|Este artículo proviene de: blog 51cto
Algunas prácticas para el monitoreo de aplicaciones con Promethues
En este artículo presentamos cómo usar Prometheus para monitorear aplicaciones. En el trabajo de seguimiento, con la profundización del monitoreo, combinamos nuestra propia experiencia y documentos oficiales para resumir algunas prácticas de Métricas. Espero que estas prácticas puedan proporcionarle una referencia.
Determinar qué monitorear
Antes del diseño específico de Metrics, primero es necesario aclarar los objetos que necesitan ser medidos. Los objetos que deben medirse deben determinarse de acuerdo con los antecedentes del problema específico, los requisitos y el sistema que se monitoreará.
Empezar con las necesidades
Basado en la experiencia de una gran cantidad de monitoreo distribuido, Google ha resumido cuatro indicadores dorados de monitoreo, y estos cuatro indicadores tienen una buena importancia de referencia para objetos de monitoreo y medición generales. Los cuatro indicadores son:
-
Latencia: El tiempo para atender la solicitud.
-
Tráfico: monitorea el tráfico actual del sistema para medir las necesidades de capacidad del servicio.
-
Errores: Supervise todas las solicitudes de error que se producen en el sistema actual y mida la tasa a la que se producen errores en el sistema actual.
-
Saturación: Mide la saturación del servicio actual. El énfasis principal está en los recursos limitados que más afectan el estado del servicio. Por ejemplo, si el sistema se ve afectado principalmente por la memoria, concéntrese principalmente en el estado de la memoria del sistema.
Los cuatro indicadores anteriores son en realidad para cumplir con los cuatro requisitos de monitoreo:
-
Refleje la experiencia del usuario y mida el rendimiento central del sistema. Tales como: el retraso del sistema en línea, el tiempo de finalización del trabajo del sistema informático del trabajo, etc.
-
Refleja el rendimiento del sistema. Tales como: la cantidad de solicitudes, el tamaño de los paquetes de red enviados y recibidos, etc.
-
Ayuda a encontrar y localizar fallas y problemas. Tales como: recuento de errores, tasa de fallas de llamadas, etc.
-
Refleja la saturación y la carga del sistema. Tales como: la memoria ocupada por el sistema, la longitud de la cola de trabajos, etc.
Además de los requisitos convencionales anteriores, de acuerdo con escenarios de problemas específicos, para eliminar y descubrir problemas que han ocurrido o pueden ocurrir antes, se pueden determinar los objetos de medición correspondientes. Por ejemplo, la interfaz de una biblioteca a la que el sistema necesita llamar con frecuencia puede tardar mucho tiempo o fallar ocasionalmente. Se pueden formular métricas para medir el retraso y la cantidad de fallas de esta interfaz.
Comience con el sistema que necesita ser monitoreado
Para cumplir con los requisitos correspondientes, los objetos de medición que los diferentes sistemas deben observar también son diferentes. En la mejor práctica del documento oficial, las aplicaciones que necesitan ser monitoreadas se dividen en tres categorías:
-
Sistemas de servicio en línea: necesita responder a la solicitud de inmediato y el solicitante esperará la respuesta. como un servidor web.
-
Procesamiento sin conexión: el solicitante no espera una respuesta y el trabajo solicitado suele tardar mucho tiempo. Como el marco de computación por lotes Spark, etc.
-
Trabajos por lotes: este tipo de aplicaciones suelen ser únicas, no se ejecutan todo el tiempo y finalizan cuando se completa la operación. Como trabajos de MapReduce para análisis de datos.
Los objetos que se suelen medir son diferentes para cada tipo de aplicación. Su resumen es el siguiente:
-
Sistema de servicio en línea: incluye principalmente solicitudes, el número de errores y la demora de las solicitudes.
-
Sistema informático fuera de línea: la última vez que se procesó el trabajo, la cantidad de trabajos que se están procesando actualmente, cuántos elementos se han enviado, la duración de la cola de trabajos, etc.
-
Trabajo por lotes: el momento de la última ejecución exitosa, el tiempo de ejecución de cada etapa principal, el tiempo total empleado, la cantidad de registros procesados, etc.
