Autor: Aidan Cooper
Compilación del corazón de la máquina
Departamento editorial de Heart of the Machine
Conócelo, conoce por qué.
El campo del aprendizaje automático se ha desarrollado muy rápidamente en los últimos años, pero nuestra comprensión de la teoría del aprendizaje automático aún es muy limitada y los efectos experimentales de algunos modelos incluso superan nuestra comprensión de la teoría básica.
En la actualidad, cada vez más investigadores en el campo comienzan a prestar atención y reflexionar sobre este tema. Recientemente, un científico de datos llamado Aidan Cooper escribió un blog para resolver la relación entre los resultados experimentales del modelo y la teoría subyacente. La siguiente es la publicación original del blog:
En el campo del aprendizaje automático, algunos modelos son muy efectivos, pero no estamos completamente seguros de por qué. Por el contrario, algunas áreas de investigación relativamente bien entendidas tienen una aplicabilidad limitada en la práctica. Este documento explora los avances en varios subcampos basados en la utilidad y la comprensión teórica del aprendizaje automático.
La "utilidad experimental" aquí es una medida compuesta que considera la amplitud de aplicabilidad de un método, qué tan fácil es implementarlo y, lo que es más importante, qué tan útil es en el mundo real. Algunos métodos no solo son prácticos, sino también ampliamente aplicables; otros, aunque poderosos, están limitados a dominios específicos. Se considera que los métodos que son confiables, predecibles y libres de fallas importantes tienen una mayor utilidad.
La llamada comprensión teórica consiste en considerar la interpretabilidad del método del modelo, es decir, cuál es la relación entre la entrada y la salida, cómo se pueden obtener los resultados esperados, cuál es el mecanismo interno de este método y considerar la profundidad. y la integridad de la literatura involucrada en el método.
Los métodos con poca comprensión teórica a menudo usan heurística o ensayo y error extensivo en su implementación; los métodos con alta comprensión teórica tienden a tener implementaciones formuladas con sólidos fundamentos teóricos y resultados predecibles. Los métodos más simples, como la regresión lineal, tienen límites superiores teóricos más bajos, mientras que los métodos más complejos, como el aprendizaje profundo, tienen límites superiores teóricos más altos. Cuando se trata de la profundidad e integridad de la literatura en un campo, el campo se evalúa frente a los límites superiores teóricos asumidos por el campo, que se basa en parte en la intuición.
Podemos construir la matriz de utilidad en cuatro cuadrantes, con la intersección de los ejes representando un campo de referencia hipotético, con comprensión promedio y utilidad promedio. Este enfoque nos permite interpretar los dominios de forma cualitativa según el cuadrante en el que se encuentran, como se muestra en la figura a continuación, los dominios en un cuadrante dado pueden tener algunas o todas las características correspondientes a ese cuadrante.
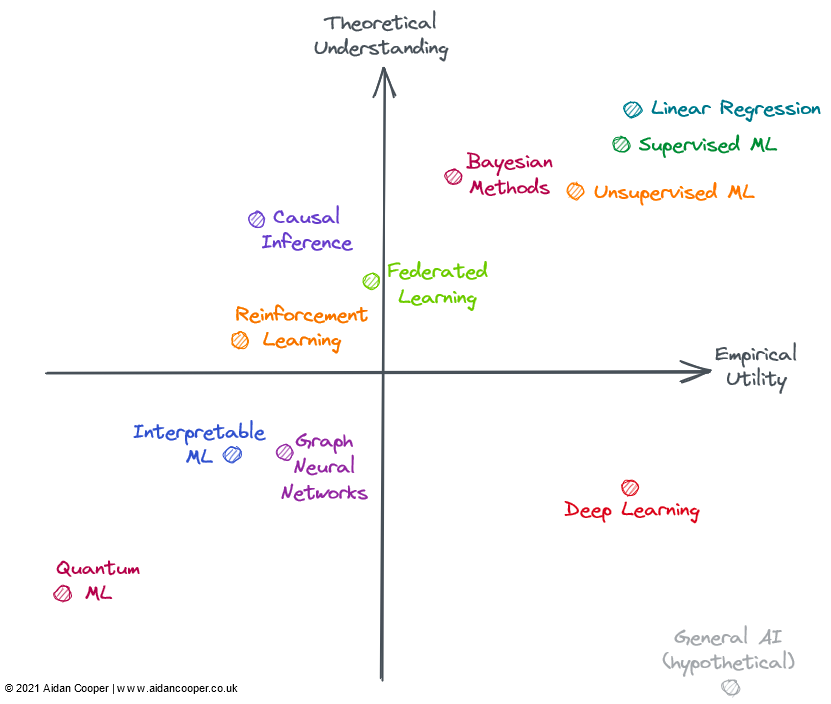
En general, esperamos que la utilidad y la comprensión estén vagamente relacionadas, lo que hace que los métodos con un alto grado de comprensión teórica sean más útiles que aquellos con un bajo grado de comprensión. Esto significa que la mayoría de los campos deben estar en el cuadrante inferior izquierdo o en el cuadrante superior derecho. Lejos de la parte inferior izquierda, el campo diagonal superior derecho representa la excepción. En general, la utilidad práctica debería ir a la zaga de la teoría porque lleva tiempo traducir la teoría de investigación naciente en una aplicación práctica. Entonces esa línea diagonal debe estar sobre el origen, no directamente a través de él.
