
Presta atención, no te pierdas en productos secos 👆
Había un problema
¡Hay una alarma! ! !
Un día, cuando estaba moviendo ladrillos, descubrí que algunas instancias del servicio bytedance.xiaoming de un microservicio tenían demasiada memoria, alcanzando el 80 %. Y es que hace mucho tiempo que este servicio no lanza una nueva versión, por lo que se pueden descartar los problemas que introduce el nuevo código online.
Después de encontrar un problema, primero se migraron las instancias. Excepto por una instancia, que se reservó para solucionar problemas, el resto de las instancias se migraron. Después de la migración, la memoria de la nueva instancia era baja. Sin embargo, se encuentra que la memoria de la instancia migrada también aumenta lentamente con el tiempo y hay una pérdida de memoria.
identificar el problema
Especulación 1: Sospecha de escape goroutine
Proceso de solución de problemas
Por lo general, la causa principal de las fugas de memoria son demasiadas rutinas, así que antes que nada, sospecho si hay un problema con las rutinas. Fui a ver las rutinas y descubrí que son normales, la cantidad total es baja y no hay crecimiento continuo. (Olvidé tomar una captura de pantalla en ese momento y luego agregué una imagen, pero la cantidad de rutinas no ha cambiado)
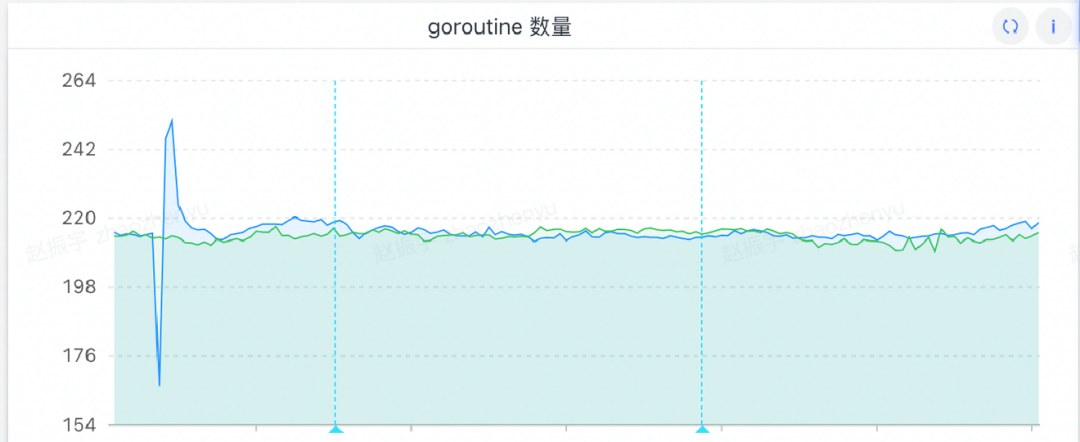
Resultados de la solución de problemas
No hay problemas de escape de goroutine.
Especulación 2: se sospecha que el código tiene una pérdida de memoria
Proceso de solución de problemas
Realice una recopilación de memoria en tiempo real a través de pprof y compare el uso de memoria de la instancia del problema y la instancia normal:
Ejemplo de problema:

Ejemplo normal:

