encabezado de protocolo basado en tablas de compresión estáticas. En el futuro, usaremos eBPF uprobe para obtener tablas de compresión dinámicas para el análisis de encabezado completo. Para HTTPS, actualmente admitimos la capacidad de uprobe de eBPF para recopilar aplicaciones de Golang, y gradualmente admitiremos C/C++/Java/Python y otros lenguajes en el futuro. Al mismo tiempo, también entendemos que habrá una gran cantidad de protocolos de aplicaciones privadas en el entorno comercial real, y esperamos brindarles a los desarrolladores una capacidad de programación flexible a través de la tecnología WebAssembly.
Todavía hay mucho trabajo para continuar iterando. Sabemos que los campos de encabezado de HTTP2/gRPC están comprimidos. Actualmente, admitimos el análisis de encabezado de protocolo basado en tablas de compresión estáticas. En el futuro, usaremos eBPF uprobe para obtener tablas de compresión dinámicas para el análisis de encabezado completo. Para HTTPS, actualmente admitimos la capacidad de uprobe de eBPF para recopilar aplicaciones de Golang, y gradualmente admitiremos C/C++/Java/Python y otros lenguajes en el futuro. Al mismo tiempo, también entendemos que habrá una gran cantidad de protocolos de aplicaciones privadas en el entorno comercial real, y esperamos brindarles a los desarrolladores una capacidad de programación flexible a través de la tecnología WebAssembly.
Pero estos indicadores por sí solos no son perfectos, y la observabilidad requiere la mayor cantidad de datos posible. A continuación, presentamos las capacidades de integración de datos de indicadores automatizados de DeepFlow.
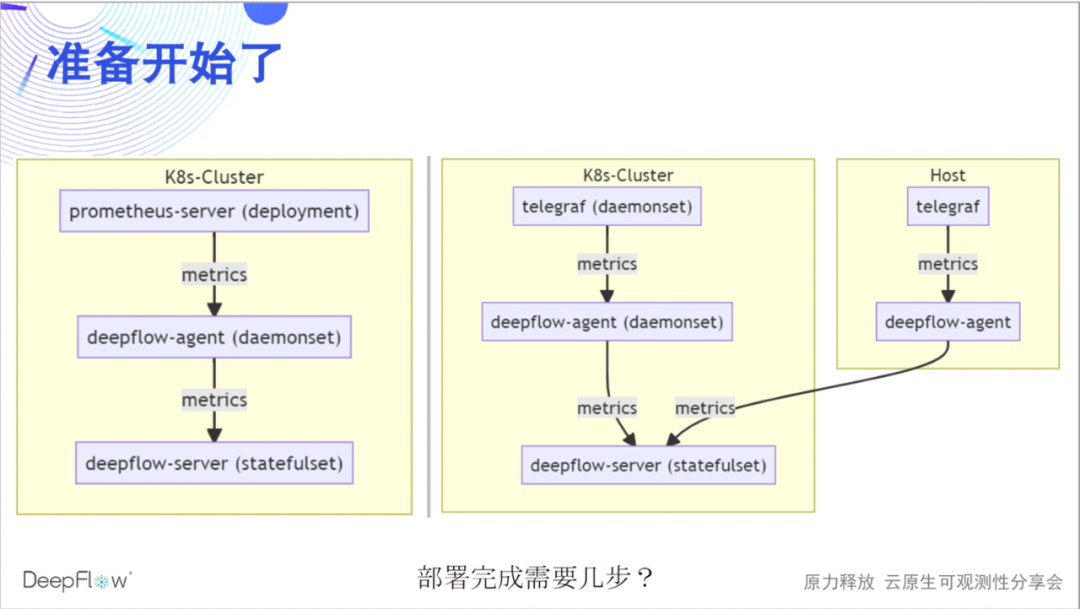
La siguiente figura muestra el método de integración de DeepFlow, Prometheus y Telegraf. Integramos datos a través de deepflow-agent como punto final de almacenamiento remoto de prometheus-server, o como punto final de salida de telegraf. Todo el proceso es relativamente simple. ¿Crees que se necesitan algunos pasos para completar una implementación de este tipo?
Solo se necesitan dos pasos para modificar una configuración en los lados de prometheus/telegraf y deepflow-agent respectivamente. La configuración en este lado de DeepFlow es en realidad solo un interruptor. No lo activamos de forma predeterminada. Esperamos que deepflow-agent no escuche ningún puerto de forma predeterminada y no tenga intrusiones en el entorno en ejecución.
# prometheus-server config remote_write: - url: http: # telegraf config [[outputs.http]] url = "http://${DEEPFLOW_AGENT_SVC}/api/v1/telegraf" data_format = "influx" # deepflow config vtap_group_id: <your-agent-group-id> external_agent_http_proxy_enabled: 1
Una configuración tan simple también se puede probar en varios escenarios complejos, cubriendo múltiples clústeres K8 y servidores en la nube, y se puede escalar horizontalmente sin la ayuda de ningún componente externo.