El campo del aprendizaje automático en 2022
No todos los campos en el diagrama anterior están completamente cubiertos en el aprendizaje automático (ML), pero todos se pueden aplicar en el contexto de ML o estrechamente relacionados con él. Muchos de los dominios evaluados se superponen y no se pueden describir claramente: los métodos avanzados de aprendizaje por refuerzo, aprendizaje federado y aprendizaje automático gráfico a menudo se basan en el aprendizaje profundo. Por lo tanto, considero los aspectos de aprendizaje no profundo de su utilidad teórica y práctica.
Cuadrante superior derecho: alta comprensión, alta utilidad
La regresión lineal es un método simple, fácil de entender y eficiente. Aunque a menudo se subestima y se pasa por alto. , pero su amplitud de uso y fundamentos teóricos completos lo colocan en la esquina superior derecha de la figura.
El aprendizaje automático tradicional se ha convertido en un campo práctico y altamente entendido teóricamente. Se ha demostrado que los algoritmos de aprendizaje automático sofisticados, como los árboles de decisión potenciados por gradiente (GBDT), generalmente superan a la regresión lineal en algunas tareas de predicción complejas. Este es ciertamente el caso con el problema de los grandes datos. Podría decirse que todavía hay lagunas en la comprensión teórica de los modelos sobreparametrizados, pero implementar el aprendizaje automático es un proceso metodológico delicado y, cuando se hace bien, los modelos pueden funcionar de manera confiable dentro de la industria.
Sin embargo, la complejidad y la flexibilidad adicionales generan algunos errores, por lo que puse el aprendizaje automático en el lado izquierdo de la regresión lineal. En general, el aprendizaje automático supervisado es más refinado e impactante que su contraparte no supervisada*, pero ambos enfoques abordan de manera efectiva espacios problemáticos diferentes.
Los métodos bayesianos tienen un culto de practicantes que promocionan su superioridad sobre los métodos estadísticos clásicos más populares. Los modelos bayesianos son particularmente útiles en ciertas situaciones: cuando las estimaciones puntuales por sí solas no son suficientes y las estimaciones de incertidumbre son importantes; cuando los datos son limitados o faltan muchos; y cuando comprende el proceso de generación de datos que desea incluir explícitamente en su modelo Tiempo. La utilidad de los modelos bayesianos está limitada por el hecho de que, para muchos problemas, las estimaciones puntuales son lo suficientemente buenas y las personas simplemente usan métodos no bayesianos por defecto. Más importante aún, hay formas de cuantificar la incertidumbre en el ML tradicional (solo se usan rara vez). A menudo, es más fácil simplemente aplicar algoritmos de ML a los datos, sin tener que pensar en mecanismos y antecedentes de generación de datos. Los modelos bayesianos también son computacionalmente costosos y serían más prácticos si los avances teóricos condujeran a mejores métodos de muestreo y aproximación.