Mire más a fondo el gráfico de la instancia del problema:
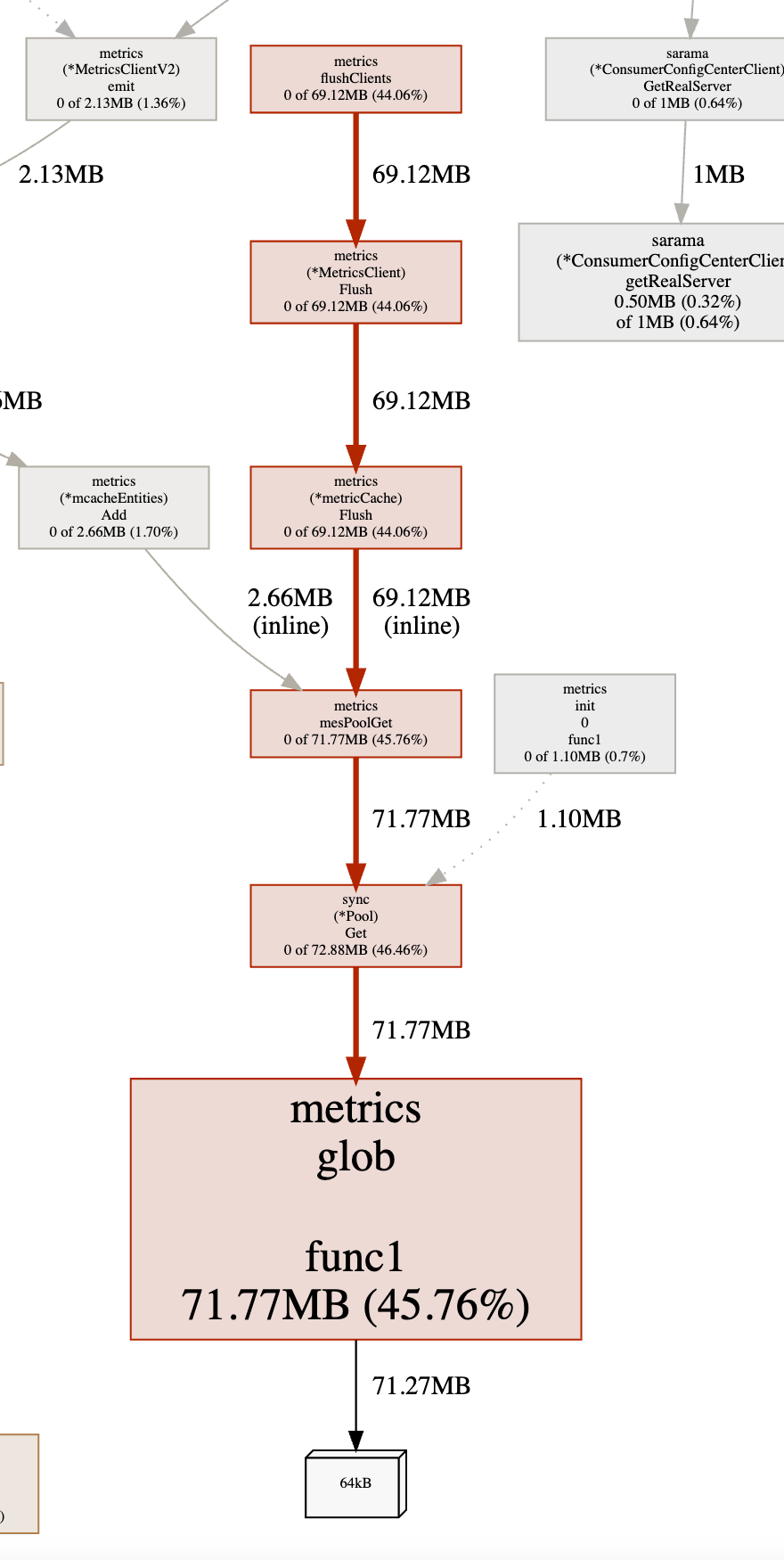
Se puede encontrar a partir de esto que metircs.flushClients() ocupa la mayor parte de la memoria. Para localizar el código fuente:
func (c *tagCache) Set(key []byte, tt *cachedTags) {
if atomic.AddUint64(&c.setn, 1)&0x3fff == 0 {
// every 0x3fff times call, we clear the map for memory leak issue
// there is no reason to have so many tags
// FIXME: sync.Map don't have Len method and `setn` may not equal to the len in concurrency env
samples := make([]interface{}, 0, 3)
c.m.Range(func(key interface{}, value interface{}) bool {
c.m.Delete(key)
if len(samples) < cap(samples) {
samples = append(samples, key)
}
return true
}) // clear map
logfunc("[ERROR] gopkg/metrics: too many tags. samples: %v", samples)
}
c.m.Store(string(key), tt)
}
Se encuentra que para evitar pérdidas de memoria, las claves almacenadas en sync.Map se han limpiado contando. En teoría no debería haber problema.
Resultados de la solución de problemas
No hay errores de código que causen pérdidas de memoria.
Especulación 3: Se sospecha que es el problema de RSS
Proceso de solución de problemas
En este momento, me di cuenta de una cosa. En pprof, vi que las métricas solo ocupaban 72 MB en total, y la memoria del montón total era solo de más de 170 MB. Nuestra instancia está configurada con 2 GB de memoria y ocupa el 80 % de la memoria. significa que el RSS ocupa alrededor de 1,6 GB, estos dos son muy inconsistentes (más adelante se presentará una solución temporal a este problema), lo que no debería causar una alarma de uso de memoria del 80%. Por lo tanto, la conjetura es que la memoria no se recupera a tiempo.