¿Por qué recopilar datos en DeepFlow? Primero experimentemos las poderosas capacidades de etiquetado automático. Inyectamos automáticamente una gran cantidad de etiquetas en todos los datos nativos e integrados de DeepFlow, de modo que no haya barreras para la asociación de datos ni fallas en el desglose de datos. Estas etiquetas provienen de recursos en la nube, recursos de K8 y etiquetas personalizadas de K8. Creo que a los desarrolladores les debe gustar mucho esta capacidad y ya no necesitan insertar muchas etiquetas dispersas en el código comercial. Recomendamos que inyecte todas las etiquetas que deben personalizarse a través de K8s Label cuando el servicio esté en línea, completamente desvinculado del código comercial. En cuanto a las etiquetas dinámicas relacionadas con el negocio, DeepFlow también se almacenará por completo de una manera muy eficiente para admitir la recuperación y la agregación.
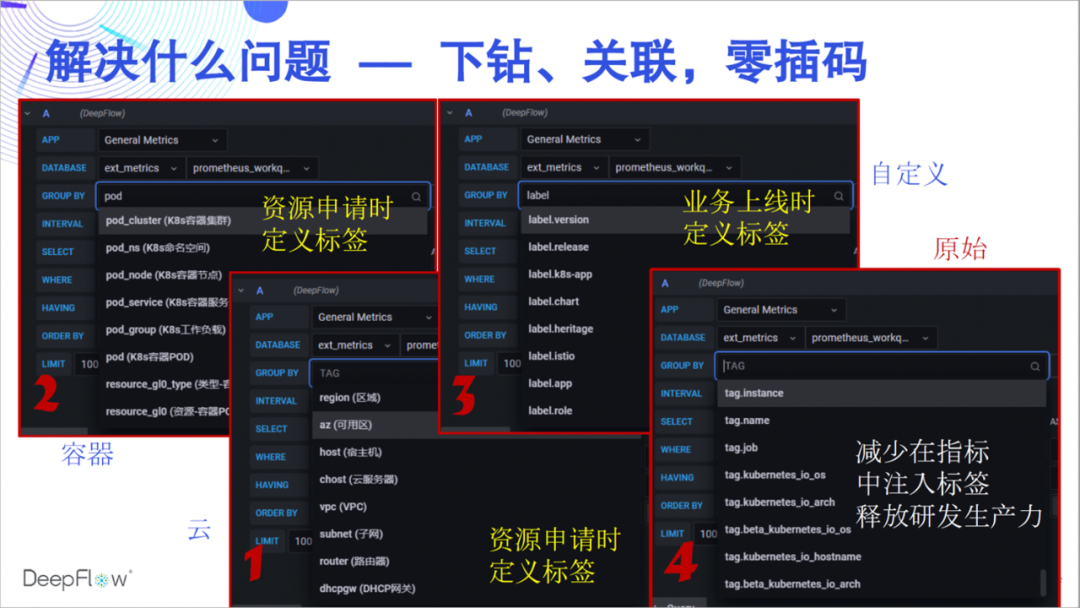 Inserte automáticamente tantas etiquetas, ¿qué pasa con el consumo de recursos? El mecanismo SmartEncoding de DeepFlow resuelve muy bien este problema. Codificamos las etiquetas numéricamente por adelantado. Los datos del indicador no llevarán estas etiquetas durante la generación y transmisión, y solo los campos de etiquetas numéricas codificados se insertan uniformemente antes del almacenamiento. Para la etiqueta personalizada de K8, ni siquiera la almacenamos con los datos del indicador, solo la asociamos en el momento de la consulta. En comparación con LowCard de ClickHouse o con el almacenamiento directo de campos de etiquetas, el mecanismo de codificación inteligente nos permite reducir la potencia informática y el consumo de almacenamiento hasta en un orden de magnitud.
Inserte automáticamente tantas etiquetas, ¿qué pasa con el consumo de recursos? El mecanismo SmartEncoding de DeepFlow resuelve muy bien este problema. Codificamos las etiquetas numéricamente por adelantado. Los datos del indicador no llevarán estas etiquetas durante la generación y transmisión, y solo los campos de etiquetas numéricas codificados se insertan uniformemente antes del almacenamiento. Para la etiqueta personalizada de K8, ni siquiera la almacenamos con los datos del indicador, solo la asociamos en el momento de la consulta. En comparación con LowCard de ClickHouse o con el almacenamiento directo de campos de etiquetas, el mecanismo de codificación inteligente nos permite reducir la potencia informática y el consumo de almacenamiento hasta en un orden de magnitud.
Por lo tanto, negarse a insertar etiquetas en el código comercial no solo es perezoso, sino también respetuoso con el medio ambiente.