Además del sistema en sí, a veces es necesario monitorear subsistemas:
-
Bibliotecas utilizadas: el número de llamadas, el número de éxitos, el número de errores y el retraso de la llamada.
-
Registro: cuenta cada registro escrito para averiguar con qué frecuencia y cuándo se produce cada registro.
-
Fallos: Recuento de errores.
-
Grupo de subprocesos: número de solicitudes en cola, número de subprocesos en uso, número total de subprocesos, consumo de tiempo, número de tareas que se procesan, etc.
-
Caché: número de solicitudes, aciertos, latencia total, etc.
Seleccionar vector
El principio de elegir Vec:
-
Tipos de datos similares pero diferentes tipos de recursos, ubicaciones de recopilación, etc.
-
Unidad de datos dentro de Vec
ejemplo:
-
Solicitud de latencia para diferentes objetos de recursos
-
Solicitud de latencia para diferentes geoservidores
-
Recuento de diferentes errores de solicitud http…
Además, la documentación oficial sugiere que las diferentes operaciones de un objeto de recurso, como lectura/escritura, envío/recepción, deben registrarse en diferentes métricas, no en una métrica. La razón es que los dos generalmente no se agregan durante el monitoreo, sino que se observan por separado. Sin embargo, para la medición de la solicitud, se suele utilizar Label para distinguir diferentes acciones.
Determinar etiqueta
Las opciones de etiquetas comunes son:
-
recurso
-
región
-
escribe…
Un principio importante para determinar la Etiqueta es: los datos de la misma dimensión de la Etiqueta se pueden promediar y sumar, es decir, la unidad debe estar unificada. Por ejemplo, la velocidad y el voltaje del ventilador no se pueden colocar en una etiqueta.
Además, no se recomiendan las siguientes prácticas:
Copiar
mi_métrica{etiqueta=a} 1 mi_métrica{etiqueta=b} 6 mi_métrica{etiqueta=total} 7
1.
Es decir, tanto los puntos como los datos totales se cuentan en Label. Se recomienda usar PromQL para agregar en el lado del servidor para obtener el resultado total. O use otra métrica para medir los datos totales.
Nomenclatura de métricas y etiquetas
La buena denominación se puede ver por el nombre, por lo que la denominación también es parte de un buen diseño.
Denominación de métricas:
-
prometheus_notifications_total
-
proceso_cpu_segundos_total
-
ipamd_request_latency
-
Necesidad de ajustarse al patrón: a-zA-Z:
-
Debe contener una palabra como prefijo que indique el dominio al que pertenece esta métrica.me gusta:
-
Debe incluir una unidad de unidad como sufijo para indicar la unidad de esta métrica.me gusta:
-
http_request_duration_segundos
-
node_memory_usage_bytes
-
http_requests_total (para un conteo acumulativo sin unidades)
-
Lógicamente tiene el mismo significado que la variable que se está midiendo.
-
Trate de usar unidades básicas, como segundos, bytes. En lugar de Milisegundos, megabytes.
Nombre de la etiqueta:
Nombrado según la dimensión seleccionada, por ejemplo:
-
región: shenzhen/guangzhou/beijing
-
propietario: usuario1/usuario2/usuario3
-
etapa: extraer/transformar/cargar
Selección de cubos
Los cubos apropiados pueden hacer que el cálculo del percentil del histograma sea más preciso.
Idealmente, los cubos harán que la distribución de datos sea escalonada, es decir, la cantidad de datos en cada intervalo de cubo es aproximadamente la misma.
El diseño de baldes puede seguir la siguiente experiencia:
-
Necesita saber la distribución aproximada de los datos. Si no lo sabe de antemano, puede usar el depósito predeterminado ({.005, .01, .025, .05, .1, .25, .5, 1 , 2.5, 5, 10}) o 2 cubos múltiples ({1,2,4,8…}) observe la distribución de datos y luego ajuste los cubos.
-
Donde la distribución de datos es más densa, el intervalo del cubo se puede establecer más estrecho, y donde la distribución es escasa, se puede establecer más amplio.