Cuadrante inferior derecho: baja comprensión, alta utilidad
Contrariamente al progreso en la mayoría de los campos, el aprendizaje profundo ha tenido algunos éxitos sorprendentes, aunque el lado teórico ha demostrado ser fundamentalmente difícil de lograr. El aprendizaje profundo incorpora muchas de las características de un enfoque menos conocido: los modelos son inestables, difíciles de construir de manera confiable, se configuran en función de heurísticas débiles y producen resultados impredecibles. Las prácticas cuestionables, como el "ajuste" aleatorio de semillas, son muy comunes y la mecánica de los modelos de trabajo es difícil de explicar. Sin embargo, el aprendizaje profundo continúa avanzando y logrando niveles de rendimiento sobrehumanos en campos como la visión por computadora y el procesamiento del lenguaje natural, abriendo un mundo lleno de tareas que de otro modo serían incomprensibles, como la conducción autónoma.
Hipotéticamente, la IA general ocupará la esquina inferior derecha porque, por definición, la superinteligencia está más allá de la comprensión humana y puede usarse para resolver cualquier problema. Actualmente, solo se incluye como un experimento mental.
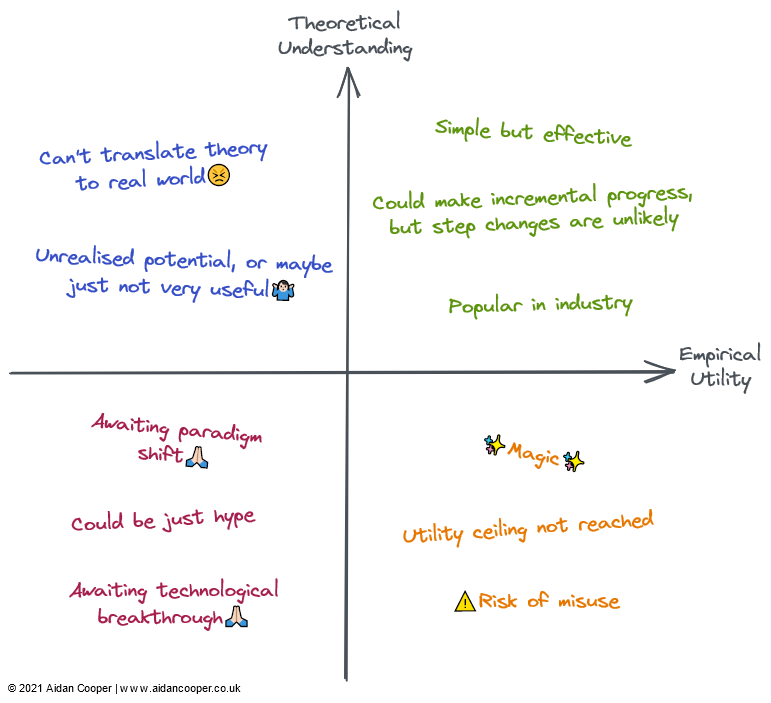
Una descripción cualitativa de cada cuadrante. Los campos pueden ser descritos por algunas o todas sus descripciones en sus áreas correspondientes
Cuadrante superior izquierdo: alta comprensión, baja utilidad
La mayoría de las formas de inferencia causal no son aprendizaje automático, pero a veces lo son y siempre son de interés para los modelos predictivos. La causalidad se puede dividir en ensayos controlados aleatorios (ECA) y métodos más sofisticados de inferencia causal, que intentan medir la causalidad a partir de datos observacionales. Los ECA son simples en teoría y brindan resultados rigurosos, pero a menudo son costosos y poco prácticos, si no imposibles, de realizar en el mundo real y, por lo tanto, tienen una utilidad limitada. Los métodos de inferencia causal esencialmente imitan los RCT sin hacer nada, lo que los hace mucho menos difíciles de realizar, pero tiene muchas limitaciones y escollos que pueden invalidar los resultados. En general, la causalidad sigue siendo una búsqueda frustrante, donde los enfoques actuales a menudo no logran responder las preguntas que queremos hacer, a menos que puedan explorarse a través de ensayos controlados aleatorios, o que encajen en ciertos marcos (por ejemplo, como resultado accidental de un " experimento natural").
El aprendizaje federado (FL) es un concepto genial que ha recibido poca atención, probablemente porque su aplicación más convincente debe distribuirse a una gran cantidad de dispositivos de teléfonos inteligentes, por lo que solo dos jugadores realmente estudian FL: Apple y Google. Existen otros casos de uso para FL, como la agrupación de conjuntos de datos patentados, pero existen desafíos políticos y logísticos en la coordinación de estas iniciativas, lo que limita su utilidad en la práctica. No obstante, por lo que suena como un concepto elegante (resumido más o menos como: "Acerque el modelo a los datos, no los datos al modelo"), FL es válido y tiene aplicaciones en áreas como la predicción de texto del teclado y la recomendación personalizada de noticias. Historias prácticas de éxito: La teoría y las técnicas básicas detrás de FL parecen ser suficientes para que FL se use más ampliamente.