Lo que más queremos es activar la colaboración en equipo a través de una amplia integración y correlación de datos. DeepFlow tiene indicadores de aplicaciones y redes automatizados, Prometheus/Telegraf tiene indicadores de rendimiento del sistema automatizados, además de indicadores comerciales expuestos por los desarrolladores a través de Exporter/StatsD. Depositamos estos ricos indicadores en una plataforma de datos y realizamos una correlación automática eficiente, con la esperanza de promover la colaboración mutua de los equipos de operación y mantenimiento, desarrollo y operación, y proporcionar la eficiencia de trabajo de todos los equipos.
También tenemos algún trabajo planificado sobre la integración de métricas. Continuaremos admitiendo la interfaz de lectura_remota de Prometheus, para que DeepFlow se pueda usar como un almacenamiento remoto completo de Prometheus, lo que no cambiará los hábitos de uso de los usuarios de Prometheus. Planeamos exportar los indicadores automatizados de DeepFlow al servidor Prometheus, para que los equipos de desarrollo familiarizados con Prometheus puedan obtener fácilmente capacidades de alerta de indicadores panorámicos y de pila completa más potentes. También seguimos apoyando la integración de otros agentes, y creemos firmemente que la observabilidad debe ser capaz de recopilar datos ampliamente. Además, DeepFlow también admite la sincronización de información en el registro de servicios, de modo que la rica información del tiempo de ejecución de la aplicación se pueda inyectar automáticamente en los datos de observación como etiquetas.
Ahora ingresamos a un nuevo tema: el seguimiento. Primero, experimentemos las capacidades de AutoTracing de la automatización de DeepFlow.
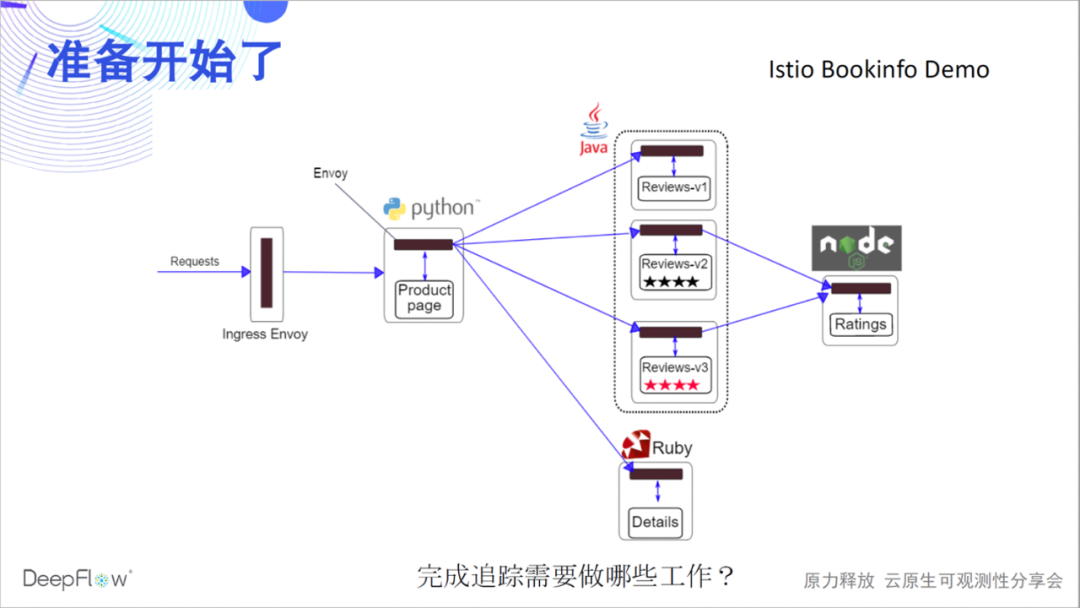
Tomemos como ejemplo una demostración oficial de Bookinfo de Istio para presenciar el milagro con usted. Se cree que esta demostración es familiar para muchos amigos. Hay 4 microservicios en varios idiomas, y hay Envoy Sidecar. Primero adivinemos, ¿qué debemos hacer para completar el rastreo distribuido?
Echemos un vistazo a cómo OpenTelemetry +
Jaeger realiza un seguimiento de la demostración. Leíste bien, porque no hay instrumentación en esta demostración, Jaeger no puede ver nada, está vacío.