Después de investigar, encontré esta cosa mágica:
Durante mucho tiempo, cuando el tiempo de ejecución de go libera memoria y regresa al kernel, se usa en Linux MADV_DONTNEED, aunque la eficiencia es relativamente baja, pero la cantidad de RSS (conjunto de memoria residente de tamaño de conjunto residente) disminuye rápidamente. Sin embargo, en go 1.12, está especialmente optimizado para esto, cuando el tiempo de ejecución libera memoria, usa una más eficiente MADV_FREE en lugar de la anterior MADV_DONTNEED. Una introducción detallada se puede encontrar aquí:
https://go-review.googlesource.com/c/go/+/135395/
El texto original actualizado de go1.12:
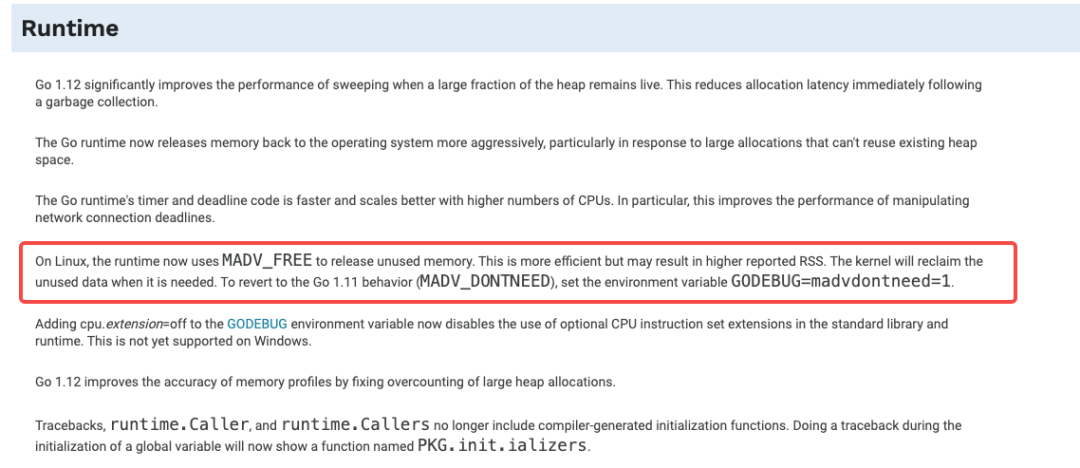
El tiempo de ejecución Go 1.12~1.15 optimiza la estrategia de GC. Cuando sea compatible con la versión del kernel de Linux (> 4.5), se adoptará una estrategia más "agresiva" de manera predeterminada para hacer que la reutilización de la memoria sea más eficiente, la latencia más baja y muchas otras optimizaciones. La desventaja es que RSS no cae inmediatamente, sino que se retrasa hasta que la memoria está bajo presión.
Nuestra versión go es 1.15, la versión kernel es 4.14, ¡simplemente haz el truco!
Resultados de la solución de problemas
La versión del compilador go + la versión del kernel del sistema alcanza la estrategia gc de tiempo de ejecución de go, de modo que el RSS no se caerá después de que se recupere la memoria del montón.
problema resuelto
Solución
Hay dos soluciones:
-
Una es especificar en la variable de entorno GODEBUG=madvdontneed=1
Este método puede obligar al tiempo de ejecución a continuar usando
MADV_DONTNEED(Referencia: https://github.com/golang/go/issues/28466). Pero después de iniciar Madvise no es necesario, desencadenará el derribo de TLB y más fallas de página. Las empresas sensibles a la latencia pueden verse más afectadas. Por lo tanto, esta variable de entorno debe usarse con precaución.
-
Actualice la versión del compilador go a una versión superior a la 1.16
Consulte las notas de actualización para go 1.16. Esta estrategia de GC se ha abandonado y la memoria se libera a tiempo en lugar de una liberación perezosa cuando la memoria está bajo presión. Parece que el sitio web oficial de go también piensa que la forma de liberar la memoria a tiempo es más preferible, y es más apropiada en la mayoría de los casos.
Adjunto: para resolver el problema de que el montón utilizado por pprof es mucho más pequeño que RSS, se puede resolver llamando manualmente a debug.FreeOSMemory, pero hay un precio para realizar esta operación.

Al mismo tiempo, FreeOSMemory no funciona en la versión go1.13 (https://github.com/golang/go/issues/35858), se recomienda usarlo con precaución.
Resultados de la implementación
Elegimos la opción dos. Después de actualizar go1.16, la instancia no muestra el fenómeno de que la memoria continúa creciendo rápidamente.
