
Creo que todos los estudiantes han enviado sus currículums en el anzuelo más o menos. Hoy, de repente quiero saber el nivel salarial, los requisitos de contratación, los beneficios y la ubicación de la empresa de desarrollo de Python en Beijing . Dado que se va a analizar, debe ser una muestra de datos existente. ¡Este artículo le muestra el estado actual del desarrollo de Python en Beijing a través del rastreo y el análisis de datos, y espera ayudarlo en la planificación de su carrera! ! !
El primer paso de un rastreador es, naturalmente, comenzar analizando la solicitud y el código fuente de la página web. Desde el código fuente de la página web no podemos encontrar las ofertas de trabajo publicadas. Pero en la solicitud vemos una solicitud POST de este tipo
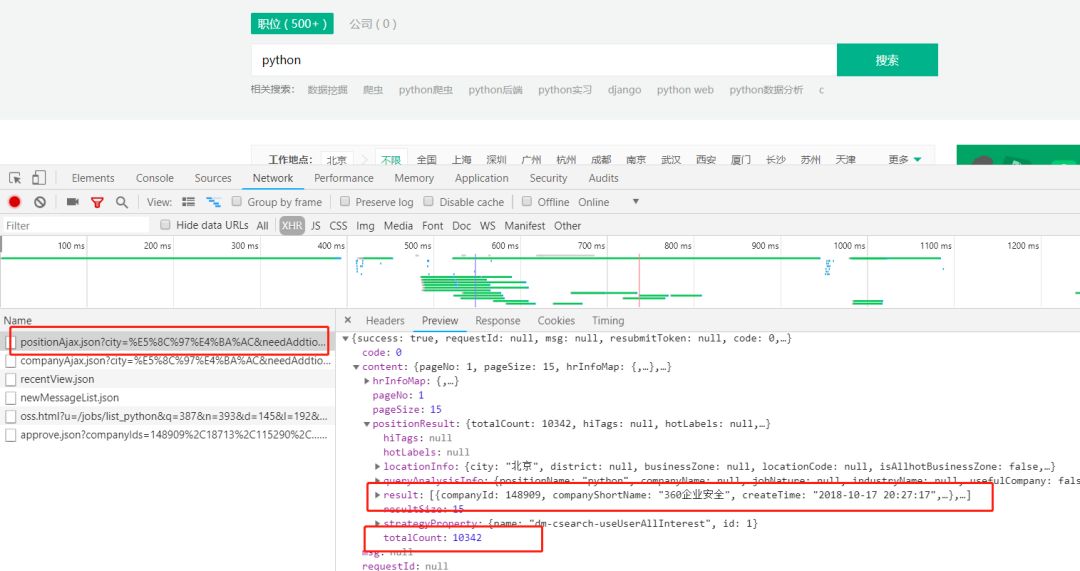
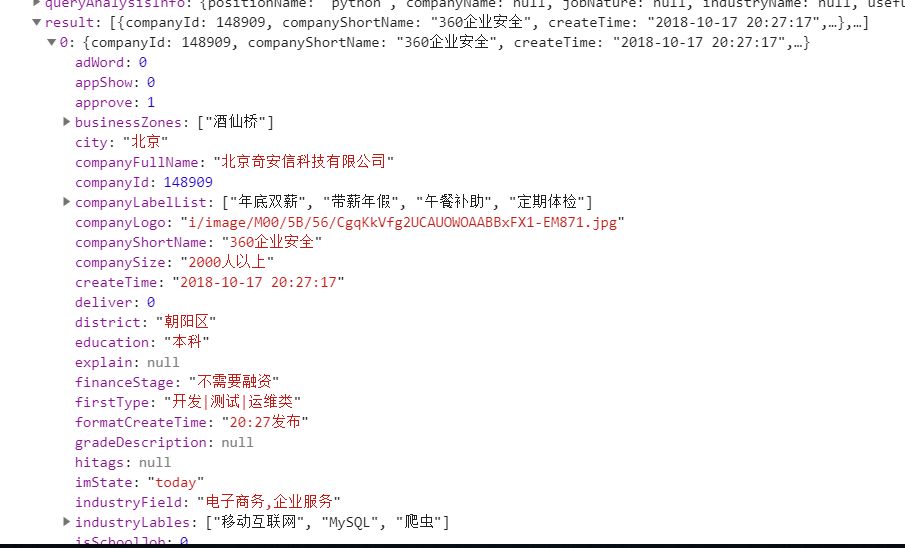
Como se muestra en la siguiente figura, podemos ver que
URL : https://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false
Método de solicitud : publicación
resultado : para las ofertas de trabajo publicadas
totalCount : el número de ofertas de trabajo
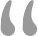
A través de la práctica se encuentra que además de tener que llevar cabeceras, Lagou.com también tiene restricciones en la frecuencia de acceso ip. Al principio, le indicará "acceso demasiado frecuente", y si continúa accediendo, la dirección IP se incluirá en la lista negra. Sin embargo, se eliminará automáticamente de la lista negra después de un período de tiempo.