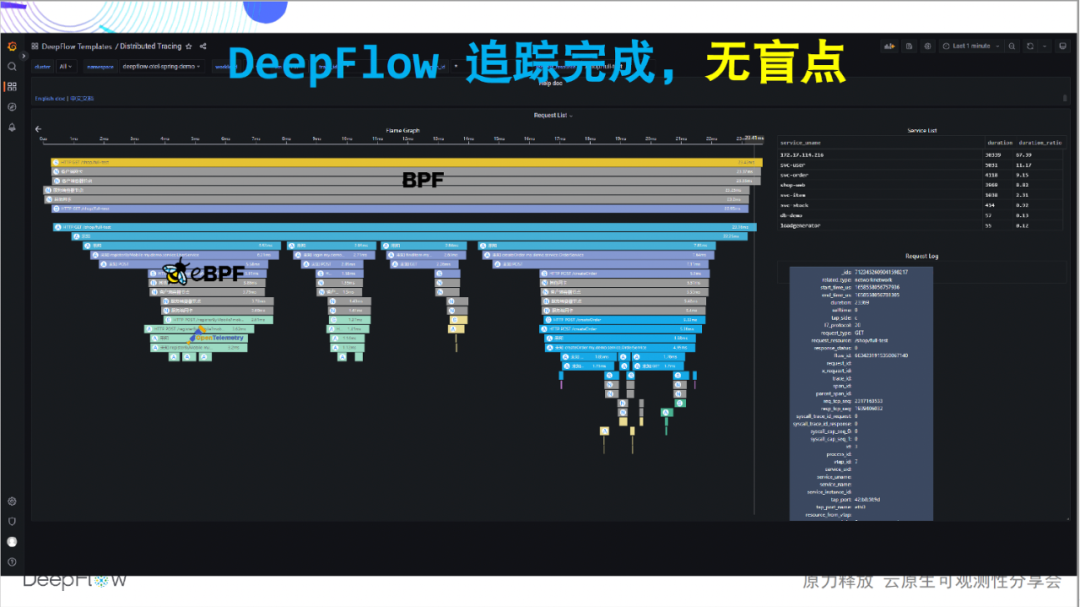
Entonces, ¿qué debe hacer DeepFlow? De hecho, no es necesario hacer nada, porque ya implementamos DeepFlow a través de un comando de timón temprano y no se requieren más operaciones. Es hora de presenciar el milagro. Sin ningún código insertado, rastreamos completamente las llamadas entre estos cuatro microservicios. ¡Confíe en las capacidades de eBPF y BPF, totalmente automatizadas!
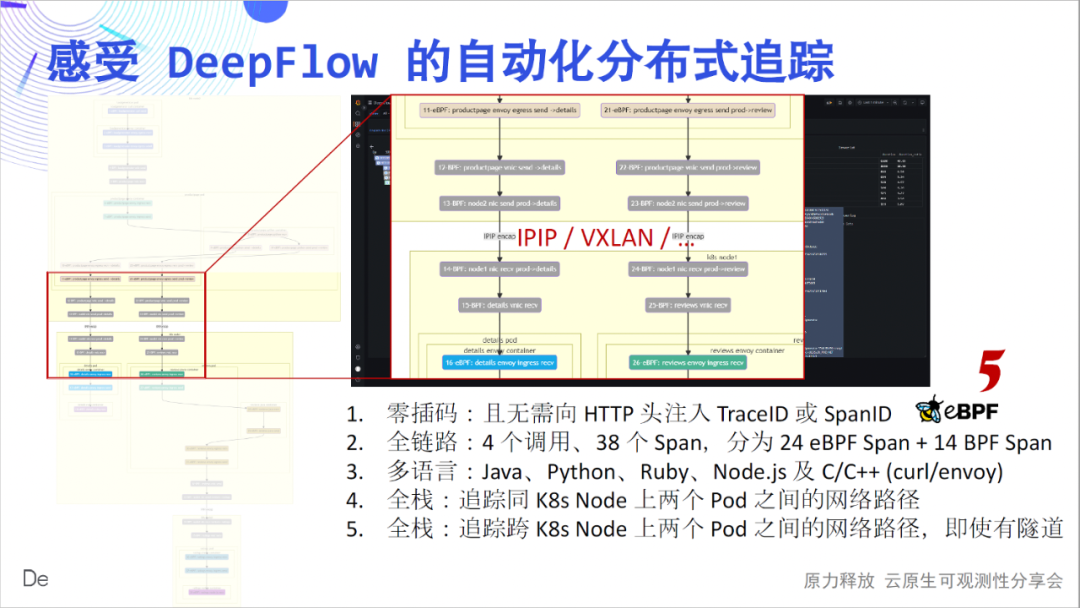
A continuación, lo llevaremos a experimentar en detalle el profundo encanto de este sencillo mapa de llamas: la inserción cero es el primer sentimiento que queremos transmitir. Dibujando cada tramo del gráfico de llama como un nodo, obtenemos un diagrama de flujo de llamadas, desde el cual podemos ver claramente el complejo proceso de llamada de esta sencilla aplicación. El enlace completo es el segundo sentimiento que queremos transmitir. En 4 llamadas, rastreamos 24 tramos de eBPF, 14 tramos de BPF y construimos sus relaciones.
El multilingüismo es el tercer sentimiento que queremos transmitir. Aquí se tratan los servicios implementados por Java, Python, Ruby, Node.js, C y C++, y se realiza un seguimiento discreto de DeepFlow. Full stack es la cuarta sensación que queremos transmitir. Podemos ver que la ruta de acceso a la red salto por salto entre Pods está clara y dónde está el cuello de botella.