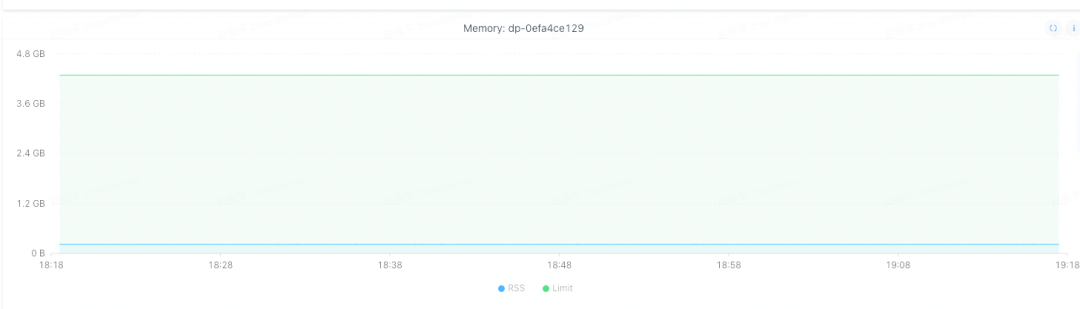
Use pprof nuevamente para ver la situación de la instancia y descubra que las funciones que ocupan memoria también cambian. El metrics.glob que solía ocupar memoria se ha caído. Parece que esta solución está funcionando.
Otros pozos encontrados
Otro problema que puede causar fugas de memoria (este servicio no se ve afectado) se encontró durante el proceso de resolución de problemas.Si la malla no está habilitada, el componente de detección de servicios de kitc tiene el riesgo de fugas de memoria.
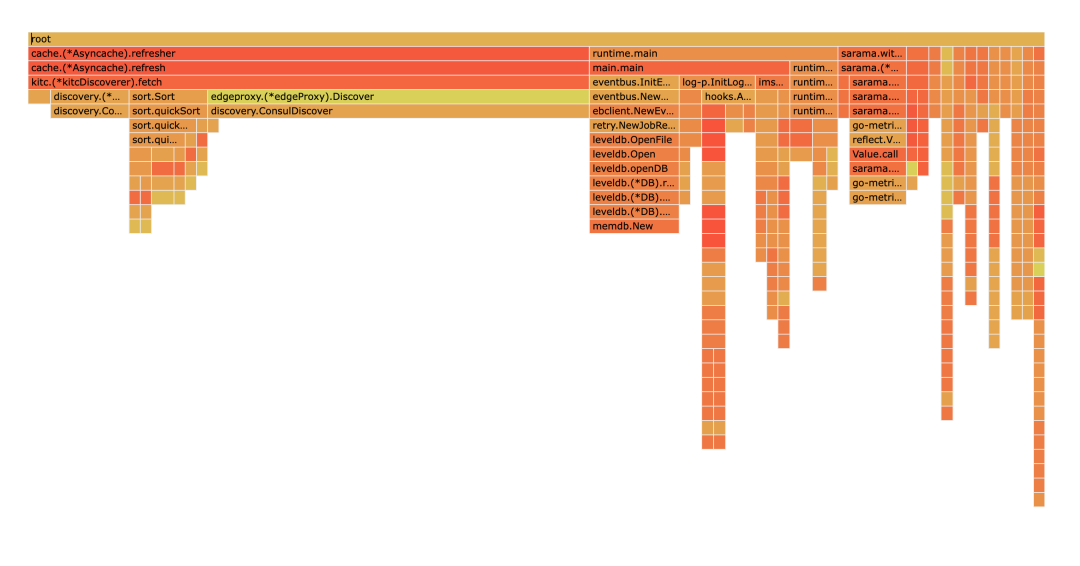