El aprendizaje por refuerzo (RL) ha alcanzado niveles de competencia sin precedentes en juegos como el ajedrez, el Go, el póquer y el DotA. Pero fuera de los videojuegos y los entornos de simulación, el aprendizaje por refuerzo aún tiene que traducirse de manera convincente a las aplicaciones del mundo real. Se suponía que la robótica sería la próxima frontera de RL, pero no fue así: la realidad parecía más desafiante que el entorno de juguete altamente restringido. Dicho esto, los logros de RL hasta ahora son inspiradores, y alguien que realmente disfruta del ajedrez podría pensar que su utilidad debería ser mayor. Me gustaría ver que RL se dé cuenta de algunas de sus posibles aplicaciones prácticas antes de colocarlo en el lado derecho de la matriz.
Cuadrante inferior izquierdo: baja comprensión, baja utilidad
Graph Neural Networks (GNN) es ahora un campo muy candente en el aprendizaje automático, con resultados prometedores en múltiples campos. Pero para muchos de estos ejemplos, no está claro si las GNN son mejores que las alternativas que usan datos estructurados más tradicionales combinados con arquitecturas de aprendizaje profundo. Los datos que tienen una estructura gráfica natural, como las moléculas en la quimioinformática, parecen tener resultados GNN más convincentes (aunque estos generalmente no son tan buenos como los métodos no relacionados con gráficos). En comparación con la mayoría de los campos, parece haber una gran diferencia entre las herramientas de código abierto utilizadas para entrenar GNN a escala y las herramientas internas utilizadas en la industria, lo que limita la viabilidad de grandes GNN fuera de estos jardines amurallados. La complejidad y la amplitud del campo sugieren un límite superior teórico alto, por lo que las GNN deberían tener espacio para madurar y demostrar de manera convincente las ventajas para ciertas tareas, lo que conducirá a una mayor utilidad. Los GNN también pueden beneficiarse de los avances tecnológicos, ya que los gráficos actualmente no se adaptan naturalmente al hardware informático existente.
El aprendizaje automático interpretable (IML) es un campo importante y prometedor y continúa recibiendo atención. Técnicas como SHAP y LIME se han convertido en herramientas realmente útiles para interrogar modelos ML. Sin embargo, debido a la adopción limitada, la utilidad de los enfoques existentes aún no se ha realizado por completo: no se han establecido mejores prácticas sólidas ni pautas de implementación. Sin embargo, la principal debilidad actual de IML es que no aborda los problemas causales que realmente nos interesan. IML explica cómo el modelo hace predicciones, pero no cómo los datos subyacentes se relacionan causalmente con ellos (aunque a menudo se malinterpretan así). Hasta que se logre un progreso teórico significativo, los usos legítimos de IML se limitan principalmente a la depuración/supervisión de modelos y la generación de hipótesis.
Quantum Machine Learning (QML) está mucho más allá de mi timonera, pero actualmente parece ser un ejercicio hipotético, esperando pacientemente a que una computadora cuántica viable esté disponible. Hasta entonces, QML se sentaba trivialmente en la esquina inferior izquierda.
Avances incrementales, saltos tecnológicos y cambios de paradigma
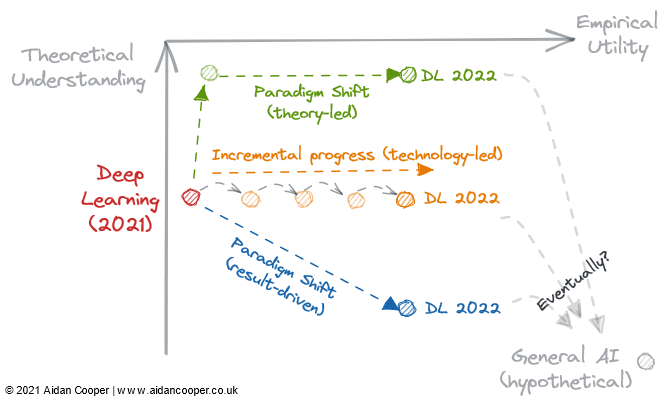
Hay tres mecanismos principales por los cuales el campo atraviesa la comprensión teórica y la matriz de utilidad empírica (Figura 2).