La pila completa también se refleja en los nodos de contenedores cruzados.Ya sea que la ruta de red intermedia sea IPIP o encapsulación de túnel VXLAN, se puede rastrear de manera estable.
La pila completa también se refleja en la ruta de tráfico dentro del Pod. ¿Está atrapado en un laberinto de rutas de tráfico cuando usa Envoy? DeepFlow puede abrir fácilmente el cuadro negro de la ruta de flujo dentro del Pod y verlo con claridad.
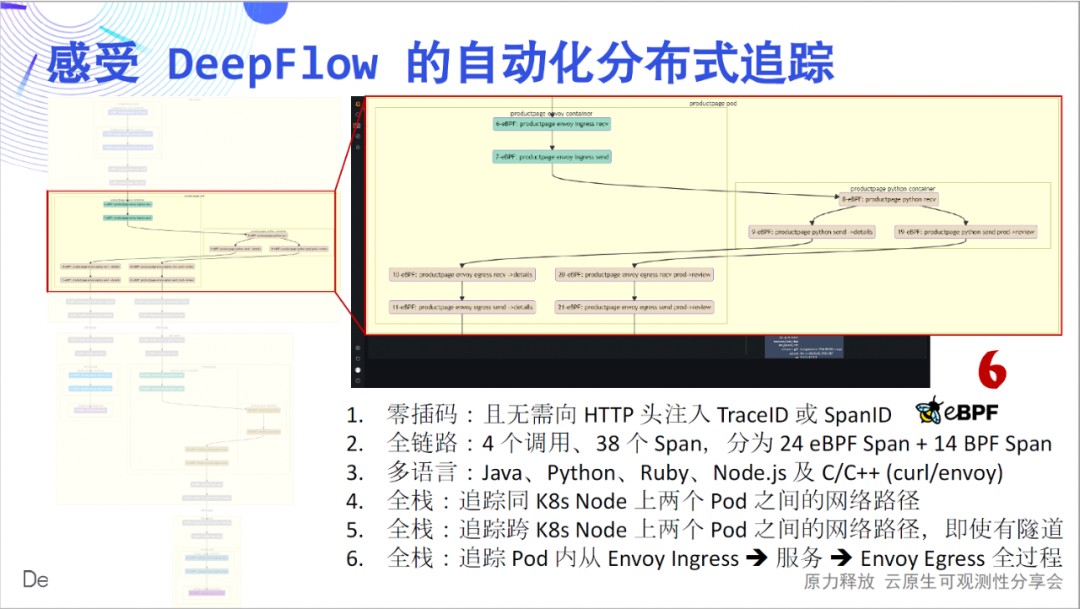
Mirando hacia atrás a los seis puntos anteriores, creo que todas son innovaciones geniales, y creo que todos creerán lo mismo. Esta demostración también se describe en detalle en nuestra documentación , bienvenido a experimentarla.
Dado que se trata de un trabajo innovador, existe una alta probabilidad de que haya algunos defectos en la etapa inicial. En la actualidad, hemos podido resolver a la perfección el seguimiento automático en escenarios de bloqueo de IO (BIO), así como el seguimiento automático de la mayoría de las puertas de enlace de balanceo de carga y API (Nginx, HAProxy, Envoy, etc.), que a menudo utilizan no- bloqueo de E/S síncrona (NIO). Sin embargo, todos los escenarios de E/S asíncrona (AIO), como subprocesos ligeros, corrutinas, etc., aún no se han resuelto. Nuestro trabajo todavía está en progreso, y ha habido un buen progreso. Planeamos compartir con ustedes el desmantelamiento de principios técnicos profundos en QCon 2022 .
AutoTracing es bueno, pero es difícil resolver el seguimiento de llamadas entre funciones específicas dentro de la aplicación. Afortunadamente, toda la comunidad de código abierto ha acumulado más de 10 años en este sentido, desde la fundación de Google Dapper hace 12 años, hasta la popularidad de SkyWalking y luego hasta el estándar unificado de OpenTelemetry en la actualidad. Entonces, ¿qué tipo de combinación puede tener DeepFlow con ellos?