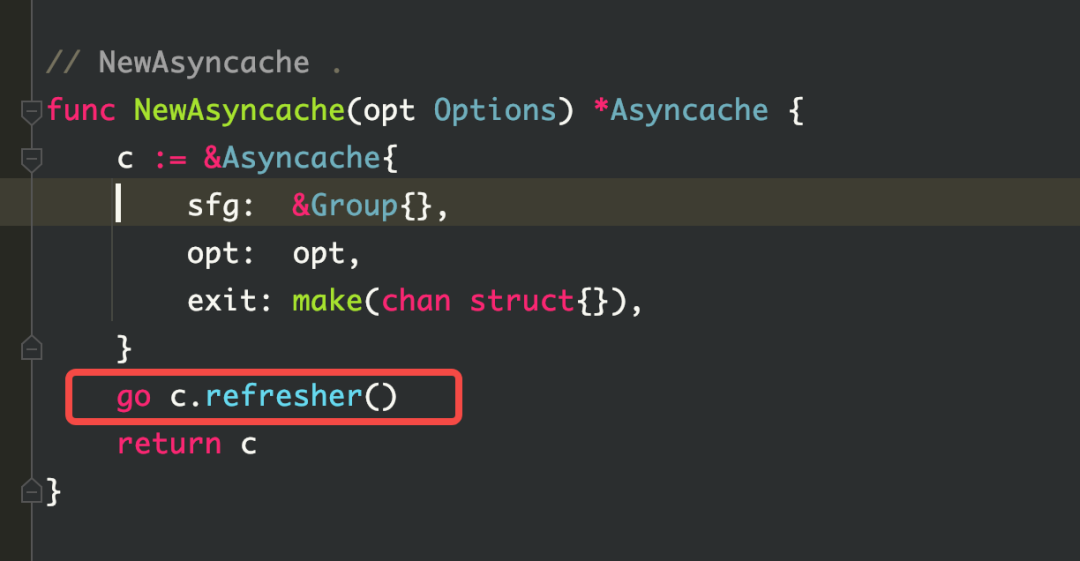
Como se puede ver en la figura, la memoria caché.(*Asynccache).refresher ocupa mucha memoria y, a medida que aumenta el volumen de procesamiento comercial, su uso de memoria seguirá creciendo.
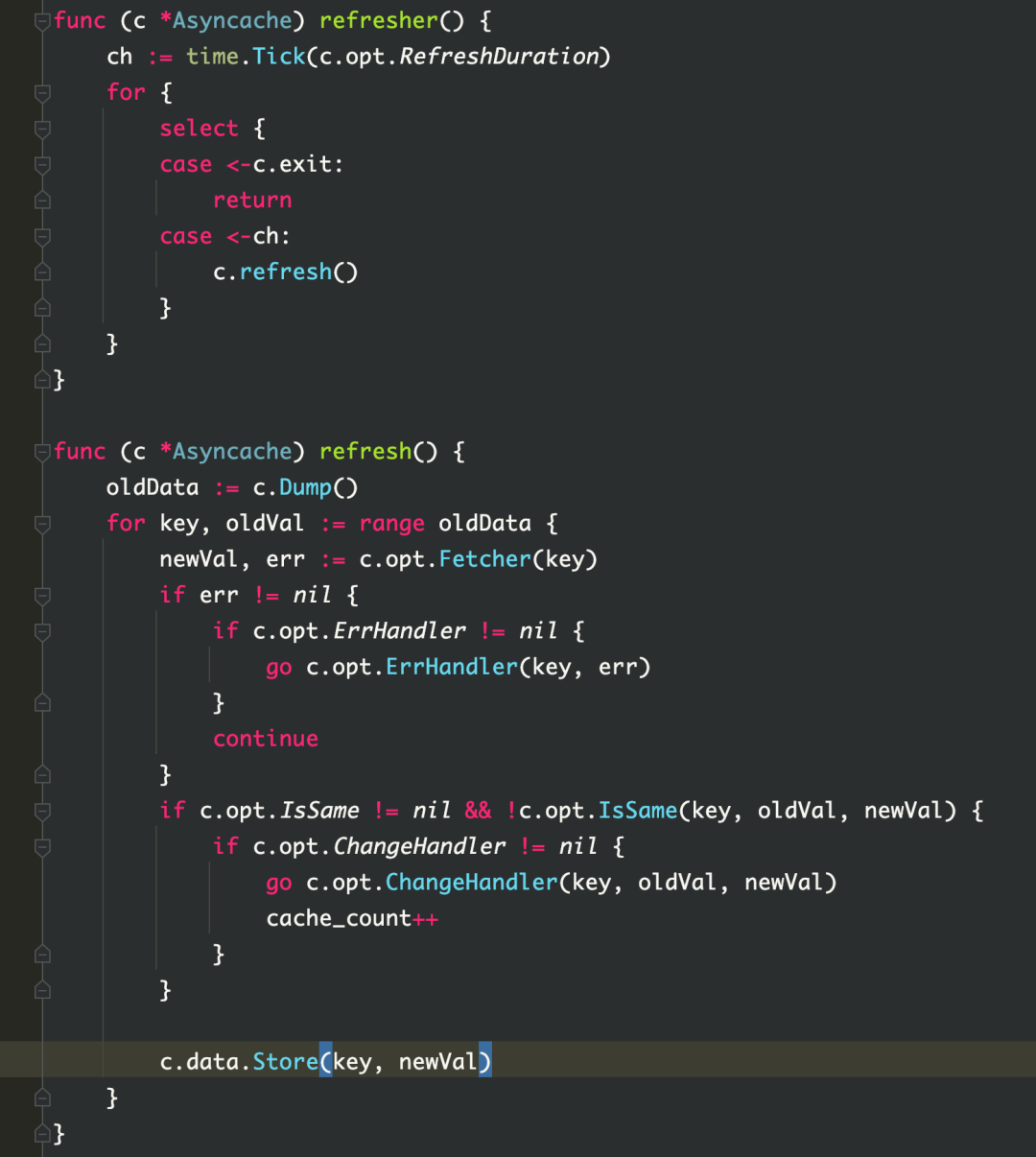
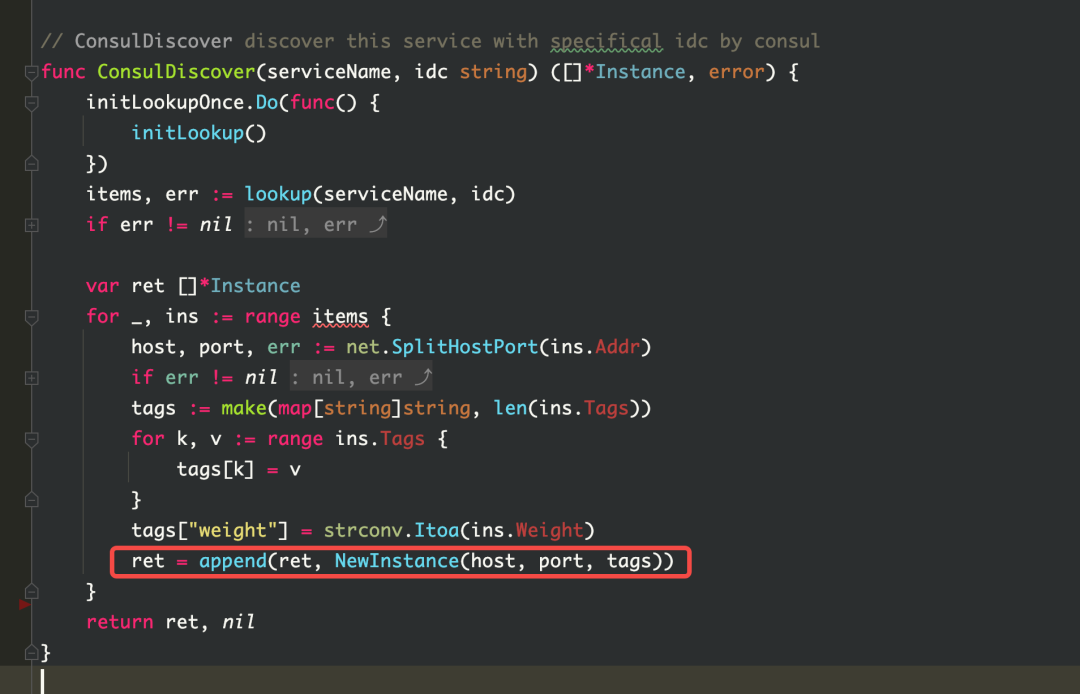
Es natural pensar que cuando un kiteclient se crea de nuevo, puede haber casos en los que el cliente se construya repetidamente. Por lo tanto, se llevó a cabo la inspección del código y no se encontró ninguna construcción repetida. Pero mirando el código fuente de kitc, puede encontrar que cuando se descubre el servicio, se establece un grupo de caché asynccache en kitc para almacenar la instancia. Este grupo de búfer se actualizará cada 3 segundos y se llamará a fetch cuando se actualice, y fetch realizará el descubrimiento de servicios. Durante el descubrimiento del servicio, las instancias se crearán continuamente de acuerdo con el host, el puerto y las etiquetas de la instancia (que se cambiarán de acuerdo con el entorno env), y luego las instancias se almacenarán en el grupo de caché asynccache. se limpia y la memoria no se libera. Entonces esto es lo que causó la pérdida de memoria.