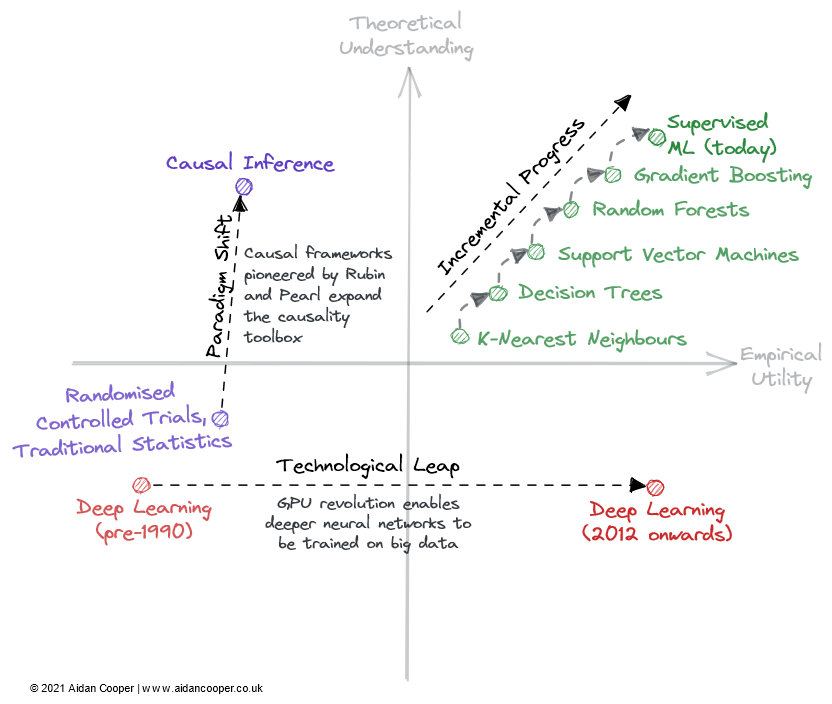
Un ejemplo ilustrativo de cómo los campos pueden atravesar una matriz.
El progreso incremental es un progreso lento y constante que mueve el campo hacia arriba en pulgadas en el lado derecho de la matriz. El aprendizaje automático supervisado de las últimas décadas es un buen ejemplo, durante el cual se refinaron y adoptaron algoritmos de predicción cada vez más eficientes, brindándonos la poderosa caja de herramientas que amamos hoy. El progreso incremental es el statu quo en todos los campos maduros, excepto en los períodos de mayor movimiento debido a los saltos tecnológicos y los cambios de paradigma.
Algunos campos han visto cambios drásticos en el progreso científico debido a avances tecnológicos. El campo del *aprendizaje profundo* no se desentraña por sus fundamentos teóricos, que se descubrieron más de 20 años antes del auge del aprendizaje profundo de la década de 2010: fue el procesamiento paralelo impulsado por GPU de nivel de consumidor lo que impulsó su renacimiento. Los saltos tecnológicos suelen aparecer como saltos hacia la derecha a lo largo del eje de la utilidad empírica. Sin embargo, no todos los avances tecnológicos son saltos. En la actualidad, el aprendizaje profundo se caracteriza por un progreso incremental al entrenar modelos cada vez más grandes utilizando más potencia informática y hardware cada vez más especializado.
El último mecanismo para el progreso científico dentro de este marco es el cambio de paradigma. Como señala Thomas Kuhn en su libro La estructura de las revoluciones científicas, los cambios de paradigma representan cambios importantes en los conceptos fundamentales y las prácticas experimentales de las disciplinas científicas. Un ejemplo de ello es el marco causal iniciado por Donald Rubin y Judea Pearl, que eleva el campo de la causalidad de los ensayos controlados aleatorios y el análisis estadístico tradicional a una disciplina matemática más poderosa en forma de inferencia causal. Los cambios de paradigma a menudo se manifiestan como movimientos ascendentes en la comprensión, que pueden seguir o ir acompañados de una mayor utilidad.