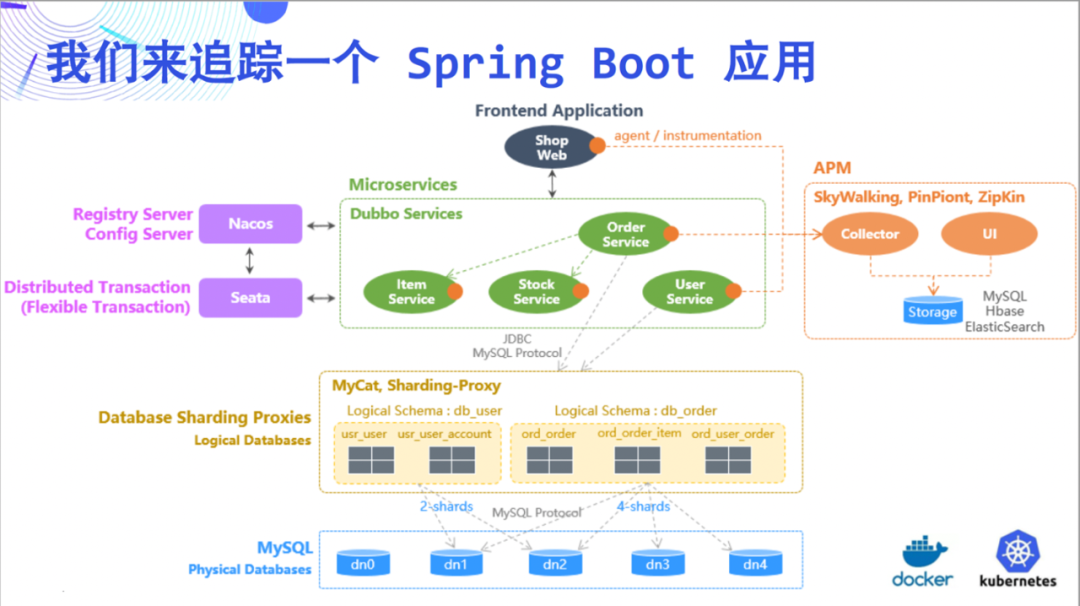
Esta vez, tratamos de rastrear una
aplicación Spring Boot como ejemplo para ilustrar las increíbles capacidades de DeepFlow. Esta demostración es relativamente simple, consta de 5 microservicios y MySQL.
Primero echemos un vistazo al
efecto de seguimiento de OpenTelemetry + Jaeger, esta vez no está vacío, se muestran 46 tramos en la página.
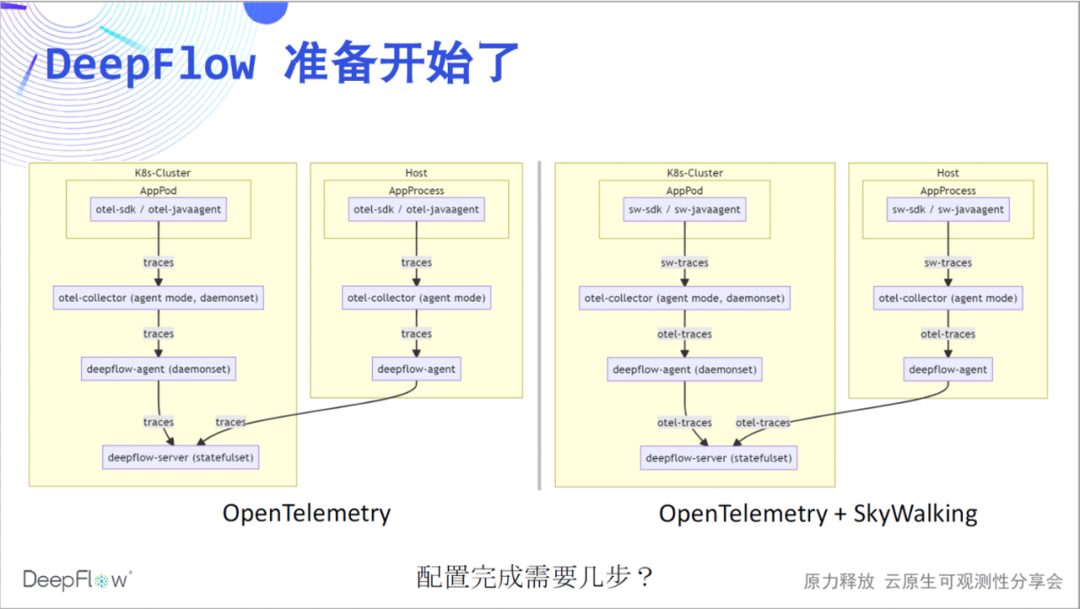
Comencemos la actuación de DeepFlow. Recomendamos usar el modo de agente de otel-collector para enviar rastros al servidor de deepflow a través de deepflow-agent. Del mismo modo, la integración de los datos de SkyWalking se implementa actualmente a través del otel-colector. Ahora puede adivinar cuántos pasos necesitamos para completar nuestro trabajo de configuración.