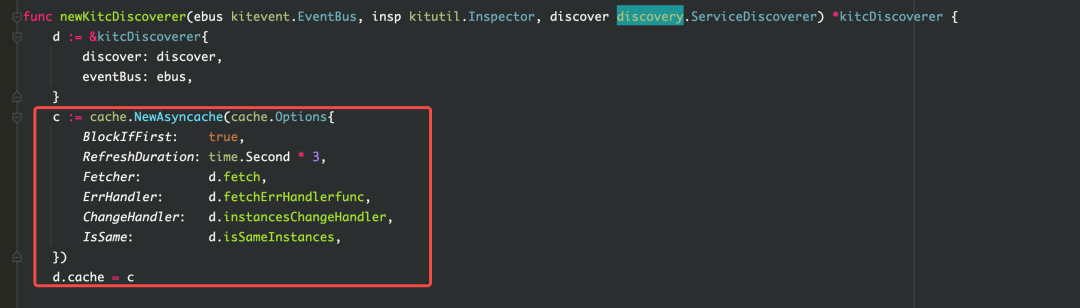
Solución
El proyecto es relativamente antiguo, por lo que el marco utilizado es relativamente antiguo. Este problema se puede resolver actualizando el último marco.
resumen de pensamiento
Primero defina qué es una pérdida de memoria:
La fuga de memoria (Memory Leak) se refiere al hecho de que la memoria del montón asignada dinámicamente en el programa no se libera o no se puede liberar por algún motivo, lo que resulta en una pérdida de memoria del sistema, lo que tiene consecuencias graves, como ralentizar el programa e incluso fallo del sistema.
Escenarios comunes
En el escenario Go, los problemas comunes de pérdida de memoria son los siguientes:
1. goroutine causa pérdida de memoria
(1) Demasiadas aplicaciones goroutine
Resumen del problema:
Demasiadas aplicaciones de rutinas y la tasa de crecimiento es más rápida que la tasa de lanzamiento, lo que conducirá a más y más rutinas.
Ejemplo de escenario:
Se crea un nuevo cliente para una solicitud. Cuando el volumen de solicitudes comerciales es grande, se crean demasiados clientes y es demasiado tarde para liberarlos.
(2) bloqueo de rutinas
① Problema de E/S
Resumen del problema:
La conexión de E/S no tiene un tiempo de espera establecido, lo que hace que la rutina go espere todo el tiempo.
Ejemplo de escenario:
Al solicitar una interfaz de conexión de red de terceros, el resultado devuelto no se ha recibido debido a problemas de red.Si no se establece el período de tiempo de espera, el código siempre se bloqueará.
② Mutex no se libera
Resumen del problema:
La gorutina no puede adquirir el recurso de bloqueo, lo que hace que la gorutina se bloquee.
Ejemplo de escenario:
Suponiendo que hay una variable compartida, goroutineA bloquea la variable compartida pero no la libera, por lo que otras goroutineB, goroutineC, ..., goroutineN no pueden obtener el recurso de bloqueo, lo que hace que otras gorutinas se bloqueen.
③ Uso inadecuado de grupo de espera
Resumen del problema:
El número de Agregar, Listo y esperar del grupo de espera no coincide, lo que hará que la espera espere todo el tiempo.
Ejemplo de escenario:
WaitGroup puede entenderse como un administrador de rutinas. Necesita saber cuántas gorutinas están trabajando para él y debe notificarle cuando haya terminado, de lo contrario, esperará hasta que todos los hermanos pequeños hayan terminado. Después de agregar WaitGroup, el programa esperará hasta que reciba una cantidad suficiente de señales Done(). Supongamos que el grupo de espera agrega (2), Listo (1), luego queda una tarea sin terminar en este momento, por lo que el grupo de espera esperará todo el tiempo. Para obtener más información, consulte el capítulo sobre grupos de espera en Goroutine Exit Mechanism.
2. seleccionar bloqueo
Resumen del problema:
Use select pero el caso no está completamente cubierto, lo que da como resultado que no esté listo y, finalmente, la goroutine se bloquea.