Sin embargo, el cambio de paradigma puede atravesar la matriz en cualquier dirección. Cuando las redes neuronales (y, posteriormente, las redes neuronales profundas) se establecieron como un paradigma separado del aprendizaje automático tradicional, esto inicialmente correspondió a una disminución de la utilidad y la comprensión. Muchos campos emergentes se separaron de áreas de investigación más establecidas de esta manera.
La revolución científica en predicción y aprendizaje profundo
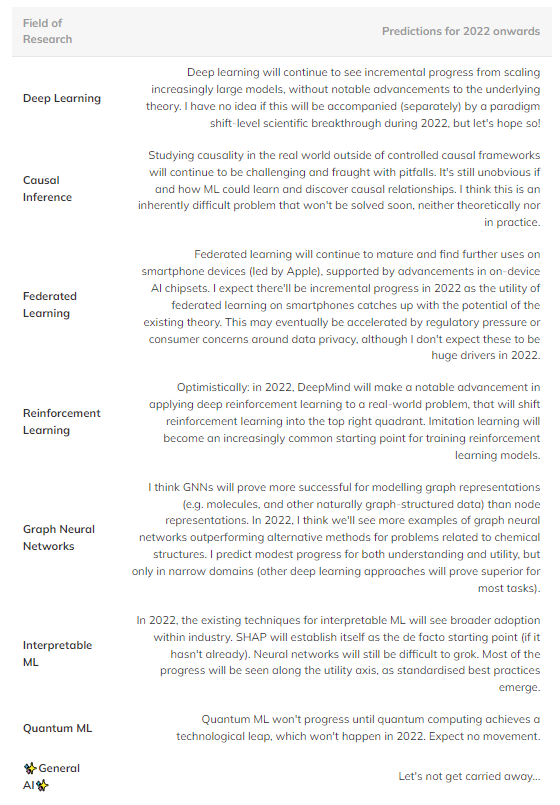
En resumen, aquí hay algunas predicciones especulativas que creo que pueden suceder en el futuro (Tabla 1). Los campos en el cuadrante superior derecho se omiten porque son demasiado maduros para ver un progreso significativo.
Tabla 1: Predicción del progreso futuro en varios campos importantes del aprendizaje automático.
Sin embargo, las observaciones que son más importantes que cómo se desarrollan los campos individuales son una tendencia general en el empirismo y una creciente disposición a admitir una comprensión teórica integral.
Históricamente, las teorías (hipótesis) generalmente aparecen primero y luego se formulan las ideas. Pero el aprendizaje profundo ha dado paso a un nuevo proceso científico que le da la vuelta a esto. Dicho esto, se espera que los métodos demuestren un rendimiento de vanguardia mucho antes de que las personas se concentren en la teoría. Los resultados empíricos son rey, la teoría es opcional.
Esto ha llevado a un amplio juego de sistemas en la investigación del aprendizaje automático, lo que ha dado como resultado resultados de última generación simplemente modificando los métodos existentes y confiando en la aleatoriedad para superar las líneas de base, en lugar de avanzar significativamente en la teoría del campo. Pero tal vez ese sea el precio que estamos pagando por una nueva ola de auges de aprendizaje automático.
Figura 3: 3 posibles trayectorias de desarrollo del aprendizaje profundo en 2022.
2022 podría ser el punto de inflexión si el aprendizaje profundo es irreversiblemente un proceso orientado a resultados y relega la comprensión teórica a opcional. Deberíamos considerar las siguientes preguntas:
¿Permitirán los avances teóricos que nuestra comprensión alcance la practicidad y transforme el aprendizaje profundo en una disciplina más estructurada como el aprendizaje automático tradicional?
¿La literatura de aprendizaje profundo existente es suficiente para que la utilidad aumente indefinidamente, simplemente escalando modelos cada vez más grandes?
¿O un avance empírico nos llevará más abajo en la madriguera del conejo hacia un nuevo paradigma de utilidad mejorada, aunque sepamos menos al respecto?
¿Alguna de estas rutas conduce a la inteligencia artificial general? Sólo el tiempo dirá.
Enlace original: https://www.aidancooper.co.uk/utility-vs-understanding/?continueFlag=b96fa8ed72dfc82b777e51b7e954c7dc

© EL FIN
Para reimprimir, comuníquese con esta cuenta oficial para obtener autorización.
Contribuya o busque cobertura: [email protected]