Dado que la transmisión en vivo se ha llevado a cabo hasta ahora, creo que no hay suspenso. Podemos pasar por OpenTelemetry y DeepFlow en dos pasos.
otlphttp: traces_endpoint: "http://${HOST_IP}:38086/api/v1/otel/trace" tls: insecure: true retry_on_failure: enabled: true vtap_group_id: <your-agent-group-id> external_agent_http_proxy_enabled: 1 # 默认关闭,零端口监听
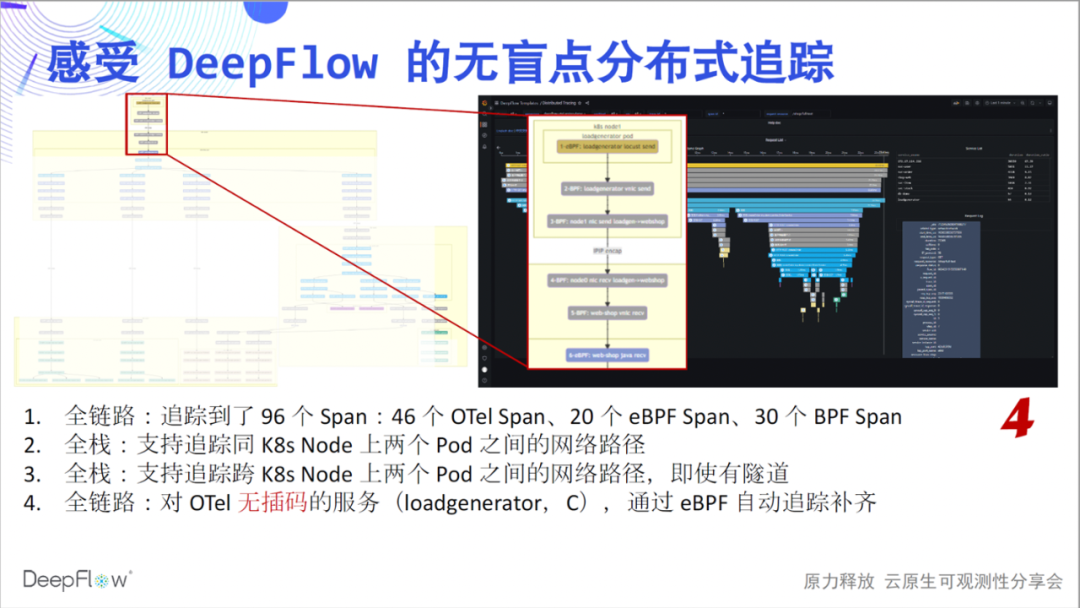
Así que echemos un vistazo a las capacidades de seguimiento integradas de DeepFlow. Este gráfico de llamas ahora parece plano, pero tiene un misterio oculto. Descubramos lentamente su misterioso velo y sintamos el impacto del seguimiento sin puntos ciegos: enlace completo, es la primera sensación que queremos para transmitir. En comparación con los 46 tramos mostrados por Jaeger, DeepFlow rastreó 20 tramos eBPF y 30
tramos BPF adicionales. Primero tenemos una sensación numérica, y veremos más misterios capa por capa.
Full stack es la segunda sensación que queremos transmitir. Nuestra capacidad de seguimiento de rutas de red sigue siendo estable y muestra claramente las rutas de acceso entre Pods. La pila completa también se mostrará en el escenario de comunicación entre nodos en este momento, sin importar si hay encapsulación de túnel o no, sin importar qué protocolo de túnel se use.
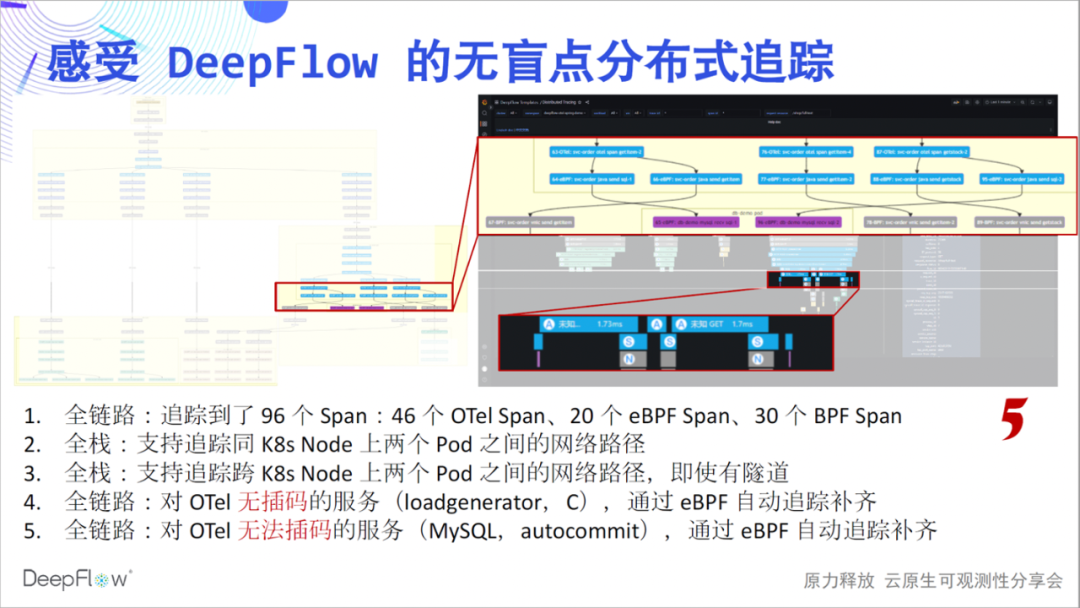
Todo el enlace, nos gustaría seguir comunicándonos. Eche un vistazo más de cerca a los 6 tramos en la parte superior de la imagen. Esto se debe a que el servicio del generador de carga no realiza interpolación y OpenTelemetry no puede brindar su ruta de seguimiento, pero al usar la capacidad de seguimiento de DeepFlow, se completan automáticamente 6 eBPF y tramos de BPF, y no hay necesidad de hacer nada manualmente en todo el proceso.