Ejemplo de escenario:
Suele ocurrir cuando el caso de selección no está completamente cubierto y no hay un valor predeterminado, lo que provocará el bloqueo. El código de ejemplo es el siguiente:
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
ch3 := make(chan int)
go Getdata("https://www.baidu.com",ch1)
go Getdata("https://www.baidu.com",ch2)
go Getdata("https://www.baidu.com",ch3)
select{
case v:=<- ch1:
fmt.Println(v)
case v:=<- ch2:
fmt.Println(v)
}
}
3. Bloqueo de canales
Resumen del problema:
-
bloqueo de escritura -
El bloqueo de un canal sin búfer suele ser un bloqueo de operación de escritura porque no hay lectura. -
El canal almacenado en búfer escribe bloqueado porque el búfer está lleno -
bloqueo de lectura -
Esperando leer datos del canal, el resultado es que no hay goroutine para escribir
Ejemplo de escenario:
Los errores de código por las tres razones anteriores pueden causar el bloqueo de canales. Aquí hay algunos ejemplos de bloqueo de canales reales en entornos de producción:
-
Resumen de errores de la máquina de la biblioteca Lark_cipher -
Cipher Goroutine Análisis de fugas
4. Uso inadecuado de temporizadores
(1) Uso inadecuado de time.after()
Resumen del problema:
默认的 time.After()是会有内存泄漏问题的,因为每次 time.After(duratiuon x)会产生 NewTimer(),在 duration x 到期之前,新创建的 timer 不会被 GC,到期之后才会 GC。
那么随着时间推移,尤其是 duration x 很大的话,会产生内存泄漏的问题。
场景举例:
func main() {
ch := make(chan string, 100)
go func() {
for {
ch <- "continue"
}
}()
for {
select {
case <-ch:
case <-time.After(time.Minute * 3):
}
}
}
(2)time.ticker 未 stop
问题概述:
使用 time.Ticker 需要手动调用 stop 方法,否则将会造成永久性内存泄漏。
场景举例:
func main(){
ticker := time.NewTicker(5 * time.Second)
go func(ticker *time.Ticker) {
for range ticker.C {
fmt.Println("Ticker1....")
}
fmt.Println("Ticker1 Stop")
}(ticker)
time.Sleep(20* time.Second)
//ticker.Stop()
}
建议:总是建议在 for 之外初始化一个定时器,并且 for 结束时手工 stop 一下定时器。
5. slice 引起内存泄露
问题概述:
-
两个 slice 共享地址,其中一个为全局变量,另一个也无法被 gc; -
append slice 后一直使用,未进行清理。
场景举例:
-
直接上代码,采用此方式,b 数组是不会被 gc 的。
var a []int
func test(b []int) {
a = b[:3]
return
}
-
在遇到的其他坑里提到的 kitc 的服务发现代码就是这个问题的示例。
排查思路总结
今后遇到 golang 内存泄漏问题可以按照以下几步进行排查解决:
-
观察服务器实例,查看内存使用情况,确定内存泄漏问题;
-
可以在 tce 平台上的【实例列表】处直接点击;
-
也可以在 ms 平台上的【运行时监控】进行查看;
-
判断 goroutine 问题;
-
这里可以使用 1 中提到的监控来观察 goroutine 数量,也可以使用 pprof 进行采样判断,判断 goroutine 数量是否出现了异常增长。
-
判断代码问题;
-
利用 pprof,通过函数名称定位具体代码行数,可以通过 pprof 的 graph、source 等手段去定位; -
排查整个调用链是否出现了上述场景中的问题,如 select 阻塞、channel 阻塞、slice 使用不当等问题,优先考虑自身代码逻辑问题,其次考虑框架是否存在不合理地方;
-
解决对应问题并在测试环境中观察,通过后上线进行观察;
推荐的排查工具
-
pprof: 是 Go 语言中分析程序运行性能的工具,它能提供各种性能数据包括 cpu、heap、goroutine 等等,可以通过报告生成、Web 可视化界面、交互式终端 三种方式来使用 pprof -
Nemo:基于 pprof 的封装,采样单个进程 -
ByteDog:在 pprof 的基础上提供了更多指标,采样整个容器/物理机 -
Lidar:基于 ByteDog 的采样结果分类展示(目前是平台方更推荐的工具,相较于 nemo 来说) -
睿智的 oncall 小助手:kite 大佬研究的排查问题小工具,使用起来很方便,在群里 at 机器人,输入 podName 即可
加入我们
飞书是字节跳动旗下先进企业协作与管理平台,围绕目标、信息与人三个维度全方位助力组织升级。一站式整合即时沟通、日历、音视频会议、文档、云盘等办公协作套件,让组织和个人工作更高效更愉悦。飞书目前已服务包括互联网、信息技术、制造、建筑地产、教育、媒体在内等众多领域的先进企业。我们是飞书的Lark Core Services 团队,负责飞书核心的 IM 领域能力,包括消息、群组、用户资料、开放能力等等。期待您的加入~
社招链接:
https://job.toutiao.com/s/Ne1ovPK
校招链接(暑期实习)
https://jobs.toutiao.com/s/NJ3oxsp
 点击“阅读原文”了解岗位详情!
点击“阅读原文”了解岗位详情!