Para esta estrategia, podemos limitar la frecuencia de las solicitudes, este inconveniente es que afecta la eficiencia del rastreador.
En segundo lugar, también podemos rastrear la IP del proxy. Las IP de proxy gratuitas se pueden encontrar en línea, pero la mayoría de ellas no son estables. El precio pagado no es muy asequible.
Depende de cómo elijas
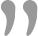
Al analizar la solicitud, encontramos que se devuelven 15 piezas de datos por página, y totalCount nos dice el número total de piezas de información sobre la posición.
Redondea hacia arriba para obtener el número total de páginas. Luego guarde los datos resultantes en un archivo csv. ¡De esta manera obtenemos la fuente de datos para el análisis de datos!
Los datos del formulario de la solicitud posterior pasan tres parámetros
first : Si es la primera página (no muy útil)
pn : número de página
kd : palabra clave de búsqueda
# 获取请求结果
# kind 搜索关键字
# page 页码 默认是1
def get_json(kind, page=1,):
# post请求参数
param = {
'first': 'true',
'pn': page,
'kd': kind
}
header = {
'Host': 'www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
# 设置代理
proxies = [
{'http': '140.143.96.216:80', 'https': '140.143.96.216:80'},
{'http': '119.27.177.169:80', 'https': '119.27.177.169:80'},
{'http': '221.7.255.168:8080', 'https': '221.7.255.168:8080'}
]
# 请求的url
url = 'https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false'
# 使用代理访问
# response = requests.post(url, headers=header, data=param, proxies=random.choices(proxies))
response = requests.post(url, headers=header, data=param, proxies=proxies)
response.encoding = 'utf-8'
if response.status_code == 200:
response = response.json()
# 请求响应中的positionResult 包括查询总数 以及该页的招聘信息(公司名、地址、薪资、福利待遇等...)
return response['content']['positionResult']
return None
A continuación, solo necesitamos llamar a get_json para obtener el resultado de la solicitud después de cada vuelta de página, y luego atravesar y recuperar la información de reclutamiento requerida.
if __name__ == '__main__':
# 默认先查询第一页的数据
kind = 'python'
# 请求一次 获取总条数
position_result = get_json(kind=kind)
# 总条数
total = position_result['totalCount']
print('{}开发职位,招聘信息总共{}条.....'.format(kind, total))
# 每页15条 向上取整 算出总页数
page_total = math.ceil(total/15)
# 所有查询结果
search_job_result = []
#for i in range(1, total + 1)
# 为了节约效率 只爬去前100页的数据
for i in range(1, 100):
position_result = get_json(kind=kind, page= i)
# 每次抓取完成后,暂停一会,防止被服务器拉黑
time.sleep(15)
# 当前页的招聘信息
page_python_job = []
for j in position_result['result']:
python_job = []
# 公司全名
python_job.append(j['companyFullName'])
# 公司简称
python_job.append(j['companyShortName'])
# 公司规模
python_job.append(j['companySize'])
# 融资
python_job.append(j['financeStage'])
# 所属区域
python_job.append(j['district'])
# 职称
python_job.append(j['positionName'])
# 要求工作年限
python_job.append(j['workYear'])
# 招聘学历
python_job.append(j['education'])
# 薪资范围
python_job.append(j['salary'])
# 福利待遇
python_job.append(j['positionAdvantage'])
page_python_job.append(python_job)
# 放入所有的列表中
search_job_result += page_python_job
print('第{}页数据爬取完毕, 目前职位总数:{}'.format(i, len(search_job_result)))
# 每次抓取完成后,暂停一会,防止被服务器拉黑
time.sleep(15)
¡OK! Hemos obtenido los datos, el último paso que necesitamos para guardar los datos
# 将总数据转化为data frame再输出
df = pd.DataFrame(data=search_job_result,
columns=['公司全名', '公司简称', '公司规模', '融资阶段', '区域', '职位名称', '工作经验', '学历要求', '工资', '职位福利'])
df.to_csv('lagou.csv', index=False, encoding='utf-8_sig')
Ejecute el método principal directamente al resultado:
Al analizar el archivo cvs, para facilitar nuestras estadísticas, necesitamos limpiar los datos.
Por ejemplo, se excluye la contratación de puestos de pasantía, no se requieren los años de trabajo o los estudiantes nuevos se tratan como 0 años, el rango salarial debe calcularse como un valor aproximado y no se requiere la formación académica como universidad.
# 读取数据
df = pd.read_csv('lagou.csv', encoding='utf-8')
# 数据清洗,剔除实习岗位
df.drop(df[df['职位名称'].str.contains('实习')].index, inplace=True)
# print(df.describe())
# 由于CSV文件内的数据是字符串形式,先用正则表达式将字符串转化为列表,再取区间的均值
pattern = 'd+'
df['work_year'] = df['工作经验'].str.findall(pattern)
# 数据处理后的工作年限
avg_work_year = []
# 工作年限
for i in df['work_year']:
# 如果工作经验为'不限'或'应届毕业生',那么匹配值为空,工作年限为0
if len(i) == 0:
avg_work_year.append(0)
# 如果匹配值为一个数值,那么返回该数值
elif len(i) == 1:
avg_work_year.append(int(''.join(i)))
# 如果匹配值为一个区间,那么取平均值
else:
num_list = [int(j) for j in i]
avg_year = sum(num_list)/2
avg_work_year.append(avg_year)
df['工作经验'] = avg_work_year
# 将字符串转化为列表,再取区间的前25%,比较贴近现实
df['salary'] = df['工资'].str.findall(pattern)
# 月薪
avg_salary = []
for k in df['salary']:
int_list = [int(n) for n in k]
avg_wage = int_list[0]+(int_list[1]-int_list[0])/4
avg_salary.append(avg_wage)
df['月工资'] = avg_salary
# 将学历不限的职位要求认定为最低学历:大专
df['学历要求'] = df['学历要求'].replace('不限','大专')
Después de que los datos simplemente se limpien, comencemos nuestras estadísticas.
# 绘制频率直方图并保存
plt.hist(df['月工资'])
plt.xlabel('工资 (千元)')
plt.ylabel('频数')
plt.title("工资直方图")
plt.savefig('薪资.jpg')
plt.show()
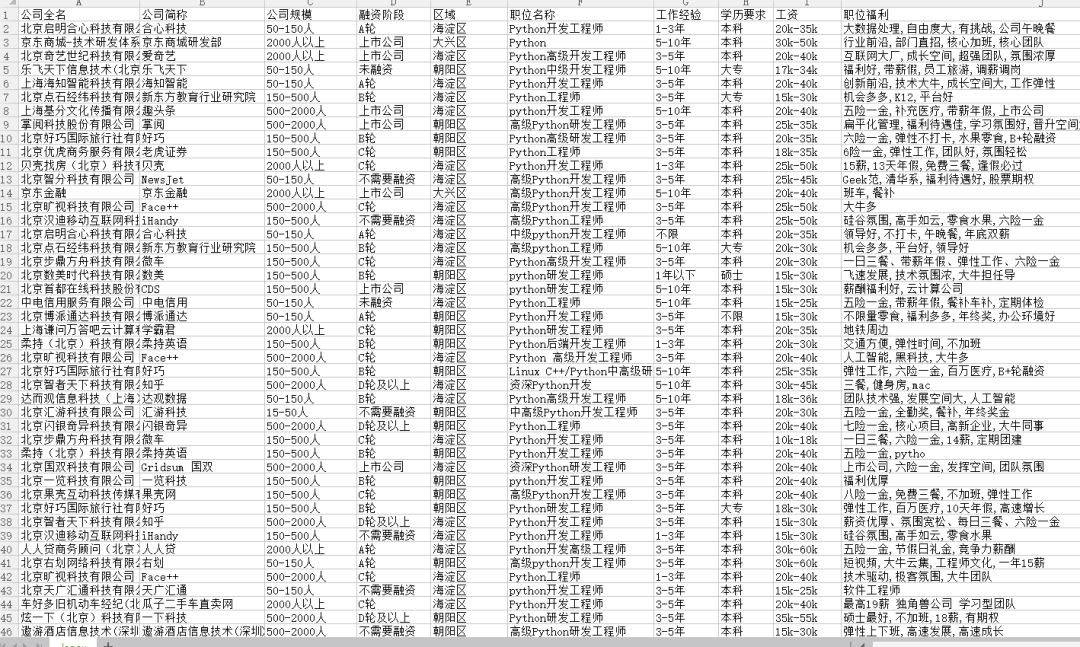
Conclusión: la mayor parte del salario del desarrollo de Python en Beijing está entre 15 y 25 000
# 绘制饼图并保存
count = df['区域'].value_counts()
plt.pie(count, labels = count.keys(),labeldistance=1.4,autopct='%2.1f%%')
plt.axis('equal') # 使饼图为正圆形
plt.legend(loc='upper left', bbox_to_anchor=(-0.1, 1))
plt.savefig('pie_chart.jpg')
plt.show()
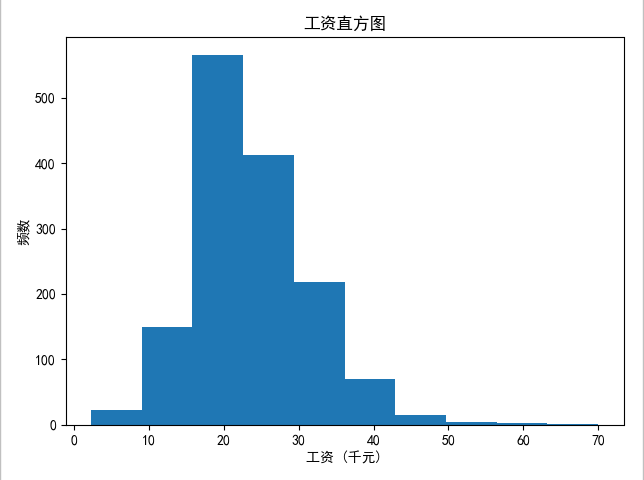
Conclusión: el distrito de Haidian tiene la mayor cantidad de empresas que desarrollan Python, seguido del distrito de Chaoyang. Los amigos que van a trabajar en Beijing probablemente saben dónde alquilar una casa.
# {'本科': 1304, '大专': 94, '硕士': 57, '博士': 1}
dict = {}
for i in df['学历要求']:
if i not in dict.keys():
dict[i] = 0
else:
dict[i] += 1
index = list(dict.keys())
print(index)
num = []
for i in index:
num.append(dict[i])
print(num)
plt.bar(left=index, height=num, width=0.5)
plt.show()
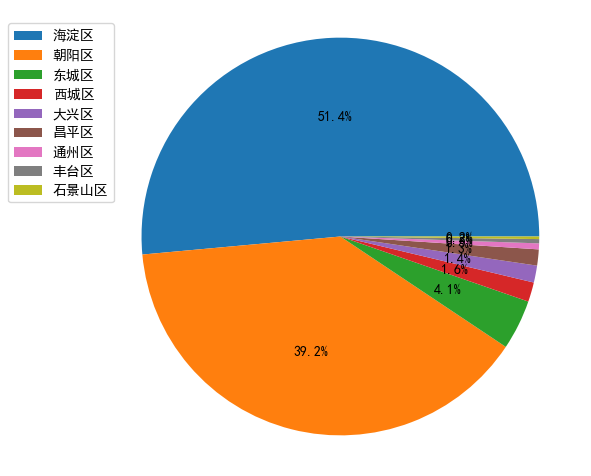
Conclusión: en el reclutamiento de Python, la mayoría de las empresas requieren una licenciatura o superior. Pero la educación es solo un trampolín, si trabajas duro para mejorar tus habilidades, esto no es un problema.
# 绘制词云,将职位福利中的字符串汇总
text = ''
for line in df['职位福利']:
text += line
# 使用jieba模块将字符串分割为单词列表
cut_text = ' '.join(jieba.cut(text))
#color_mask = imread('cloud.jpg') #设置背景图
cloud = WordCloud(
background_color = 'white',
# 对中文操作必须指明字体
font_path='yahei.ttf',
#mask = color_mask,
max_words = 1000,
max_font_size = 100
).generate(cut_text)
# 保存词云图片
cloud.to_file('word_cloud.jpg')
plt.imshow(cloud)
plt.axis('off')
plt.show()

Conclusión: el trabajo flexible es el beneficio de la mayoría de las empresas, seguido de cinco seguros y un fondo de vivienda, y algunas empresas también proporcionarán seis seguros y un fondo de vivienda. El ambiente de equipo y la gestión plana también son aspectos importantes.
Esto concluye el análisis. Los estudiantes que lo necesiten también pueden consultar la información de contratación de otros puestos o regiones ~
Espero que pueda ayudarte a posicionar tu propio desarrollo y planificación de carrera.

Como comunidad tecnológica global descentralizada, la comunidad china de Python tiene la visión de convertirse en una tribu espiritual de 200 000 desarrolladores chinos de Python en todo el mundo. Actualmente cubre las principales plataformas de medios y colaboración, y coopera con Alibaba, Tencent, Baidu, Microsoft, Amazon , fuente abierta China, CSDN y otras empresas conocidas en la industria han establecido amplios contactos con la comunidad técnica, con decenas de miles de miembros registrados de más de diez países y regiones Agencias gubernamentales, instituciones de investigación científica, instituciones financieras y empresas conocidas en el país y en el extranjero, representadas por bancos, la Academia de Ciencias de China, CICC, Huawei, BAT, Google, Microsoft, etc., son seguidas por casi 200,000 desarrolladores en toda la plataforma.
Popular recientemente
Interpretación de datos quién es la diosa en el corazón de los hombres heterosexuales.
El método y la implementación de Python de la evaluación del modelo de clasificación.
Analicé 50.000 artículos en Huxiu.com y encontré estos secretos
Rastreo y analizo Meituan.com, resulta que las 10 mejores delicias en Beijing y Shanghái son ellas.
Correo electrónico de envío: [email protected]

▼ Haga clic a continuación para leer el texto original y convertirse en miembro registrado de la comunidad de forma gratuita