Enlace completo, aún queremos seguir comunicándonos. Mirando esta parte del lapso en la figura, eBPF encontró automáticamente dos conjuntos de lapsos de eBPF antes y después de una serie de lapsos de OTel, que son el principio y el final de las transacciones de MySQL, lo cual es genial. Me preguntaba qué tipo de comentarios en el sitio recibiríamos si pudiéramos compartir estas capacidades con ustedes a través de actividades fuera de línea si no hubiera una epidemia.
无盲点,是我们想传达出来的第六个感受。我们看图中这段 Span,第一行的客户端调用和最后一行的服务端响应出现了显著的时差。这个时候一般上下游团队会去争吵,到底是谁的问题。DeepFlow 就像一个裁判,谈笑间回答了这里面的玄机。从图中我们能看到,靠近客户端的位置虽然 OpenTelemetry Span 的时延大,但 eBPF Span 时延明显降低了,云原生环境不再是一个黑盒,看的一清二楚。我相信大家此时应该也能感受到满满的团队协作感,再也不用争吵了。
我们的文档中也对这个 Demo 进行了详细介绍,欢迎上手体验。另一方面,我们的 AutoTagging 能力也适用于追踪数据,我们会为所有的 Span 自动注入了大量标签。我们不再需要配置过多的 otel-collector
processor 用于标签注入了,一切都是自动的、高性能的、环保的。
那么 SkyWalking 呢。目前我们可以三步配置解决 SkyWalking 数据的集成,虽然多了一步,但相信对比上面的震撼,大家不会认为很麻烦。欢迎参考我们的文档上手体验。
receivers: skywalking: protocols: grpc: endpoint: 0.0.0.0:11800 http: endpoint: 0.0.0.0:12800 service: pipelines: traces: receivers: [skywalking] spec: ports: - name: sw-http port: 12800 protocol: TCP targetPort: 12800 - name: sw-grpc port: 11800 protocol: TCP targetPort: 11800 vtap_group_id: <your-agent-group-id> external_agent_http_proxy_enabled: 1 # required
同样,我们的多集群、异构环境监控能力在追踪场景下仍然是就绪的,整个数据平台仍然不需要外部组件就能水平扩展。
是的,我们也依然还有一系列未来的工作。包括不经过 otel-collector 直接集成 SkyWalking 数据,包括集成 Sentry 数据以解锁 RUM 能力。目前我们的追踪数据通过自己实现的 Grafana Panel 来展现,我想对接 Tempo 应该是一个不错的主意。
Finalmente, como revisión, acumularemos las palabras clave de DeepFlow mencionadas hoy, y no enfatizaré estas palabras clave débiles una por una aquí. Ahora digo que DeepFlow ha llevado la observabilidad a una nueva era de alta automatización, creo que ya no tendrá dudas. Creemos que DeepFlow es un regalo para los desarrolladores y operadores de la nueva era.
Esperamos que los desarrolladores puedan tener más tiempo para concentrarse en el negocio, dar más visibilidad al DeepFlow automatizado y hacer que su código sea más limpio y ordenado. Debajo de esta imagen, adjunté el discurso de Tyler Treat: El futuro de las operaciones. Tyler explicó los desafíos y las oportunidades de las operaciones en la era nativa de la nube hace unos años. Lo compartiré con los estudiantes de operación y mantenimiento. Aquí también rindo homenaje a Tyler, y también creo que DeepFlow puede ser del agrado de Ops en la nueva era.
Quizás se pregunte por qué no hablamos de registros hoy. DeepFlow ha trabajado un poco en esta área, pero siempre ha estado asombrado en este campo. El próximo mes, presentaremos el estado actual y los planes de DeepFlow en términos de registros junto con la comunidad nativa de la nube y Alibaba Cloud iLogTail. Usted está Bienvenido a prestar atención.
Queremos construir una plataforma de observabilidad de código abierto de clase mundial. Todavía queda un largo camino por recorrer, como escalar el Monte Everest. Si el número de versión actual de DeepFlow se traduce en altitud, puede corresponder exactamente entre el Campamento 2 y el Campamento 3. ¡Nos vemos en la cima de 8848! ¡gracias a todos!
¡Vaya a la dirección del almacén de DeepFlow!