-
Para la mayoría de los datos de retardo, generalmente tiene las características de cola larga y es más adecuado usar cubos exponenciales.
-
El límite superior del depósito inicial generalmente cubre alrededor del 10 % de los datos. Si no presta atención a los datos del encabezado, el límite superior del depósito inicial puede hacerse más grande.
-
Si desea calcular un percentil específico con mayor precisión, como el 90 %, puede cifrar los cubos de distribución en el 90 % de los datos, es decir, reducir el intervalo entre los cubos.
Por ejemplo, cuando superviso el tiempo que consumen algunas de nuestras tareas, elijo estimar el valor aproximado de la cubeta de acuerdo con la situación real. Después de conectarme, observo los datos y el monitoreo y luego ajusto la cubeta. Después de varios ajustes, debería poder ajustarse a un valor más apropiado.
Consejos Grafana
ver todas las dimensiones
Si desea saber si puede agrupar por otras dimensiones y ver rápidamente qué dimensiones están disponibles, puede usar el siguiente truco: mantenga solo el nombre de la métrica en la expresión de consulta, no haga ningún cálculo y deje el formato Leyenda en blanco. . Esto mostrará los datos métricos sin procesar. Como se muestra abajo
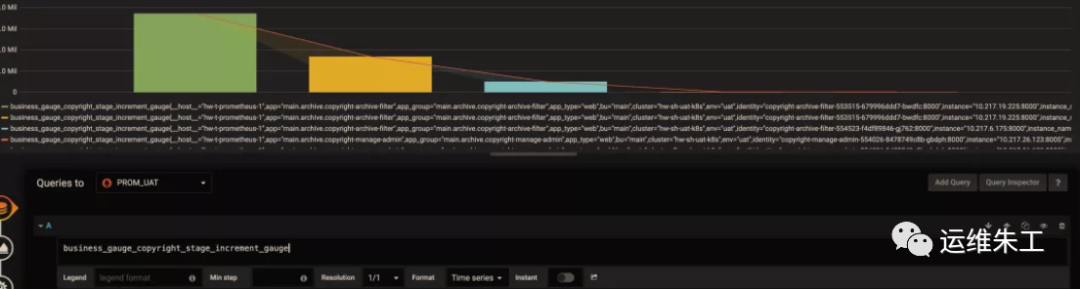
Enlace de regla
En el panel Configuración, hay un elemento de configuración Información sobre herramientas gráficas, Predeterminado se usa de forma predeterminada.
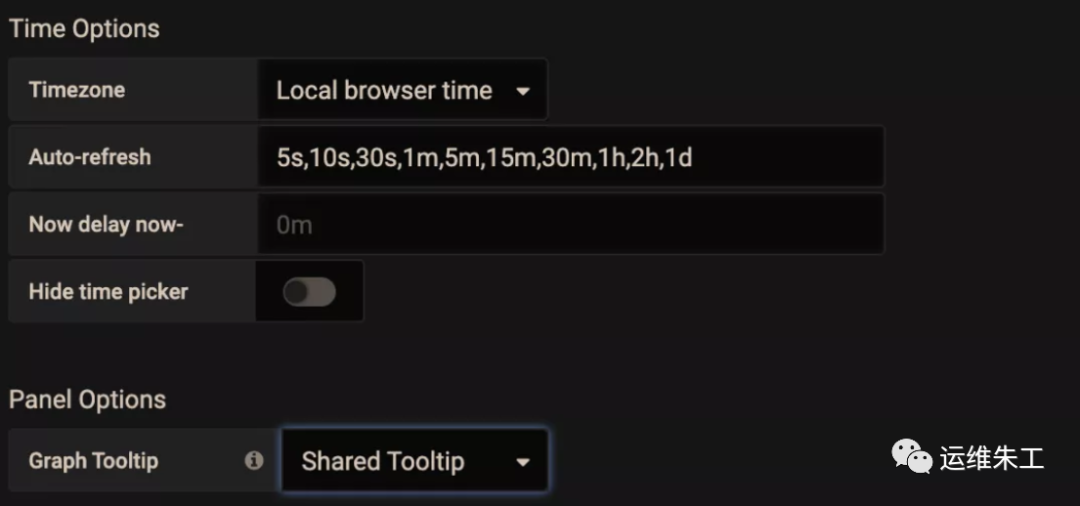
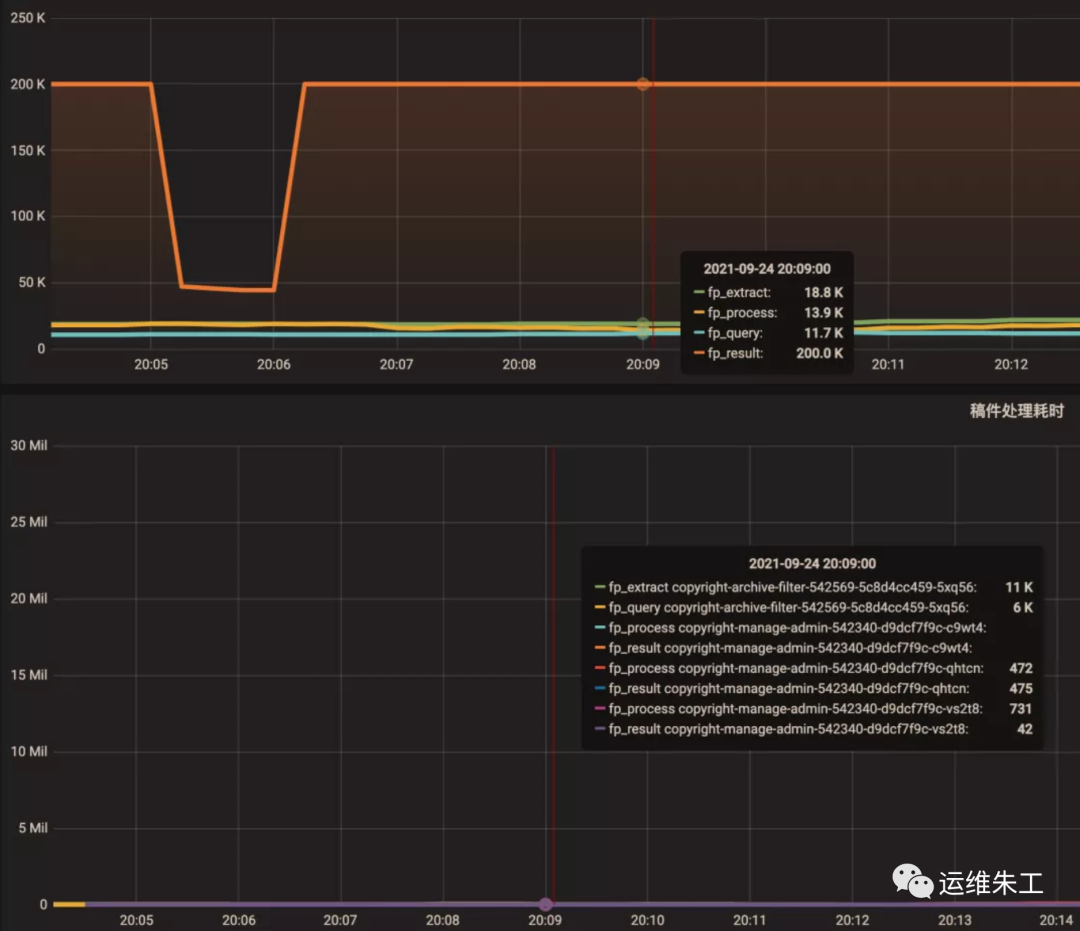
Ajuste la herramienta de visualización de gráficos a Punto de mira compartido e Información sobre herramientas compartida respectivamente para ver el efecto. Se puede ver que la escala se puede mostrar en enlace, lo cual es conveniente para confirmar la correlación entre los dos indicadores al solucionar problemas.
Ajuste la herramienta de visualización de gráficos a Información sobre herramientas compartida:
También podría gustarte: